User query behaviour in different task types in a spoken language vs. textual interface: a Wizard of Oz experiment
Xiaojun (Jenny) Yuan and Ning Sa
Introduction. This paper examined how task type affected user query behaviour in a spoken language interface in comparison to a textual input interface.
Method. Pre-search questionnaire, post-search questionnaire, post-system questionnaire and interviews, and a user-centred wizard of Oz experiment were conducted in the University at Albany, State University of New York to compare the user query behaviour difference between these two system interfaces. Forty-eight participants joined the study. Each participant performed twelve tasks of three types, including factual, interpretive, and exploratory tasks.
Analysis. Quantitative and qualitative analyses were used to analyse the collected data. Specifically, both Chi-square test and t test were employed in the quantitative data analysis.
Results. Results indicated that participants initiated significantly fewer queries for both factual and interpretive tasks, and input significantly longer queries for both interpretive and exploratory tasks in the spoken language interface than in the textual interface. Participants employed significantly more stop words for both interpretive and exploratory tasks and used significantly more indicative words in factual tasks in spoken language interface than that in the textual input interface.
Conclusion. We conclude that task type has a significant effect on user query behaviour. System design implications of the spoken language interfaces were discussed and recommendations were provided.
Introduction
In the digital society, information systems have become increasingly ubiquitous and important in our everyday lives. People prefer systems that they can easily access to, and can effectively use anytime and anywhere. In recent years, the challenges faced by designers of information systems are three folded, that is, the variety of users of such systems has increased, the techniques and ways of access to information have changed, and the data format and volume have increased sharply. Spoken language systems are drawing increasing attention as evidenced by the fact that major search engine companies (e.g. Google, Microsoft) have been developing voice search systems in which users input the queries by speaking instead of typing.
Research has shown that users may behave and perceive differently in systems with different input modes (Crestani and Du, 2006). Specifically, Crestani and his colleagues found that there were differences between written quires and spoken queries, and written queries were more effective than spoken queries (Crestani and Du, 2006). Patel, et al. (2009) recruited 45 participants to compare speech and dialed input voice user interfaces for Indian farmers. Results indicated that users felt uncomfortable when speaking to the system and they indicated that speech input was less successful. In a recent study by (Begany, Sa, and Yuan, 2015) with the focus on the factors that affect user perception of a spoken language system, users’ familiarity with the system, ease-of-use of the system, speed of the system, as well as trust, comfort level, fun factor, and novelty were identified as major factors that had an impact on user perception.
Researchers have found that allowing or encouraging natural query formulation could lead to linguistic expressions indicative of intention (Belkin et al., 2003; Murdock, Kelly, Croft, Belkin, and Yuan, 2007). In this study, such linguistic expressions are called ‘indicative words’, including ‘what’, ‘when’, ‘where’, ‘which’, ‘why’, ‘who’, ‘whose’, and ‘how.’ It is anticipated that in a spoken language input system, users will be more likely to use indicative words, rather than just keywords, as is usual in standard typed input system. As a result, we aimed to find out whether users would employ more conversational terms, such as stop words and indicative words (e.g. what, how, why, etc.) in a spoken interface than in a textual interface.
It has been demonstrated that users performed differently when engaging with various kinds of tasks using information systems (Gwizdka and Spence, 2006; Kellar, Watters, and Shepherd, 2007; Liu et al., 2010; Li and Belkin, 2008). In this study, we were interested in finding the effect of task types on user query behaviour. Although there is a rich body of research about task types on query behaviour in textual interface, to our knowledge, research is needed to further investigate the relationship between task types and user query behaviour in the context of spoken language interface.
Our goal of this research is to investigate user query behaviour in a spoken language interface in order to contribute to better understanding of spoken queries and improvement of user experience with spoken language systems.
In particular, we investigated the following research question (RQ):
RQ: Does task type affect user query behaviour in a spoken language interface vs. textual interface? How?
Background
Task Type on User Search Behaviour in Textual Interface
Task type has been classified using various methods and along different dimensions (e.g., Freund, 2008; Kellar et al., 2007; Kim, 2006; Li and Belkin, 2008). Li and Belkin (2008) designed a scheme to classify tasks based on various dimensions of task features. In her doctoral dissertation, Kim (2006) identified three types of tasks, defined as factual, interpretive, and exploratory.
Previous researches have examined the effects of task types on user search behaviour. Marchionini (1989) concluded that in open-ended tasks, users consumed more time and did more moves than in close-ended tasks. Kim (2006) found that task type had a significant impact on the number of saved pages and the ratio of viewed pages to saved pages. In a study investigating effects of fact-finding tasks of different complexity on user search behaviour, Gwizdka and Spence (2006) reported that subjective task difficulty was closely related to user behaviour such as dwell time on a page and the number of visited webpages.
Qiu (1992) demonstrated that users behaved differently in searching specific tasks versus general tasks. For example, users tended to use browsing features for general tasks, and analytical searching for specific tasks. Hsieh-Yee (1998) investigated how users employed various search tactics in four types of search tasks. Results showed no significant difference between searching for texts and graphic information, or between known-item and subject searches. Kellar, Watters, and Shepherd (2007) examined how users interacted with web browser when engaging in four types of tasks (fact-finding, browsing, information gathering, and transactions). They found that when searching the information gathering task, users took more time completing it, viewed more pages, and utilized the web browser functions more often than those of the other tasks. Li (2008) studied the relationship between intellectual and decision/solution tasks and user behaviours. Results indicated that intellectual tasks requested more IR systems consulted, longer queries and more result page viewed than those of decision/solution tasks did. Liu et al. (2010) studied the impact of task types on search behaviours and concluded that search behaviours such as task completion time, decision time and eye fixations could be used as implicit indicators of the type of task users engaged in.
