Qualitative interpretative categorisation for efficient data analysis in a mixed methods information behaviour study
Peter Stokes
Anglia Ruskin University, Peterborough, PE2 9PW, UK
Christine Urquhart
Aberystwyth University, Department of Information Studies, Aberystwyth, SY23 3AS, UK
Introduction
Mixed methods research has its advocates (Creswell and Plano-Clark 2011; Johnson et al. 2007; Morgan 2007) and detractors (Giddings 2006; Symonds and Gorard 2008) but the research method has been used widely (Bryman 2008; Lipscombe 2008). Morgan (2007) refers to mixed-methods as a 'pragmatic' approach as during the design of research, data collection, and data analysis 'it is impossible to operate in either an exclusively theory or data-driven fashion' (Morgan 2007: 71). Teddlie and Johnson (2009) concur that pragmatism is the philosophical partner for mixed-methods that embraces and synthesises ideas from both sides (quantitative and qualitative). Patton (2002) agrees that pragmatism, that is, being adaptable and creative, is a valid approach as gathering the most relevant information outweighs methodological purity. The pragmatic approach relies on abductive reasoning that moves back and forth between deductive (quantitative) and inductive (qualitative) reasoning. Pragmatism is pluralist as it accepts the variety of competing interests and forms of knowledge, allowing knowledge to be evaluated according to whether it works in relation to a particular goal (Cornish and Gillespie 2009); focusing on what practical difference can be made, and whether any theory or idea is successful in accomplishing a desired effect (Baert 2005). By using both quantitative and qualitative methods in a pragmatic approach, a deeper, richer understanding of the information seeking process could be attained. This is in line with the definition of mixed methods as offering 'a powerful third paradigm choice that often will provide the most informative, complete, balanced, and useful research results' (Johnson et al. 2007: 129). This paper discusses the development of an efficient approach to qualitative analysis that fits within a mixed methods study of information behaviour. The findings illustrate how qualitative interpretative categorisation offers an efficient framework for analysing the qualitative component of a mixed methods study that is primarily quantitative in approach.
In many information behaviour studies the mixed methods approach may simply take the form of a questionnaire survey (mainly quantitative) with some open ended questions included for qualitative analysis – the aim being to provide confirmation and explanation, for example, to clarify some of the reasons the searchers had for the strategies and changes made as their searches progressed on various types of task (Kim 2009). Mason and Robinson (2011) used some open-ended questions in an online survey of the information behaviour of artists and designers. The quantitative and qualitative elements operated simultaneously in this case. The Mason and Robinson (2011) approach was theoretically based (on previous research on artists). Other examples of a largely quantitative approach, with qualitative elements providing explanation, include the research by Xie and Joo (2010) that used qualitative diary data to illuminate reasons for using, or not using various Web search tactics, in a primarily quantitative study of the frequency of use of various search tactics. Kwon (2008) used validated instruments for critical thinking and library anxiety for the quantitative component of a study examining the relationships between critical thinking and library anxiety. Student essays were analysed qualitatively to explain how these relationships developed, and how emotions (and critical thinking disposition) affected how students coped with library anxiety. The qualitative and quantitative approaches are integrated closely in such research as the rationale for a longitudinal study of student information behaviour explains (Rowley and Urquhart 2007). The model that was produced in the latter project required findings from both the quantitative and qualitative components of the research; the qualitative data were certainly necessary in providing the justification and explanation (Urquhart and Rowley 2007). The quantitative element also provides the background context for other mixed methods studies in information behaviour that may be primarily interpretive/constructivist (e.g. Williamson 2008).
More unusually, quantitative analysis may be possible on a large qualitative data set. This happened with Urquhart and Rowley (2007), with the complementary quantitative data collection used to refine the information seeking model. Lu (2010) lacked an available strong theoretical framework for children's coping and information seeking in daily life, and therefore used qualitative methods to collect and analyse the data. The size of the data set (641 interviewees) allowed some quantitative analysis to help understand the effect, for example, of gender and grade level, as well as some of the emergent factors.
