published quarterly by the university of borås, sweden
vol. 24 no. 4, December, 2019
Introduction. In this study we compare the IFLA Library Reference Model and the Library of Congress Bibliographic Framework model and identify characteristics that affect their usability in bibliographic end user search.
Method. A source collection of bibliographic records is used to generate comparable test collections implementing each of the models. Keyword based search is implemented for each test collection, using bag of words extraction of subgraphs for work entities.
Analysis. The generated collection is analysed, and major differences are described and discussed. A set of queries and result metrics is used to identify and describe how the models perform with respect to search and interactivity.
Results. A test collection and a framework for evaluating library information models. The models produce approximately the same number of entities but differ in their ability to connect and relate entities.
Conclusions. Findings show that the BIBFRAME model tends to reflect and express the same entity structure as the LRM model but does not provide the same consistency and simplicity in interlinking and grouping of intellectual products that can be achieved with the entities in the LRM model. BIBFRAME result sets are generally longer, whereas LRM result list are compact and may show very big differences in the size of the publications they cluster.
The model of bibliographic entities and relationships that was published in IFLA’s Functional Requirements for Bibliographic Records over two decades ago (IFLA, 1998), introduced a new view and understanding of bibliographic information based on the core entities of work, expression, manifestation and item (WEMI). This model is the conceptual framework behind a new generation of cataloguing standards and practises (including RDA), and a new and revised version of the model has recently been published as the IFLA Library Reference Model – LRM (Riva et al, 2017). In the same period, the library community has been introduced to the Bibliographic Framework model (BIBFRAME) developed for the Library of Congress, which intends to bridge the old and new by maintaining much of the same conceptual structures found in existing library data and practices. BIBFRAME defines the three entities of Work, Instance and Item and depicts a different view on the bibliographic universe. With a worldwide community in the process of adopting new practises and formats, developing search and exploration tools for the generation of digital natives, struggling to meet expectations for open linked data that adds value in a broader context, it is crucial to have solid knowledge about the impact of information model decisions on users search experience as well as for reuse and compatibility. The latter aspects tend to dominate the general discussion and research, and there is a lack of knowledge and discussion about how models impact the design of systems and consequently the usability and search experience for end users.
In this study we compare the core structures of entities and relationships that can be found in data modelled according to the Library Reference Model (LRM) and the Bibliographic Framework (BIBFRAME). The analysis is based on a realistic and high-quality collection for each of the models created by transforming an elaborated set of MARC records harvested from four European national library catalogues. Our research is design science oriented and we use prototyping of collections and systems combined with various formal and informal ways to analyse the effect of information models. The overall objective is to identify how models differ in terms of user experience. This is knowledge that will support decision makers in the process of choosing the conceptual foundation for future library data. Our study shows that there are clear differences between data produced in accordance with the two models, which again affects how search systems can organize and present information to users.
IFLA Library Reference Model (LRM) and Library of Congress Bibliographic Framework model are both intended to be the foundation for efforts in modernizing library catalogues and practises. The initial development of LRM (its ancestor FRBR) dates back to a time before the semantic web and uses the method and formalisms of Entity Relationship modelling. It is currently only available as a reference document with elaborated definitions and well-defined constraints. The revised LRM version makes use of inheritance and is more adopted to a semantic web environment. BIBFRAME, on the other hand, is developed in the context of the semantic web as expressed in the description of the model: ‘BIBFRAME (Bibliographic Framework) is an initiative to evolve bibliographic description standards to a linked data model’ (Library of Congress, 2016). The formalisms in BIBFRAME are partly expressed in the web pages documenting the model but formal definition of types and constraints (such as domain and range) are found in the RDFS/OWL declaration. One good reason that many library developers are looking into BIBFRAME is the existence of a formal and ready to be used schema, something that is not currently existing for LRM. Figure 1 shows the core classes in each model with arrows for the main connection (relationships). Entities can additionally be related in many other ways using various relationship types.
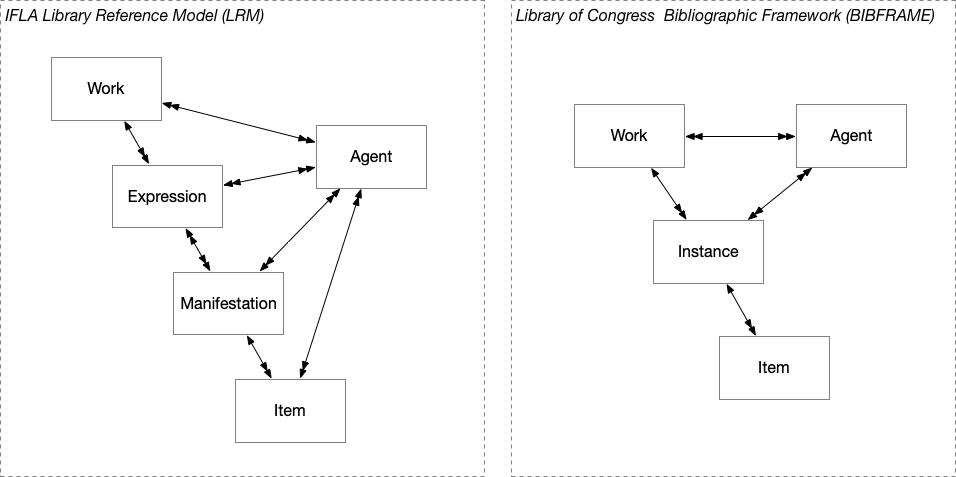
Both models enable hierarchical grouping of bibliographic resources with work representing the intellectual and artistic contribution at the highest level of abstraction. This was early recognized as one of the key contributions of FRBR and is the basis for how the model is envisioned to impact user interfaces (Aalberg 2002, Hegna & Murtomaa 2003, Yee 2005, Ercegovac 2006, Smiraglia 2007). In LRM the work will group expressions which further represents a grouping of the manifestations they are embodied in. In BIBFRAME the grouping is created by a work having multiple instances. Another main distinction between the model can be found in the way BIBFRAME works and instances are connected versus how LRM connects expressions and manifestations. In BIBFRAME each instance is considered to be the instantiation of one work, whereas in LRM a manifestation can embody multiple expressions. This implies that LRM enables an explicit distinction between the publication as a carrier and its contents – expressed with a manifestation or instance entity that embodies one or more expressions. The same structure needs to be expressed using part of relationships between works in BIBFRAME.