Task Type on User Query Behaviour in Textual Interface
It has been widely acknowledged that task type can influence user query behaviour (Liu et al., 2010, Toms et al., 2007). Liu et al. (2010) found that task type and task situation affected users’ query reformulation behaviour. In their study, simple, hierarchical, and parallel tasks were investigated. In simple tasks, users searched for simple facts; in hierarchical tasks, users explored different characteristics of one concept; while in parallel tasks, users searched for different concepts of the same level in a conceptual hierarchy. It seems that Specialization was used significantly more in Simple and Hierarchical tasks than in Parallel tasks, while Word Substitution was used significantly more in Parallel tasks than in Simple and Hierarchical tasks. A study exploring the effect of task type and users’ cognitive abilities (working memory) on query reformulation behaviours by Liu et al. (2010) has proved that only task type could significantly influence on query reformulation behaviours. In an analysis of 872 unique search queries of five query types ( New, Add, Remove, Replace and Repeat) collected from a user study of 50 participants performing three types of tasks (exploratory, factorial and abstract), Kinley, Tjondronegoro, Partridge and Edwards (2012) reported that search task types had a significant impact on user query reformulation behaviour. Specifically, search task types affected how users reformulated the New and Repeat queries.
Toms et al. (2008) studied query behaviour change on two types of task structure (hierarchical and parallel) and three types of tasks (decision-making, fact-finding and information-gathering). They reported that users formulated fewer queries but spent longer time in query result processing for Hierarchical tasks than for Parallel tasks. In addition, they found that decision-making and fact-finding tasks initiated more queries than information-gathering tasks. Users tended to add additional terms in information-gathering than in decision-making tasks. Kim and Can (2012) identified query behavior patterns based on various search task types. They categorized search tasks into three groups based on different user intents, including directed-closed, directed-open and undirected. Results indicated that task types affected user query behavior measured in terms of query interval lengths, query iteration, identical query, failed query and click-through query rate.
User query behaviour in spoken interface
The work of Zue et al. (2000) is relatively comprehensive in spoken language query understanding, but it has been applied in limited domains. Fujii (2001) investigated technical issues of spoken language input compared to text input of the same query, and found no significant differences. Kamar and Beeferman (2010) presented a log-based study to compare web search patterns between speaking and typing for the purpose of better understanding the factors that can be attributed to users’ decision on speaking instead of typing. Results showed that the factors leading to spoken queries were if a query was generated from an unconventional keyboard, for a search about a person’s location, or for a search topic that can be responded in a ‘hands-free’ mode.
Du and Crestani (2004) investigated the effectiveness of spoken queries, and proposed a system design for verbal interaction in information systems. Subsequently, in a study by Crestani and Du (2006), the spoken queries and written queries collected in an experimental environment were compared based on length, duration, part of speech, and retrieval effectiveness. They reported that spoken queries were significantly longer than written queries, and that more different types of words were found in spoken queries than in written queries. Results demonstrated that speech input offers a more natural method of expression of information need and stimulates the formulation of longer queries. However, longer spoken queries did not significantly improve retrieval effectiveness in comparison to written queries.
In Crestani and Du’s study, each participant was asked to enter only one query for each task while a common web search usually involves several queries (Crestani and Du, 2006). In contrast to Crestani and Du (2006), the current study did not limit the number of queries and as a result, the queries collected are closer to the real-life situation.
Wizard of Oz Studies and Usability of Spoken Language Interface
The Wizard of Oz method (Ford and Ford, 1993) has been employed to evaluate natural language dialogue systems (e.g. Johnsen et al., 2000) and multimodal systems (e.g. Gustafson et al., 2000; Salber and Coutaz, 1993). The method has been proved to be useful in supporting the design process and evaluating information systems (Bernsen and Dybkjaer, 1997). In Wizard of Oz studies, certain aspect of a complex system is performed not by the system itself, but by a human being (the Wizard). The Wizard (unknown to the subject) simulates that aspect of the system, e.g. accurate transcription of what the subject says. The Wizard of Oz method is adopted when the particular aspect of the system is not yet actually possible or feasible to implement, but it is understood to be implementable in the near future.
Researchers have reported promising findings on usability of spoken language systems. Litman and Silliman (2004) introduced a spoken language dialogue system called ITSPOKE, in which they tried to utilize speech instead of text-based dialogue tutoring. Later on, Forbes-Riley and Litman (2011) employed a wizarded version of ITSPOKE to test two different dynamic student uncertainty adaptations, that is, ‘Simple –adaptive’ and ‘Complex-adaptive.’ They concluded that dynamically reacting to students’ affective state (or ‘uncertainty’) can significantly improve their performance on computer tutors. Oulasvirta, Engelbrecht, Jameson, and Moller (2006) concluded that how a system responds to an error could affect how users perceive the usability of the system. Portet et al. (2013) conducted a similar study in which they performed a usability testing of a new smart home system with audio-processing technology, called SWEET-HOME. Results demonstrated that speech technology is providing a sense of safety and security for the elderly.