When reviewing the previous decade of information behaviour research for Information Seeking in Context conferences, Vakkari (2008) noted a trend towards varied, but generally descriptive qualitative research. If (more unusually) qualitative and quantitative research were combined, this usually took the form of qualitative research being used to derive the factors and categories, which were then subjected to some quantitative analysis. Pragmatism, as a general philosophy, might be predominant in the type of questions asked, and the approach used. Theory and model testing are more difficult if there is no suitable theory to use. Theory may, of course, also be generated through qualitative research, through grounded theory, but proper application of grounded theory seems very mixed in studies of information behaviour (Gonzalez-Teruel and Abad Garcia 2012). A study of reviews of information behaviour research (Urquhart 2011) testifies to the wide range of inquiry paradigms used, and the difficulty, sometimes, of identifying which are used, and why. Despite the increasing representation of qualitative research for the ISIC conference, Urquhart noted that in the general literature on information behaviour, cognitive (and quantitative) approaches are still comparatively common.
Deciding on the most appropriate mixed methods approach for an information behaviour research study may depend on the research question (Teddlie and Tashakkori 2009). It seems sensible, given the occasional lack of transparency about operating paradigms in information behaviour research, to at least state which paradigm is the main operating paradigm for the mixed methods study (Crotty 1998). Next, decisions should be made about the data collection methods and their timing, particularly the relationship between qualitative and quantitative data collection methods. The third step involves decisions about the synthesis and integration of the data collected. This mixed methods study aimed to produce a profile of information seeking behaviour in nursing students. A concurrent embedded mixed methods design was used, a design in which one data set provides a complementary role in a study based primarily on the other data set.
In this study, the main operating paradigm was post-positivist. The qualitative data collection and analysis served to check and critique both the truth of the findings of the quantitative research, and the assumptions made in the quantitative research. The literature suggested that several types of factors were important, but the study aimed to go beyond identification of one factor as more important than another. The aim was to provide a profile, where the qualitative research could bring meaning, a human face to the profile, through integration of the quantitative and qualitative data.
During the process of collecting and analysing the data, a particular technique, termed as qualitative interpretative categorisation was developed for the mixed-methods research project (see outline in Stokes 2008). This paper provides a brief synopsis of the research project, before discussing the methodology used for the qualitative data analysis.
Background
Phase one, the quantitative component of the study, used a questionnaire containing validated research tools, as well as a set of questions based on Foster's non-linear model of information seeking (Foster 2005), which predicts that individuals search using a range of different methods in a non-linear process. The aim of the questionnaire was to determine whether either personality, self-efficacy, or learning style impacts on the information seeking behaviour of nursing students (n=194). Phase two was to gather qualitative interview data examining the information needs and seeking processes of a smaller sample (n=11) of nursing students.
Ideally, the interview schedule would have been designed in detail once findings from the quantitative component had been analysed, but in practice this was impossible, as the ethical review for the study dictated that an interview schedule be developed prior to quantitative data collection. There were also sampling constraints as time pressures dictated that all participants for the study were approached at the same time for both parts of the study.
Initial findings from part one have already been reported (Stokes and Urquhart 2011) and addressed the following two research questions:
- Phase 1: Quantitative
- What is the relationship between personality, self-efficacy, learning styles, and information seeking behaviour?
- What is the impact of differing personalities, self-efficacy levels, and/or learning styles on information seeking behaviour?
The aim of the qualitative part of the study was to investigate the search processes of nursing students, to answer the following questions:
- Phase 2: Qualitative
- Why do users search the way they do?
- What are the preferred methods of information seeking?
It should be emphasised that the word search here refers more to the strategy taken, not to the mechanics of information system use. The interviews were not concerned with which particular resources were used and in what order. The emphasis was on why students might feel more comfortable with certain sources, what their information seeking routines might be, and how they felt about these routines throughout the process of doing a search or set of searches for a particular project assignment. The types of information behaviour that were studied were initially assumed to be Kuhlthau's stages of initiation, selection, exploration, formulation, collection and presentation (Kuhlthau, 1991) but we would later relabel the final stages as 'collection and evaluation' and 'presentation and ending' to describe the emphasis of the questions better. In this context seeking is focused on the identification of sources.
The final phase of the study (not presented here) links the two previous phases and addresses the following research question:
- Phase 3: Mixed
- How do the qualitative findings enhance the understanding of the quantitative results?