In summary, the two models facilitate representation of bibliographic information but by using different structures which also creates significant differences in how users can interact with and explore the data. The BIBFRAME Work view is somewhat comparable to the LRM Expression view, but users typically need more horizontal navigations to examine data. Our research shows that there is a significant difference between the models that library professionals and library system developers must consider wisely.
Research related to bibliographic models have to a large degree focused on case studies of small examples, transformations of legacy MARC data, dissemination as linked open data and publicly available unique identifiers for the entities of concern. Some experiments and prototypes on user interfaces can be found but suffer from partial implementations or low-quality data not reflecting the relevant structures.
LRM and BIBFRAME has been investigated from different perspectives and with different methods. Although the development process of emerging models has been accused for lacking a substantial user orientation, usability perspectives has become a popular topic in recent years. Some user-oriented studies let users test modelling principles indirectly through card sorting and concept mapping (Pisanski & Žumer, 2010a, 2010b, Tallerås, Dahl & Pharo, 2018). Other studies are testing modelling principles through user interactions directly with prototype interfaces (Merčun, Žumer & Aalberg, 2012, 2016 & 2017, Aalberg 2017). These studies typically reveal a user preference for a Work entity, but none of them have compared different ways of modelling and implementing the Work concept. Studies that do compare and evaluate models and implementations also exist such as Rico et al. (2019), but most research reports on mappings and crosswalks between models developed and analysed by experts. Researchers at OCLC has for example been mapping BIBFRAME and schema.org (Godby & Denenberg, 2015), while Taniguchi (2018) and Zapounidou, Sfakakis and Papatheodorou (2017a, 2017b & 2019) have mapped LRM and BIBFRAME relationships. A third perspective in bibliographic research is to examine conformance to defined quality criteria. Such studies include actual instance data and measure how complete, consistent or accurate a given knowledge base is, or to what degree it conforms to a set of best practice principles (for example in the case of Linked data principles (e.g. Tallerås, 2017). Mapping studies and quality criteria have their main focus on the models and practical implementation rather than user perspectives. In this study we show how these traditions can be combined by comparing implementations of two models in a search prototype.
The initial part of this research was to create a test collection to be used as common source for creating alternative representations based on respectively LRM and BIBFRAME. Approximately 10.000 MARC21 records for five authors was initially retrieved from the national library catalogues of Norway, Germany, UK and Spain using Z39.50 and SRU. Records were retrieved by performing author and subject search. The set includes one subset of the records mentioning Arthur Conan Doyle – the author of Sherlock Holmes stories but also an author of many other works. This sub collection is characterized by a large number of derivative works such as cartoons, children’s books, tv-series and movies, as well as various compilations of the short stories. The other four authors are selected from the list of Nobel laureates with major works in the form of novels, one author from each of the selected countries: Günter Grass (Germany), Knut Hamsun (Norway), William Golding (UK) and Camilo José Cela (Spain). This selection is motivated by the need to have a controlled set of translated titles to be able to identify same work correctly. Records tagged with other languages were excluded from the final set. The selection includes records describing novels, poem collections, plays and short stories – and includes many translations and adaptations such as dramatizations for stage and film. The works of these authors are additionally frequently found as subject entries and referred in other ways in added entries.