In order to study the efficacy of spoken language input, and meet all the requirements of the research, including precise interpretation of spoken input, we chose to use the Wizard of Oz method. Some of the research most directly relevant to this study includes (Akers, 2006; Klein, Schwank, Généreux, and Trost, 2001).
In sum, there exists a number of previous work on tasks and user query behaviour, but to our knowledge, little research has focused on the relationship between task type and user query behaviour in spoken language interface. It is worth examining such a relationship through a user-centred wizard of Oz experiment. Further description of the study’s experimental design follows in the subsequent method section.
Method
Experimental Design
The experiment employed a within-subject design. Participants conducted searches using the two systems, first one system, and then the other. When using each system, participants first searched on a training topic, and then performed searches on six different topics of three task types (see ‘Tasks and Topics’ section). The first test topic was of the same task type as the training topic, the second topic was of the other task type, and so on. The order of the task types and topics was alternated across participants. The experiment was replicated by exchanging the order of the two systems. In order to satisfy these constraints, forty-eight participants were recruited from University at Albany.
Dataset
We adopted an English subset of ‘The Wikipedia XML Corpus For Research’ (Denoyer and Gallinari, 2006) as the document collection. This collection, which has been used in INEX research groups in the past years, is a set of XML documents (659,388 documents) generated using Wikipedia and encoded in UTF-8. The documents of the Wikipedia XML collections were structured in a hierarchy of categories defined by the authors of the articles.
Data Collection
The interactions between users and systems were recorded using the computer logs and the logging software called ‘Techsmith Morae 3.1’ (http://www.techsmith.com/morae.html). Morae recorded data also include what the user said during the whole search process and user comments in an exit interview. An entry questionnaire gathered participants’ demographic and background information; a pre-task questionnaire elicited information about participants’ knowledge of the topic; a post-task questionnaire collected participants’ comments on the specific search; a post-system questionnaire elicited participants’ opinions about the specific system; and, an exit interview compared search experience and use of the two systems.
Procedure
After participants arrived, they followed the experiment procedure listed as below.
- Completed an informed consent form, which included detailed instructions about the experiment.
- Filled out the entry questionnaire.
- Finished a brief tutorial of the general interface of the two systems.
- Began a training topic to practise with the first system they would use.
- For each topic, participants filled out a pre-task questionnaire, carried out the search and saved the answers in the given place. When they felt that a satisfactory answer was saved, or they ran out of time, they filled out a brief post-task questionnaire. Participants had up to 10 minutes per search.
- Repeated step 5 until six topics in the first system were completed.
- Repeated steps 4 – 6 for the next set of topics using the second system.
- Took an exit interview.
Each participant received $30 after completing the experiment.
Wizard of Oz
A Wizard of Oz experiment was conducted in a usability laboratory which has two separate rooms; one in which the participants performed their assigned tasks; the other in which an experimenter (the Wizard) used a computer terminal to interact with the participants’ terminal. The Wizard could observe the participants by looking at how the participants performed the tasks. The Wizard listened to the participants’ spoken input, and then promptly typed exactly what the participant said into the system. In other words, the search query shown on the interface was actually typed by the wizard. Participants read the query, and then responded to the system. This process continued until the participants completed the tasks using the spoken system.
Tasks and Topics
Twelve tasks were categorized into three types according to the analysis by Kim (2006). We list the search topics of each task type as below.
Factual task (FT)
- The largest cruise ship in 2006
- NASA imaging program
- Hypermarket in Spain
- The name of an actress and two movies
Interpretive task (IT)
- Differences between Organic food, genetically modified food, and raw food
- Eating disorders in high school
- Charter school, public school, and private school
- Growing fruits
Exploratory task
- Lead paint poison
- Reasons for vegetarians and vegans
- Beer brewing at home
- Feline intelligence, temperament, behaviors
Factual tasks are close-ended and collect facts only. Interpretive tasks and exploratory tasks are both open-ended and require the user’s evaluation, inference, and comparison. However, the former are more focused and goal oriented than the latter.
Below, we give an example topic for each task type.
Task Type 1 (Factual Task):
Topic: A friend of yours just got a job as casting director for the diving show on a cruise ship, which was the largest cruise ship in the world when it was launched in 2006. He told you that he is able to get you a free week aboard the ship. You just have to get to Miami, where the ship will be docked. You want to go to the cruise line’s website but you forgot the name of the ship and the cruise line. You can't reach your friend because he is out to sea.
Task: Find the name of the ship, as well as the name of the cruise line, so that you can find out when it is leaving. Save the document(s) where you have found the information required.
Task Type 2 (Interpretive Task):
Topic: Charter schools are primary or secondary schools that receive public money but are not subject to some of the rules, regulations, and statutes that apply to other public schools. Some critics argue that these schools give too much power to the teachers and the parents. You are a newly graduated teacher about to enter the education work force.
Task: You decided to become a teacher to try to improve the education of underprivileged children. Find the pros and cons for charter schools, public schools, and private schools to have a better understanding of which type of institution you would prefer to work in as an educator. Save the document(s) where you have found the information required.
Task Type 3 (Exploratory Task):
Topic: Your classmate Amari has recently become very interested in learning more about beer, brewing and brewing at home. Amari has asked for your help by finding out how to brew beer at home.
Task: You want to learn more about the process of brewing beer at home. Save the document(s) where you have found the information required.