A concurrent, embedded study allows either the comparison of the two sets of data or for them to reside side by side as 'two different pictures that provide an overall composite assessment of the problem' (Creswell 2009: 214). This latter approach is taken in this study, as Creswell suggests that this type of study can address different research questions.
Development of methodology
Introduction
The qualitative analysis pragmatically synthesises elements of the work of Burnard (1991), Miles and Huberman (1994) and Sandelowski (2000, 2010), with the critical incident technique (Flanagan 1954) to provide an overall technical framework of analysis termed qualitative interpretative categorisation. The framework is adaptable to different situations and research requirements and can be neatly applied when time pressures are a factor. All four of these research approaches are described and then summarised in Table 1 which shows the contribution of each approach. Figure 1 shows the iteration involved in the stages of data analysis.
Critical incident technique
The critical incident technique is a systematic, inductive method that involves collecting descriptions of events and behaviours. Once collected they are grouped and analysed using contextual, content or thematic analysis (Aveyard and Neale 2009). The critical incident technique was originally developed by Flanagan (1954) as part of the US Army Air Forces Psychology Program to describe successful and unsuccessful bombing missions. An incident is 'any observable human activity that is sufficiently complete in itself to permit inferences and predictions to be made about the person performing the act' (Flanagan 1954: 327). To be critical
'an incident must occur in a situation where the purpose or intent of the act seems fairly clear to the observer and where its consequences are sufficiently definite to leave little doubt concerning its effects' (Flanagan 1954: 327).
Critical incidents can be recorded by a variety of methods, but 'the face-to-face interview format is the most satisfactory data collection method for insuring that all the necessary details are supplied' (Kemppainen 2000: 1265). In the late 1990's the JISC usage surveys trends in electronic information services projects used this method to examine the uptake of electronic information sources (Urquhart et al. 2004; Urquhart et al. 2003); and it has been used in medical research (Bradley 1992). The critical incident technique is suited to nursing research as it relies on reflection and interviewing is aligned to the oral culture of nursing practice (Schluter et al. 2008). It is therefore not surprising that it has been well used in this field. The establishing the value of information to nursing continuing education project (Urquhart and Davies 1997) used the critical incident technique to examine the patterns of information need amongst hospital and community nurses; and it has been used to capture the experiences of nurses from differing areas (Keatinge, 2002; Perry, 1997). Elsewhere the critical incident technique has been used to determine the quality of nursing care from both the nurse and patient perspective (Norman et al. 1992; Redfern and Norman 1999) and to explore the spiritual needs of patients (Narayanasamy and Owens 2001). Within nursing education the critical incident technique has been used recently to explore student nurses' perceptions of language awareness (Irvine et al. 2008), and the meaning of empowerment for nursing students within their clinical areas (Bradbury-Jones et al. 2007).
According to Flanagan (1954) there are five steps involved in conducting a critical incident technique investigation:
Stage 1: Give a clear statement of what is being investigated.
Stage 2: Specify inclusion criteria.
Stage 3: Collect data.
Stage 4: Analyse the data.
Stage 5: Interpret the data.
In this study a clear statement is given at the start of the interview outlining the aspects under exploration. Supplementary probes attempt (if necessary) to elicit additional information if the participant appears hesitant or the response is lacking in detail. Because the incident is chosen by the interviewee, and it is based on real events, this allows areas not considered by the interviewer to be explored. In addition Chell (2004) notes that as incidents are critical this aids recall, and the critical incident technique provides a focus for the researcher to probe and which the interviewee can concentrate upon (Chell 2004). This research uses semi-structured interviews rather than structured interviews as this allows questions not listed in the guide to be asked (Bryman 2008).
One nurse who had recently graduated agreed to take part in a pilot study to test face validity of the interview schedule. No changes to the schedule were deemed necessary, but it did enable the researcher to mould supplementary questions and probes for the interviews.
The interviews were tape recorded and transcribed in full into NVIVO 8 software for analysis. Each interview took place at a single site in a single location at different times, with the duration ranging from just over 15 minutes to almost 25 minutes. The interviews were taped, subsequently listened to a single time, and transcribed in full.
Qualitative interpretative categorisation – the main steps
Qualitative interpretative categorisation data analysis steps were then followed to identify underlying themes in relation to the objectives identified at the outset and the qualitative research questions. The justification for the stages involved is discussed below.