The next stage in building the test collection was to create an authority file to assist in the work and author identification. An initial set of titles in the different languages for each author was retrieved from Wikipedia pages and supplied with additional titles found in VIAF and Wikidata. An iterative process of identifying works in the records was conducted which included the extraction of titles and names that did not match existing entries in the authority file. Alternative titles to existing work entries were added to the authority file and new entries were added if the title was identified as a new work. The creation of the authority file was semi-automatically and performed iteratively until approximately 50% coverage was reached. The remaining records either did not distinctively identify or describe a work by any of the selected authors or the record represented a resource that is rarely republished or referred to and were excluded. The result is a set of records where all works and names unambiguously can be mapped to an already established global identifier or an identifier that is constructed for internal use. By ‘works’ in this context we mean literary products that already have an established identity through references on Wikipedia, other encyclopaedia or authorized source. Final size of the collection and its sub parts is presented Table 1.
| Author | NB (nor) | DNB (ger) | BNE (spa) | BL (eng) | _All_ |
|---|---|---|---|---|---|
| Doyle, Arthur Conan | 73 | 578 | 608 | 661 | _1,920_ |
| Grass, Günter | 27 | 881 | 115 | 107 | _1,130_ |
| Golding, William | 16 | 132 | 67 | 126 | _341_ |
| Hamsun, Knut | 693 | 266 | 141 | 10 | _1,110_ |
| Cela, Camilo José | 3 | 38 | 742 | 82 | _865_ |
| _Total_ | _812_ | _1,895_ | _1,673_ | _986_ | **_5,366_** |
The different catalogues used as source for the record have highly different practices in how the content and contributions are described including variable use of the uniform title field and what field that was used to record original titles, description of content parts (analytical entries) and other added entry fields, often inconsistent use of indicators to tag analytical entries, lack of relator codes describing the role of persons and use of codes for languages and codes for types. The collection was manually and semi automatically elaborated upon to create consistent representation of the core structures typically represented in the collection. Additional entries were only added in a few cases and the majority of information added was to enhance the precision of existing description. For records describing a publication reflecting a single work by one of the authors, entries in the MARC fields 100 (main entry for personal name) and 240 (uniform title) were used with additional authors as added entries in 700 fields (provide additional access to names and titles). For records describing collections where the whole and each part are considered to be known works by the author (such as a trilogy), the whole was described using 100 and 240 entries and each contained part using 700 added entries. For collections where the compilation was not intended by the original author of the parts, only 700 entries were used. For movies and other works without a natural main responsibility, the established practice of recording the title in the 130 fields was used. Translations were marked with the language code in a subfield ($l) of either 130 (main entry for uniform title), 240 or 700 fields. Publication in the language considered to be the originating version of a work do not have a $l field. A large number of relator codes were added using a semiautomatic technique that extracted codes used for specific persons and created a mapping which then could be used to fill in missing codes. Finally, we added and enriched existing references to other works by coding the relationship type in subfield 4 using types from the RDA registry. The majority of structure is however based on relationships that can be inferred from the use of fields such as translations, analytical and subject entries. A summary of the collection is presented in Table 2. The collection and processing stylesheets are available online .
| Relationship type | usage |
|---|---|
| http://rdaregistry.info/Elements/w/adaptationOfWork.en | 100 fields |
| http://rdaregistry.info/Elements/w/motionPictureAdaptationOfWork.en | 33 fields |
| http://rdaregistry.info/Elements/w/dramatizationOfWork.en | 13 fields |
| http://rdaregistry.info/Elements/w/guideToWork.en | 12 fields |
| http://rdaregistry.info/Elements/w/graphicNovelizationOfWork.en | 12 fields |
| http://rdaregistry.info/Elements/w/commentaryOnWork.en | 8 fields |
| http://rdaregistry.info/Elements/w/basedOnWork.en | 7 fields |
| http://rdaregistry.info/Elements/w/partOfWork.en | 6 fields |
| http://rdaregistry.info/Elements/w/critiqueOfWork.en | 5 fields |
| http://rdaregistry.info/Elements/w/inspiredBy.en | 5 fields |
| http://rdaregistry.info/Elements/w/precededByWork.en | 2 fields |
| Use of 240 fields | 4,999 fields |
| Use of 700 fields | 3,884 fields |
| Analytical entries (700 ind 2 = 2 and having $t) | 732 fields |
| Aggregations with 240 + 700 entries | 7 records |
| Aggregations without 240 but having 700-entries | 266 records |
| Added entries for persons | 2,949 fields |
| Use of $l in 240 and 700 (indicating translation) | 2,643 fields |
Our conversions into LRM and BIBFRAME is developed using a rule-based system for transformation of MARC records that is easily adaptable to different cataloguing practises and different output formats (Aalberg, 2006) and is able to extract all structures that can be identified in bibliographic MARC records as defined in Aalberg et al. (2018). Rules for how to interpret the records are described in a structured XML-file and used to create a conversion XSLT stylesheet for processing the records. Output is deduplicated entities in RDF with class and property types as defined in the rules. For the LRM representation of the data we are using the RDA registry vocabulary. For BIBFRAME we are using the core classes and relationships from the BIBFRAME vocabulary, but we keep the RDA relationship types for descriptive elements and work-person relationships as well as work-work relationships. The main motivation for this decision is to create collections that differ in the core structuring but otherwise are comparable and can be used in the same search prototype.
When generating LRM entities we create individual works, corresponding expressions and the relationship between them from MARC fields 130, 240 and 700. Added entries for persons are considered to be related to all identified entities for which the relator code type wise applies and the relator code is used to decide the relationship type. Works and persons are identified by the URI in subfield 1 – for 700 entries the existence of subfield t indicates whether the identifier is for work or person. Expressions are identified by adding content type, language code and the sorted sequence of related persons (such as translator or narrator). For expressions identified from 240 or 700 we establish an embodied in relationship to the manifestation that is identified for each record. For related works reference by 700 field and subject entries for person or work in 600 fields, we create a representation of the target work and the corresponding relationship.