System design and implementation
Both the textual input system (baseline, keyboard) and spoken language system (experimental, spoken input) were implemented using the Apache Lucene information retrieval toolkit (http://lucene.apache.org/). They employed the same underlying information retrieval and presentation system, and also used the same interface. The only difference is on the input mode. When searching with the textual input system, the participants used a standard keyboard to enter queries and a mouse to click buttons and choose results. When using the spoken language system, the participants employed a touch screen to perform clicking and selecting; and spoke out the queries while the wizard entered them into the search box. Figure 1 displays the system interface screenshot. We put text ‘The more you say, the better the results are likely to be’ to encourage users to fully express their information need.
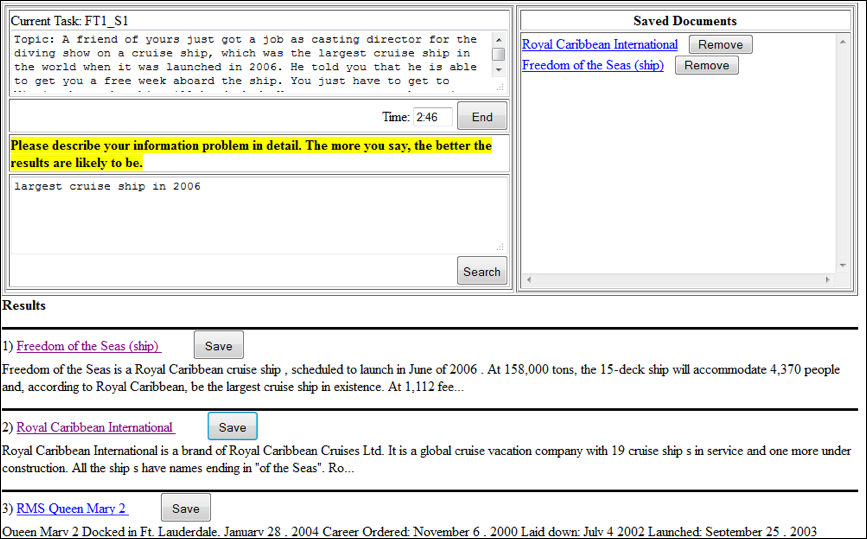
Results
Participants
Forty-eight graduate students from University at Albany joined the study. In terms of degree earned, eleven participants have master and thirty-seven have bachelor degree. For the age range, twenty-four participants are in 16-25, sixteen in 26-35, three in 36-45, four in 46-55 and one in 56-65. Regarding the major, nineteen participants are from library and information science, eight from computer science, four from psychology, two from economics, and the rest from other majors. Computer and information searching experience was collected from an entry questionnaire, using a 7-point scale, with 1=low, and 7=high. Results demonstrated that participants used computers ((Mean=7.00, SD=0.00) and performed search very frequently (Mean=6.40, SD=1.47). Their Internet searching experience was high (Mean=6.73, SD=0.64). Their use of touch screen interface was at medium level (Mean=5.13, SD= 1.78). But their use of voice search of search engines (Mean=2.42, SD=1.70) and commercial spoken software was very low (Mean=1.85, SD= 1.13).
Task Type on User Query Behavior
User query behavior was measured in terms of query length, iterations, terms used in queries, stop word frequency, and indicative word frequency in queries. Table 1 shows the definition of the measures.
| Measure | Definition |
|---|---|
| Time of Task Completion | The amount of time spent in completing each task |
| Query length | The number of terms in each query |
| Iteration | The number of queries in each task |
| Terms used in queries | The exact terms used in each query |
| Stop word frequency | The number of stop words in each query |
| Indicative word frequency | The number of indicative words in each query |
Results of one-way ANOVA showed that there was a significant impact of task type on participants’ time of task completion, F=13.19, p<.01 (Factual task: Mean=348.14, SD=181.26; Interpretive task: Mean=380.35, SD=152.57; Exploratory task: Mean=294.92, SD=158.64, df=573).
Figure 2 shows the distribution of query length and iterations. T-test indicated that participants input significantly longer queries in the experimental system than in the baseline system for both interpretive tasks (Experimental: Mean=3.44, SD=2.18; Baseline: Mean=3.08, SD=1.78, t =3.26, df =1278, p<.01), and exploratory tasks (Experimental: Mean=3.23, SD=1.71; Baseline: Mean=2.97, SD=1.63, t = 2.42, df = 987, p<.05).