There are less best practise rules for generating BIBFRAME entities available, but our interpretation is mainly based on the conversion specifications and marc2bibframe conversion tool provided by the Library of Congress (https://www.loc.gov/bibframe/mtbf/). Given the rather vague definition of the identity criteria for BIBFRAME works we have designed two alternative conversions. One is coined strict and is intended to result in a minimal creation of works, the other is called full and will give a larger number of works. In the strict conversion, one work is always created for the publication as a whole, using the identifier found in 240 or 130 fields in combination with language code. If these fields do not exist in the record, a local identifier is constructed from key information. Any analytical entries are considered to have a part of relationship to the main work and related added entries and subject entries are all associated with the main entity. The full conversion follows the same pattern but additionally we create entities representing the ‘original’ work and add a translation relationship. This is performed for both 240 and 700 analytical entries. Persons having creator or author relationships are related to the original work as well as the main work for the record and equivalent connections are created for related works and subject entries.
Transformations are performed using the eXist-db XML database and visualizations are used both to identify errors in and to illustrate the results. The resulting RDF is imported into a graphDB triple store, where we have defined Lucene connectors for full text indexing of subgraphs having the works as a centroid. This is an established approach for fulltext indexing of RDF data based on the identification of subgraphs of triples that describes an entity and the extraction of a bag of words used as an entity representation in full text search engines. The property paths for the indexing are illustrated in Figure 2. The actual values used to create a document representation are the literal values for titles and names. In this research we have only investigated work-centric structuring of the data.
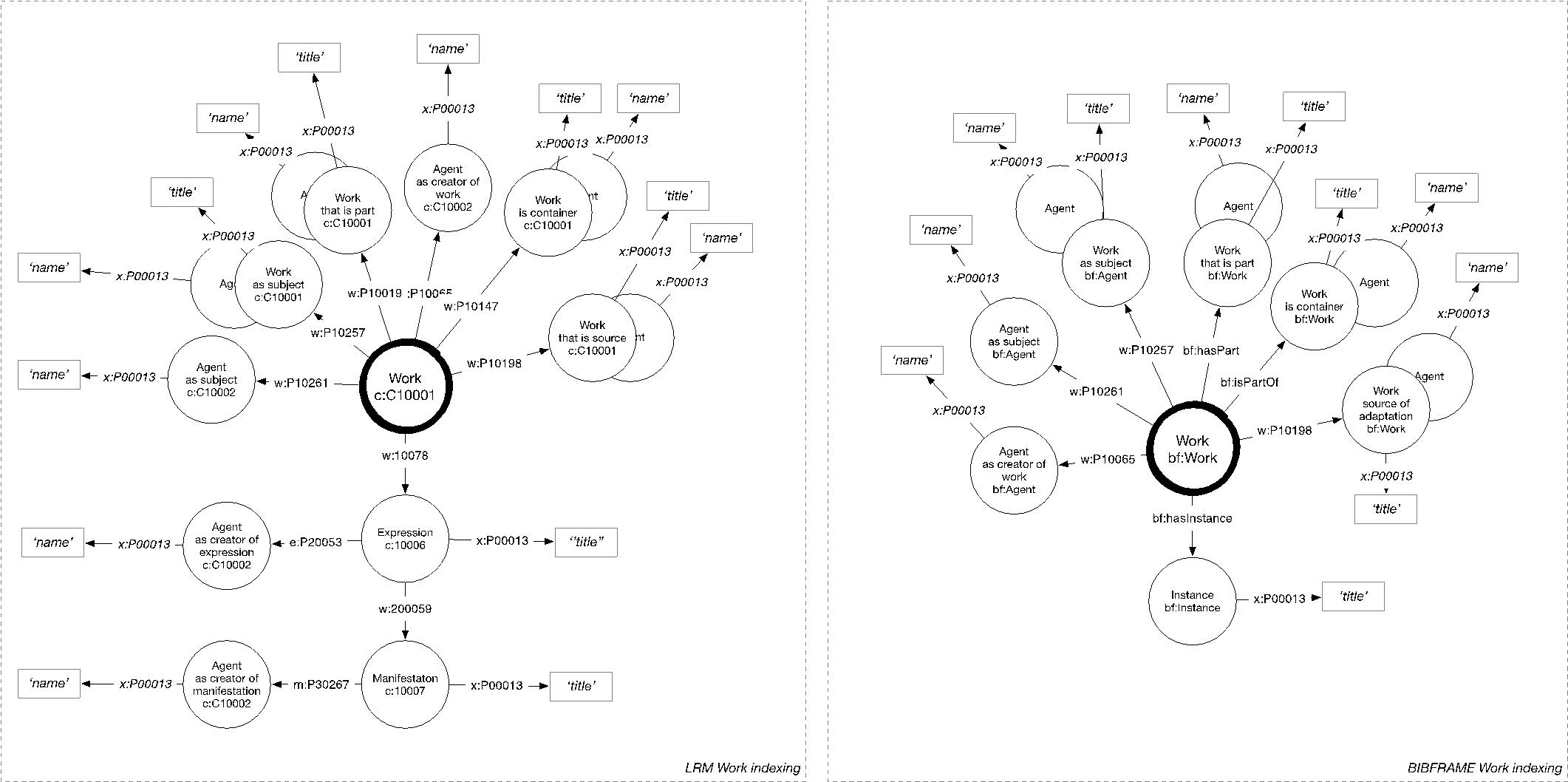
For each RDF set (BIBFRAME strict, BIBFRAME full and LRM) we performed three test queries that are representative for known-item searches typically performed in bibliographic systems:
For each search we harvested the full result list of work, their individual Lucene score together with related manifestation/instances. The score was eventually slightly adjusted by boosting works according to their number of related manifestations/instances (cluster size).