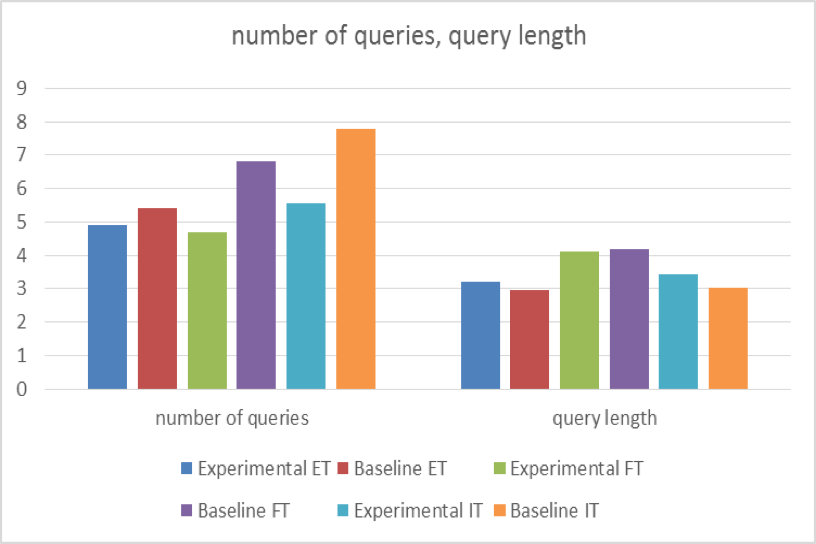
With regards to the number of iterations, t-test results showed that participants initiated significantly fewer queries in the experimental system than in the baseline system for both interpretive tasks (Experimental: Mean=4.7, SD=2.83; Baseline: Mean=6.8, SD=4.31, t = -4.00, df = 190, p<.01), and factual tasks (Experimental: Mean=5.55, SD=3.03; Baseline: Mean=7.78, SD=4.84, t = -3.83, df = 190, p<.01).
We want to observe if in a spoken language input interface, searchers will be more likely to use linguistic expressions to indicate their intentions, rather than just keywords, as is usual in standard typed input. When looking into the most frequently used queries for each topic/system combination (see Table 2), we didn’t find notable differences between the two systems in terms of these query characteristics.
| Topic | Baseline | Experimental |
|---|---|---|
| FT1 |
royal Caribbean (6) largest cruise ship (5) largest cruise ship 2006 (5) |
largest cruise ship 2006 (5) largest cruise ship (2) largest cruise ship 2006 miami (2) |
| FT2 |
nasa imaging program (5) NASA telescopes (5) nasa program four telescopes (4) |
nasa infrared telescope (3) nasa program (3) nasa infrared satellite (2) |
| FT3 |
supermarkets in spain (14) el corte ingles (6) department stores in spain (4) |
supermarkets in spain (7) el corte ingles (4) stores in spain (3) |
| FT4 |
the da vinci code (13) audrey tautou (12) amelie (7) |
the da vinci code (12) audrey tautou (10) amelie (7) |
| IT1 |
organic food (14) raw food (14) genetically modified food (13) |
organic food (14) raw food (12) genetically modified food (8) |
| IT2 |
eating disorders (17) beriberi (7) binge eating disorder (7) |
eating disorders (8) bulimia (7) binge eating disorder (5) |
| IT3 |
private schools (12) public school (12) public schools (11) |
charter schools (8) public schools (8) private school (7) |
| IT4 |
gooseberry (9) strawberries (8) strawberry (8) |
gooseberries (7) growing strawberries (6) gooseberry cultivation (5) |
| ET1 |
lead paint (9) lead poisoning (7) how to know the paint status (4) |
lead paint (8) lead poisoning (4) lead paint poisoning (3) |
| ET2 |
veganism (6) vegetarian (6) vegetarianism (5) |
vegetarian (8) what is a vegan (3) why some people eat meat and some not (2) |
| ET3 |
brewing beer (7) brewing beer at home (6) homebrewing (5) |
homebrewing (12) how to brew beer (7) homebrew (5) |
| ET4 |
cat breeds (12) feline intelligence (12) cat intelligence (8) |
feline intelligence (9) cat behavior (8) cat breeds (7) |
Most participants used task related keyword search in both systems. However, in the exploratory tasks, in particular ET1, ET2 and ET3, participants used indicative words very often (Table 2). Further, when searching for ET2 and ET3, participants employed many more indicative words in the experimental than in the baseline system. As shown in Table 2, some of the most frequently used queries involved indicative words, such as ‘what’, ‘why’, ‘how’, etc. Table 2 also displayed the term frequency of indicative words in the two interfaces. The indicative words investigated in this study are: what, which, who, whose, when, where, why, and how.
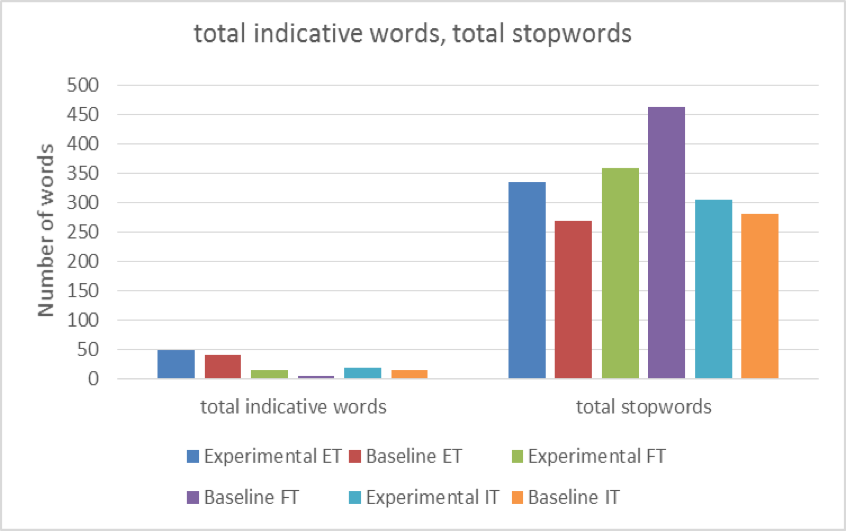
We further looked into the term frequency of stop words in both systems across the three types of tasks. The total number of stop words and their proportion to the total number of all words were compared between two interfaces across different tasks by using Chi-square test. Stop words were used more frequently in the spoken language input interface than in the textual input interface for all the three types of tasks though the difference in factual task was not significant (Interpretive task: X2=9.91, p<.01; Exploratory task: X2=16.1, p<.01 ).