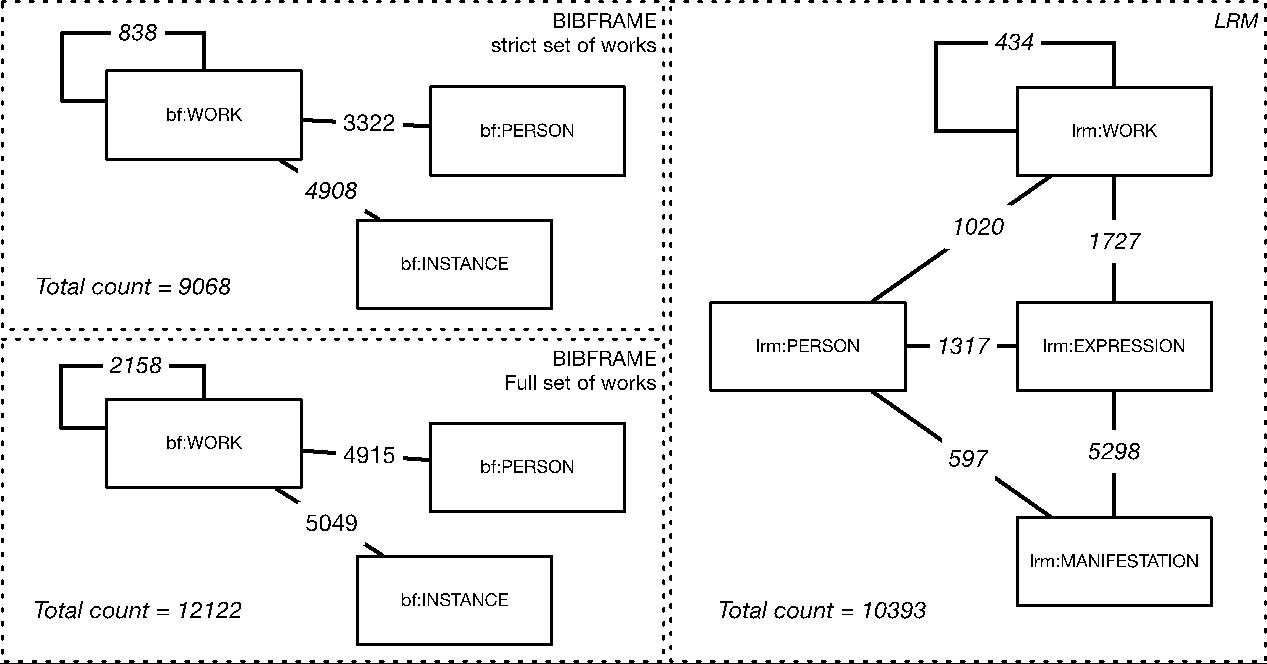
Numbers describing the entities produced in the conversions are shown in Table 3. Each model naturally produces the same number of persons and manifestations/instances. The number of manifestations/instances is lower than the initial number of records because of the merging of records describing the same publication (identified by same ISBN). An important finding is that the total number of entities created are relatively similar between the full BIBFRAME and the LRM conversion. This implies that BIBFRAME potentially gives the same (and in some cases slightly higher) total entity count for works as we get for works and expressions in LRM, because of the additional work that always is created for the publication as a whole. The strict BIBFRAME conversion gives the lowest number of entities because it does not create additional original works (and does not express translation relationships). The BIBFRAME Work in this conversion is more comparable to the Expressions in LRM. The grouping performed is also less restrictive and is only based on language and authorship.
| **BIBFRAME strict** | **BIBFRAME full** | **LRM** | |
|---|---|---|---|
| # Person | 1,295 | 1,295 | 1,295 |
| # Work | 1,434 | 2,497 | 713 |
| # Expression | - | - | 1,722 |
| # Manif. / Instances | 4,745 | 4,745 | 4,745 |
| # Total | 7,474 | 8,537 | 8,474 |
Numbers for the relationships created are presented in Figure 3. Counts are for all types of relationships (links) that occur between two entities. The numbers for work-to-work relationships in the BIBFRAME strict conversion is naturally higher than for LRM because of a higher number of works and the use of part-of relationships for analytic entries. The count of person-to-work relationships in BIBFRAME strict is equal to the sum of relationships from person to work, expression and manifestation in the LRM conversion. Most relationships that we have explored between person and manifestation in LRM is more naturally mapped to Work in the BIBFRAME interpretation (mostly editors, illustrators, authors of forewords etc.). In the BIBFRAME full conversion we get a substantially higher number of links. Partly this comes from the translation relationships between works and partly it is caused by a general increase of the number of Works which causes less deduplication of links.
The clustering effect for works in each result set is shown in Table 3 with the first number showing the count of cluster groups in various size bins. The number in parenthesis is the count of instances or manifestations that are clustered. The clustering in LRM is in two levels (works clustering expressions and expressions clustering manifestations. The number in parenthesis is in both for the count of manifestations. As typically is found when grouping bibliographic records there is a tail of works that groups few or only a single publication. The records in this collection has been selected because of their likeliness to be grouped under a common work and consequently the grouping effect is significantly higher it would be for a complete catalogue. Grouping for all sets follow the same pattern but represent variation in sizes. BIBFRAME full typically yields more smaller size clusters and single item clusters.
| **Clustering** | **BIBFRAME strict** | **BIBFRAME full** | **LRM WORKS** | **LRM EXPRESSIONS** |
|---|---|---|---|---|
| Cluster of 1 | 658 (658) | 1306 (1306) | 330 (330) | 973 (973) |
| Cluster of 2 | 156 (312) | 298 (596) | 82 (164) | 268 (536) |
| Cluster of 2-5 | 198 (742) | 262 (932) | 93 (354) | 273 (983) |
| Cluster 5-10 | 87 (662) | 95 (713) | 59 (454) | 121 (891) |
| Cluster 10-20 | 40 (575) | 39 (532) | 46 (692) | 55 (744) |
| Cluster 20-30 | 21 (520) | 7 (176) | 13 (328) | 7 (166) |
| Cluster 30-40 | 9 (340) | 8 (284) | 9 (316) | 7 (245) |
| Cluster 40-50 | 6 (270) | 4 (180) | 1 (42) | 5 (238) |
| Cluster 50+ | 10 (707) | 3 (205) | 25 (2864) | 11 (768) |
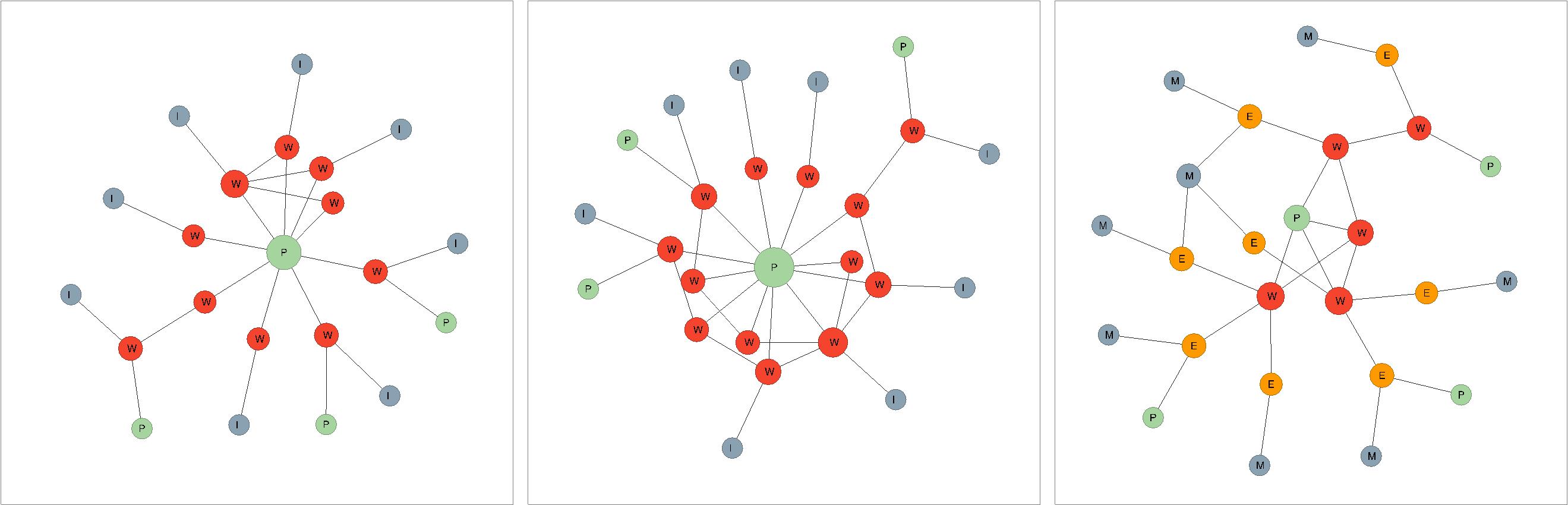
The resulting graph structure that each conversion creates shows significant differences both when looking at smaller examples in detail and when inspecting the overall structure of larger subsections. In Figure 4 we show the resulting model that is created from records describing the Danziger Trilogy by Günther Grass. In the MARC collection the trilogy is described in eight different ways (as shown below). One record describes an English translation of the trilogy as a whole by applying the 240 field and each translated part using added entries in the 700 field. Other records describe single works in German and Norwegian and one record is for a work in German by another author having Die Blechtrommel as subject.