In all the three types of tasks, the term frequency of indicative words in spoken language input interface was higher than that in textual input interface though only the difference in factual tasks was significant (X2=9.15, p<.01). In Figure 3, a comparison of distributions of indicative words and stop words across systems and tasks was graphically displayed. Table 3 and Table 4 show the stop word frequency and indicative word frequency among different types of tasks. It seems that task types significantly affected the frequency of stop words and indicative words.
| Task by system | Total stop word | Total count of all words | Proportion | P value | |
|---|---|---|---|---|---|
| Experimental | ET | 335 | 1518 | 0.221 | X2=15.89 p<.01**. |
| FT | 359 | 1877 | 0.191 | ||
| IT | 305 | 1834 | 0.166 | ||
| Baseline | ET | 270 | 1540 | 0.175 | X2=32.16 p<.01** |
| FT | 463 | 2623 | 0.177 | ||
| IT | 281 | 2295 | 0.122 | ||
| Both | ET | 605 | 3058 | 0.198 | X2=44.11 p<.01** |
| FT | 822 | 4500 | 0.183 | ||
| IT | 586 | 4129 | 0.142 | ||
| Task by system | Total indicative words | Total all words | Proportion | P value | |
| Experimental | ET | 49 | 1518 | 0.032 | X2=37.19 p<.01** |
| FT | 15 | 1877 | 0.008 | ||
| IT | 19 | 1834 | 0.010 | ||
| Baseline | ET | 42 | 1540 | 0.027 | X2=67.49 p<.01** |
| FT | 5 | 2623 | 0.002 | ||
| IT | 16 | 2295 | 0.007 | ||
| Both | ET | 91 | 3058 | 0.030 | X2=102.92 p<.01** |
| FT | 20 | 4500 | 0.004 | ||
| IT | 35 | 4129 | 0.008 | ||
Discussions
We carried out a wizard of Oz experiment to compare the user query behaviour in a spoken language input interface versus a textual input interface across three different task types. Results demonstrated that task types significantly affected user query behaviour. Specifically, task types have a significant impact on participants’ time of task completion (F=13.19, p<.01). Participants initiated significantly fewer queries in the spoken language interface than in the textual interface for both factual tasks and interpretive tasks. Participants input significantly longer queries in the spoken language interface than in the textual interface for both interpretive tasks and exploratory tasks. The findings further confirmed the results from Crestani and Du (2006), but seemingly contradicted to the results from (Kamvar and Beeferman, 2010). Kamvar and Beeferman (2010) found that longer queries are more likely to be typed than short queries, and users may speak a query shorter than six words than a longer query. We took a close look on the query length from our study and observed that the average spoken query length was below six. It may be interesting to further explore if such a pattern exists in various studies related to spoken language system design and evaluation.
Results also indicated that two typical queries involving stop words and indicative words are ‘how to know the paint status (ET1)’ and ‘why some people eat meat and some not (ET2).’ On the other hand, two typical queries with keywords only are ‘lead paint (ET1)’ and ‘vegetarian (ET2)’. As reported in (Kamvar and Beeferman, 2010), users tended to speak the familiar queries, such as Location, Food and Drink, Shopping and Travel related. It may be meaningful to consider embedding abundant terms related to these topics in the database of the spoken language system when designing such systems.
We found that participants used significantly more stop words in the spoken language input interface than in the textual input interface for both interpretive and exploratory tasks. Participants used significantly more indicative words in spoken language input interface than that in the textual input interface for factual tasks.
It seems that spoken queries involved more stop words and more indicative words than written queries since they are similar to natural language used in our everyday conversation. This finding was consistent with Crestani and Du (2006) in that the interaction between the user and the spoken interface was more conversational. It also confirmed our previous findings (Begany, Sa, and Yuan, 2015) that the spoken interface is a more natural way of interaction.
Results indicated that when the interface is textual or spoken, the participants seemed to change the way they interacted with the IR system. When using textual interface, the IR system was a computer to the users but when using spoken interface, the IR system became a live object they were communicating with. This finding was confirmed from (Begany, Sa, and Yuan, 2015) in that participants commented that spoken language interface is ‘fun to use.’
Regarding how term frequency changed according to the task types, we found that in both interfaces, stop words were used least frequently in interpretive tasks. In exploratory tasks and factual tasks, the results from the two interfaces were different. When looking into the indicative word frequency across task types, we found that users employed indicative words most frequently in exploratory tasks and least in factual tasks. This could be attributed to two reasons. One reason is the nature of the factual tasks. Factual tasks were close-ended and collected facts only, while exploratory tasks and interpretive tasks were opened-ended and involved the users’ evaluation, inference, and comparison. Another reason is that, sometimes users may not be able to find terms appropriate for describing their information problems (Belkin, 1980). Our findings indicated that exploratory and interpretive tasks encouraged users to generate more question-like queries than factual tasks did. We feel it is necessary to take into account the ‘intention-revealing’ words instead of simply discarding them during the process of designing and implementing spoken language systems. Also, it is critical to consider user information problems and interests in designing such systems.