In Figure 4, the leftmost BIBFRAME strict transformation has a work for each of the entries, but since added entries only are related to the work for the trilogy as a whole, we get a rather incomplete impression of what Instances that contain what works. An additional entity without connection to any Instance is introduced by the subject entry to Die Blechtrommel which implicitly is a language independent reference. The same problems can be found also in the BIBFRAME full transformation in the central illustration. Although we introduce additional work entities for the ‘original’ work, they mainly duplicate the work-to-work structure and do not add any additional clustering features or linking possibility. The rightmost graph shows the LRM transformation where the work as a language independent concept is used as ‘parent’ for the various language dependent expressions. The manifestation for the trilogy embodies the parts rather than the whole, and manifestation may have multiple direct links to entities representing the content (expressions). The number of works, together with expressions in the LRM version is equivalent to the number of works in the full BIBFRAME case, but the LRM transformation ends up having more work-work and work-expression connections than for the BIBFRAME case.
A different example can be found in figure 5, which is based on 136 records for William Golding’s novel Lord of the Flies in English, German, Spanish and Norwegian and 4 records describing two different movie adaptations. Using the rules for strict generation of BIBFRAME works the result is a set of 7 work entities with apparent clusters for each of the main languages of the collection and for each movie production. Since the reference from the movie is language neutral and the English version are identified by language, the literary works are only linked to the movies the originating author. The fuller BIBFRAME transformation produces more works (19) because we add translators and narrators to the identifying information. In this case the original work has a clustering effect for all language specific works and links with the movies – and ends up mimicking the LRM Work and Expression construct. The rightmost graph is LRM and contains 3 works and 11 expressions. The number of work and expression entities in LRM is in this case fewer than for the BIBFRAME transformation.
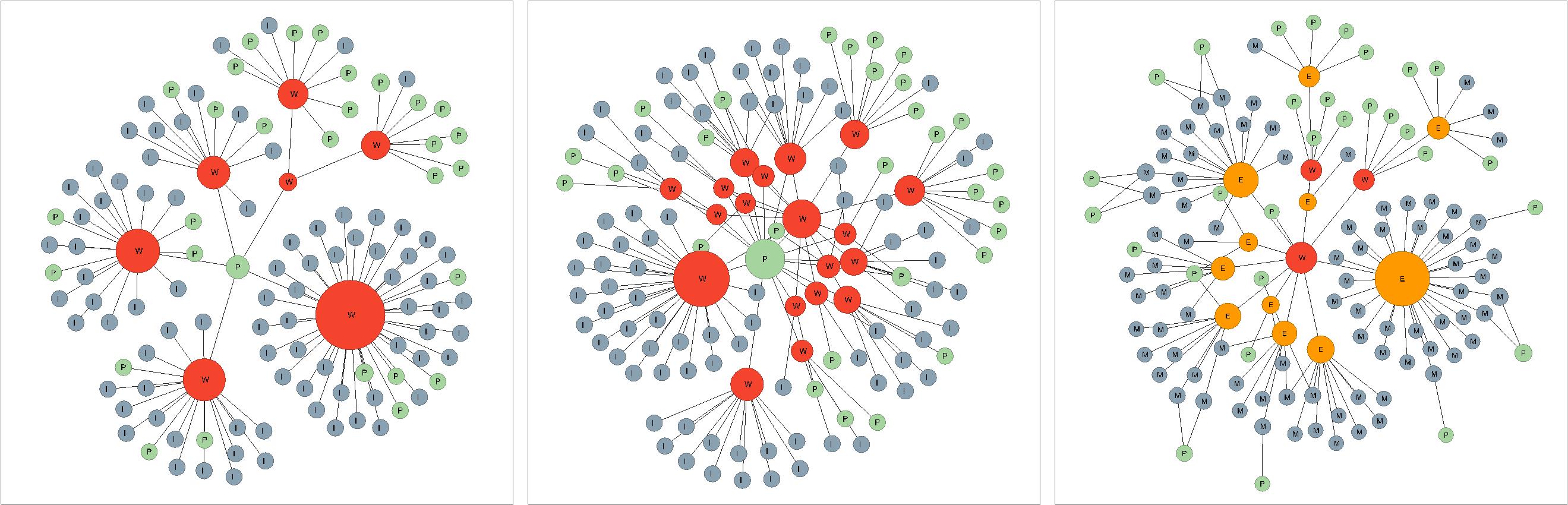
Table 4 shows the number of Works returned for each query type that was used in the search experiments. As expected, due to the clustering effect described above, there are more Works in the BIBFRAME list than in the LRM list. The parentheses show the number of manifestations/instances that were related to the retrieved Works. Here we see that the LRM set returns more manifestations than the BIBFRAME sets, again in accordance with the clustering effect. Only using three queries will give some random distribution, and more queries will be needed in order to validate the findings. However, the numbers show a clear tendency and illustrate how the models will affect results lists in real search systems. LRM will provide shorter result lists, with more complex linkage structure for enabling access to manifestations, whereas the BIBFRAME (and especially the full implementation) will provide a longer and more complex list with a shallower link structure. All three sets would be shorter than traditional manifestation-based systems.
| **Set** | **Query 1** | **Query 2** | **Query 3** | **Total** |
|---|---|---|---|---|
| **BIBFRAME full** | 138 (339) | 132 (271) | 49 (182) | 319 (792) |
| **BIBFRAME strict** | 97 (356) | 93 (274) | 33 (199) | 223 (829) |
| **LRM** | 47 (418) | 43 (395) | 27 (272) | 117 (1,085) |
| _**Total**_ | 282 (1,113) | 268 (940) | 109 (653) | 659 (2,706) |
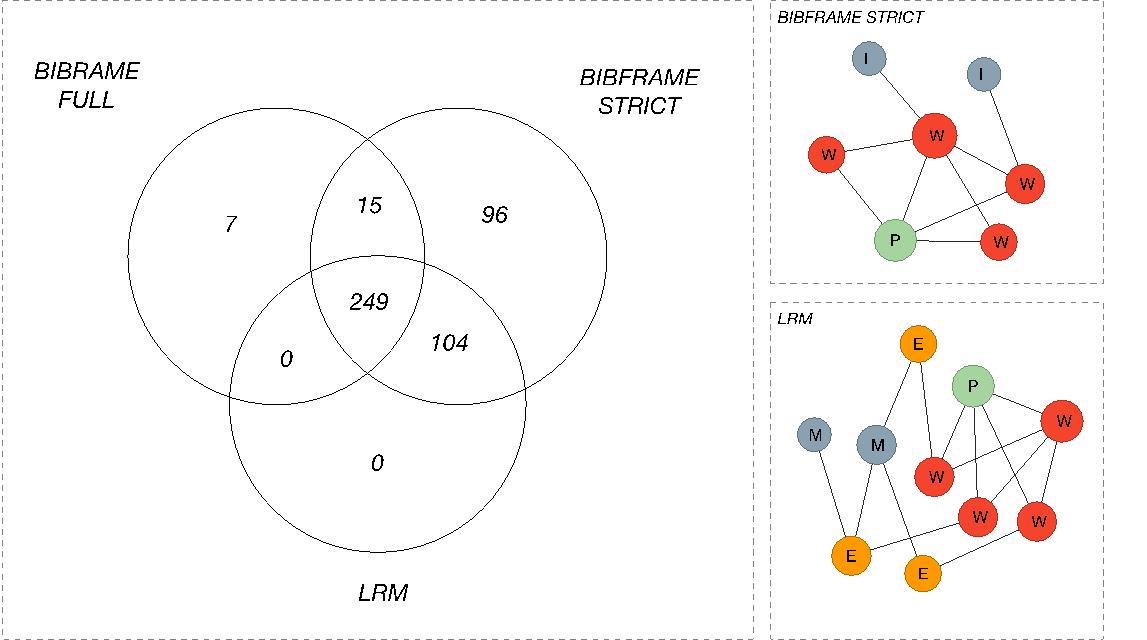
We have also counted the overlapping manifestation/instances in the three result lists across the sets. This was done for the top 20 hits. Figure 6 show that a majority of the manifestations/instances were present in all result list. An interesting finding is that a substantial number of manifestations only were part of the LRM result lists, and hence missing from the top BIBFRAME hits. This is caused by different modelling of aggregations. Publications that have multiple parts recognized as individual works are often described using added entries in the library records. The Danziger trilogy used in the case shown in Figure 4 is an example of such a construct. BIBFRAME always asserts one work for the publication as a whole, with part-of relationships to other works. The consequence is that there is no direct relationship connecting the parts to the instance – although this of course can be inferred from the data using a more intricate path. In our setup we only find the instance for the whole and not for the parts. LRM allows for manifestations to embody multiple expressions, and there will always be a direct and consistent work to manifestation path for any content part that is catalogued which means that for any work we will find all manifestations that embody an expression of the work. This sub figures on the right in Figure 6 illustrates this using one record describing the trilogy and its parts combined with a record describing a publication of one of the parts. This may be seen as a shortcoming in our setup but shows that the simplicity of BIBFRAME needs to be compensated by more intricate processing and interpretation of the data.
In this paper we show the results of a conversion of MARC records into RDF data according to the BIBFRAME and LRM information models. The MARC records were harvested from prominent European national libraries. In order to facilitate an investigation of the effects that the models can have on end user systems, we had to put down a substantial work into modifications and quality improvements of the records in order to develop a satisfying test set. This is a demanding process, not only for those who may want to implement the models on top of legacy data in real systems, but also in an academic context where we need high-quality test data.
The eventual conversion results show differences in the two models in their approach to organize works and manifestation/instances that will affect end user systems. These are differences that library professionals and bibliographic system developers must consider wisely.
Trond Aalberg is Professor at the Department of Archivistics, Library and Information Science, Oslo Metropolitan University, Norway. He can be contacted at Trond.Aalberg@oslomet.no.
Kim Tallerås is Assistant Professor at the Department of Archivistics, Library and Information Science, Oslo Metropolitan University, Norway. He can be contacted at Kim.Talleras@oslomet.no.
David Massey is Lecturer at the Department of Archivistics, Library and Information Science, Oslo Metropolitan University, Norway. He can be contacted at David.Massey@oslomet.no.
| Find other papers on this subject | ||
|
|
© the authors, 2019. Last updated: 14 December, 2019 |