Conclusion
This paper explored the effect of task types on user query behaviour using a spoken input interface in comparison to a textual input interface. We found that task types had a significant impact on user query behaviour, including query length, iteration, stop word frequency and indicative word frequency in the spoken language interface vs. the textual interface.
This study has its limitations in terms of limited types of tasks and topics, and limited number of participants. Furthermore, the results from the wizard of Oz experiment may not be the same as the real spoken language system in various ways. In spite of the limitations, this study will contribute to the field with evaluation of a new method of interaction with information systems, in comparison to a traditional keyboard-based interaction; and design standard for a spoken language interface.
Our study also provides implications for the design and development of the spoken language systems. First, familiar topics should be used to increase users’ comfortable level. Second, user intentions and user needs should be considered. It is critical to know what users really want to find out, and which kind of tasks they could potentially perform using the spoken system. Third, it may be useful if designers can provide users a choice between spoken and textual input for different tasks and topics. This method should address potential discomfort of users. At last, it would be useful if the spoken system can elicit users’ information problems at the very beginning and then make sure the database has enough topics and documents to match with them.
Nowadays, users tend to share a significant amount of information through the social media platforms. It seems that speaking is becoming the dominant behaviour for users with small screen devices. We feel an urgent need to conduct the similar studies in a social media site in order to discover collaborative behavioural patterns of users, and relate such patterns to various task types.
Acknowledgements
We thank Institute of Museum and Library Services (IMLS) grant #RE-04-10-0053-10.
About the authors
Xiaojun (Jenny) Yuan is an Assistant Professor in the Department of Information Studies of College of Engineering and Applied Sciences at University at Albany, State University of New York. Her research interests include human information behaviour, interactive information retrieval, user interface design and evaluation, and human computer interaction. Email: xyuan@albany.edu.
Ning Sa is a PhD candidate in Informatics at University at Albany, State University of New York. Her research interests are in human computer interaction in information retrieval. She can be contacted at nsa@albany.edu.
References
- Akers, D. (2006). Wizard of Oz for participatory design: inventing a gestural interface for 3D selection of neural pathway estimates, Proceeding of CHI '06 Extended Abstracts on Human Factors in Computing Systems, 454–459.
- Begany, G., Sa, N. & Yuan, X.-J. (2015). Factors affecting user perception of a spoken language vs. textual search interface: a content analysis. Journal of Interacting with Computers, 28(2), 170-180.
- Belkin, N. (1980). Anomalous states of knowledge as a basis for information retrieval. Canadian Journal of Information Science, (5), 133–143.
- Belkin, N. J., Kelly, D., Kim, G., Kim, J.-Y., Lee, H.-J., Muresan, G., … & Cool, C. (2003). Query Length in Interactive Information Retrieval. Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Informaion Retrieval, 205–212
- Bernsen, N. O. & Dybkjaer, L. (1997). Designing Interactive Speech Systems: From First Ideas to User Testing (1st ed.). Secaucus, NJ, USA: Springer-Verlag New York, Inc.
- Crestani, F. & Du, H. (2006). Written versus spoken queries: A qualitative and quantitative comparative analysis. Journal of the American Society for Information Science and Technology, 57(7), 881–890.
- Denoyer, L. & Gallinari, P. (2006). The Wikipedia XML Corpus. SIGIR Forum, 40(1), 64–69.
- Du, H. & Crestani, F. (2004). Retrieval Effectiveness of Written and Spoken Queries: An Experimental Evaluation. In H. Christiansen, M.-S. Hacid, T. Andreasen, & H. L. Larsen (Eds.), Flexible Query Answering Systems (pp. 376–389). Springer Berlin Heidelberg. Retrieved from http://link.springer.com/chapter/10.1007/978-3-540-25957-2_30
- Forbes-Riley, K. & Litman, D. (2011). Designing and evaluating a wizarded uncertainty-adaptive spoken dialogue tutoring system. Computer Speech and Language, 4, 105-126.
- Ford, N. & Ford, R. (1993). Towards a cognitive theory of information accessing: an empirical study. Information Processing & Management, 29(5), 569-585.
- Freund, L. (2008). Exploring task-document relations in support of information retrieval in the workplace. SIGIR Forum, 42, 107.
- Fujii, A., Itou, K. & Ishikawa, T. (2001). Speech-Driven Text Retrieval: Using Target IR Collections for Statistical Language Model Adaptation in Speech Recognition. In A. R. Coden, E. W. Brown, & S. Srinivasan (Eds.), Information Retrieval Techniques for Speech Applications (pp. 94–104). Springer Berlin Heidelberg. Retrieved from http://link.springer.com/chapter/10.1007/3-540-45637-6_9
- Gustafson, J., Bell, L., Beskow, J., Boye, J., Carlson, R., Edlund, J., … & Wirn, M. (2000). AdApt - a multimodal conversational dialogue system in an apartment domain. Proceedings of ICSLP 2000, 134–137.
- Gwizdka, J. & Spence, I. (2006). What Can Searching Behavior Tell Us About the Difficulty of Information Tasks? A Study of Web Navigation. Proceedings of the American Society for Information Science and Technology, 43(1), 1–22.
- Hsieh-Yee, I. (1993). Effects of search experience and subject knowledge on the search tactics of novice and experienced searchers. Journal of the American Society for Information Science, 44(3), 161–174.
- Hsieh-Yee, I. (1998). Search Tactics of Web Users in Searching for Texts, Graphics, Known Items and Subjects. The Reference Librarian, 28(60), 61–85.
- Kamvar, M. & Beeferman, D. (2010). Say what? Why users choose to speak their web queries? Proceeding of Interspeech 2010, 1966-1969.
- Kellar, M., Watters, C. & Shepherd, M. (2007). A field study characterizing Web-based information-seeking tasks. Journal of the American Society for Information Science and Technology, 58(7), 999–1018.
- Kim, J. (2006). Task as a Predictable Indicator for Information Seeking Behavior on the Web. Doctoral Dissertation. Rutgers, the State University of New Jersey.
- Kim, J. & Can, A. (2012, January). Characterizing queries in different search tasks. Proceeding of HICSS 2012, 1697-1706.
- Kinley, K., Tjondronegoro, D., Partridge, H. & Edwards, S. (2012). Relationship between the nature of the search task types and query reformulation behaviour. Proceedings of the Seventeenth Australasian Document Computing Symposium, 39-46.
- Klein, A., Schwank, I., Généreux, M. & Trost, H. (2001). Evaluating Multi-modal Input Modes in a Wizard-of-Oz Study for the Domain of Web Search. In Ann Blandford and Jean Vanderdonckt (Eds.), People and Computers XV—Interaction without Frontiers (pp. 475–483). Springer London.
- Li, Y. & Belkin, N. J. (2008). A faceted approach to conceptualizing tasks in information seeking. Information Processing and Managemen, 44(6), 1822–1837
- Liu, C., Gwizdka, J., Liu, J., Xu, T. & Belkin, N. J. (2010). Analysis and Evaluation of Query Reformulations in Different Task Types. Proceedings of the 73rd ASIS&T Annual Meeting on Navigating Streams in an Information Ecosystem - Volume 47, 17, 1–10.
- Liu, J., Cole, M. J., Liu, C., Bierig, R., Gwizdka, J., Belkin, N. J., … & Zhang, X. (2010). Search Behaviors in Different Task Types. Proceedings of the 10th Annual Joint Conference on Digital Libraries, 69–78.
- Li, Y. (2008). Relationships among work tasks, search tasks, and interactive information searching behavior. Unpublished doctoral dissertation. Rutgers University, New Brunswick, NJ, USA.
- Litman, D.J. & Silliman, S. (2004). ITSPOKE: An intelligent tutoring spoken dialogue system. Proceeding of HLT-NAACL --Demonstrations '04. 5-8.
- Johnsen, M. H., Svendsen, T., Amble, T., Holter, T. & Harborg, E. (2000). TABOR-a norwegian spoken dialogue system for bus travel information. Proceeding of ICSLP 2000, 1049-1052.
- Marchionini, G. (1989). Information-seeking Strategies of Novices Using a Full-text Electronic Encyclopedia. Journal of the American Society for Information Science and Technology, 40(1), 54–66.
- Murdock, V., Kelly, D., Croft, W. B., Belkin, N. J. & Yuan, X. (2007). Identifying and Improving Retrieval for Procedural Questions. Information Processing & Management, 43(1), 181–203.
- Oulasvirta, A., Engelbrecht, K. P., Jameson, A. & Moller, S. (2006). The relationship between user errors and perceived usability of a spoken dialogue system. Proceeding of the Second ISCA/DEGA Tutorial and Research Workshop on Perceptual Quality of Systems, 61-69.
- Patel, N., Agarwal, S., Rajput, N., Nanavati, A., Dave, P. & Parikh, T. S. (2009). A Comparative Study of Speech and Dialed Input Voice Interfaces in Rural India. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, 51–54.
- Portet, F., Vacher, M., Golanski, C., Roux, C. & Meillon, B. (2013). Design and evaluation of a smart home voice interface for the elderly: acceptability and objection aspects. Personal and Ubiquitous Computing, 17(1), 127-144.
- Qiu, L. (1992). Analytical Searching vs. Browsing in Hypertext Information Retrieval Systems. Canadian Journal of Information and Library Science, 18(4), 1-13.
- Salber, D. & Coutaz, J. (1993). Applying the Wizard of Oz technique to the study of multimodal systems. In L. J. Bass, J. Gornostaev, & C. Unger (Eds.), Human-Computer Interaction (pp. 219–230). Springer Berlin Heidelberg. Retrieved from http://link.springer.com/chapter/10.1007/3-540-57433-6_51.
- Toms, E. G., O’Brien, H., Mackenzie, T., Jordan, C., Freund, L., Toze, S., … MacNutt, A. (2008). Task Effects on Interactive Search: The Query Factor. In N. Fuhr, J. Kamps, M. Lalmas, & A. Trotman (Eds.), Focused Access to XML Documents (pp. 359–372). Springer Berlin Heidelberg. Retrieved from http://link.springer.com/chapter/10.1007/978-3-540-85902-4_31
- Wildemuth, B. M. (2004). The Effects of Domain Knowledge on Search Tactic Formulation. Journal of the American Society for Information Science and Technology, 55(3), 246–258.
- Zue, V., Seneff, S., Glass, J. R., Polifroni, J., Pao, C., Hazen, T. J. & Hetherington, L. (2000). JUPlTER: a telephone-based conversational interface for weather information. IEEE Transactions on Speech and Audio Processing, 8(1), 85–96.