Burnard's (1991) stage by stage method of data analysis for semi-structured interviews was used as a base. His method assumes that semi-structured interviews are recorded in full and the whole recording is transcribed. Although many commentators advocate the use of reliability checks by peers as a method of enhancing rigour (Cohen and Crabtree 2008; Tobin and Begley 2004) in coding, it could be construed that as the analysis is necessarily interpretive then different individuals will likely interpret that dataset differently. Other researchers suggest that the provision of sufficient detail in the theoretical and analytical decision making process and representation of as much of the data as possible is sufficient to provide reader verification (Chenail 1995; Constas 1992; Horsburgh 2003; Koch 2006). As Piper (2004) states, "verification hinges on the reader being able to see how the text was constructed and not on shared interpretation" (Piper, 2004: 156). For a team project, two people could share the coding, but if only one person is responsible for coding, then the use of data display methods would help to explain the decisions made on description and interpretation.
Miles and Huberman's (1994) qualitative analysis approach provided a framework for the processes of coding and data display. This approach focuses on three components that take place concurrently throughout the analysis:
- Data reduction: this component encompasses the way the data (transcript) is analytically coded (reduced) without losing the context. It is a 'form of analysis that sharpens, sorts, focuses, discards, and organizes data…that conclusions can be drawn' (Miles and Huberman 1994: 10).
- Data display: this moves the analysis forward with the use of displays (diagrams, charts, models). It runs alongside the data reduction component as part of the analysis, and in addition forms part of the data reduction.
- Drawing conclusions: again this component happens continuously throughout the process. Early conclusions may be vague but are verified during the analysis.
As there are specific research questions to address, a-priori categories were developed to encourage the researcher to look out for particular aspects within the data, providing initial focus. Miles and Huberman advocate a provisional start list of categories generated from the research questions (Miles and Huberman 1994), a strategy often used in the health sciences (Creswell 2009), and supported elsewhere (Constas 1992; Dey 1993).
The start list is precisely that: it is not considered (until the research project is completed) to be a final list, acting rather to allow groupings to develop or become evident throughout the coding process. Data that do not fit are left temporarily free. Further coding may then identify a category for this free chunk of data thus modifying the start list table. This type of data analysis is similar in intent to template analysis (King 2004) which uses (as the name suggests) a template of hierarchical categories that are amended, refined, deleted as the analysis takes place. Template analysis however differs from qualitative interpretative categorisation in that it is restricted to the data analysis stage and the template contains more than just the highest order categories. In addition (as will be described later) it does not make use of any data display techniques other than the template itself.
The start list of a-priori categories (Table 1) was generated both from the two research questions and the interview schedule which itself was derived from the research questions.
Research question 1 (RQ1): Why do users search the way they do?
Research question 2 (RQ2): What are the preferred methods of information seeking?
The interview questions are listed below. For IQ6 the additional probes are given as they are the only reference to critiquing.
Interview question 1 (IQ1): CRITICAL INCIDENT TECHNIQUE
Please tell me about one entire project from a title or area through to completion: Please tell me about the activities and places that you look as you progress through a literature search. By all means take a moment to think back to where you were and who you consulted about this.
Interview question 2 (IQ2): Do you feel that you changed the way you search from the beginning of your search and as you move through? How did your priorities change?
Interview question 3 (IQ3): How does this search compare with other searches you have done before or after this time? If you searched differently in the past, why do you think you changed? If you now search differently – why have you subsequently changed?
Interview question 4 (IQ4): Where would you look for information? Who would you ask – and why?
Interview question 5 (IQ5): How do you identify new or useful information sources?
Interview question 6 (IQ6): When are you satisfied that you have enough information and can therefore move on to a new question, activity or different way of searching? How do you judge when enough is enough? (Probes: quantity, match with perceived needs for assignment, expectations of number of references, try to tease out how any interpolation is done, any critique of the information in the items retrieved, putting it all together.)
| Name of category (Start list) | Rationale for category | Relates to? |
|---|---|---|
| Amount of information | What is the amount of information a student needs before moving on to something else, or starting the assignment? | RQ1, IQ1, IQ6 |
| Confidence | Are students more or less confident now than before? | RQ1, IQ2, IQ3 |
| Critiquing | Do students critique articles or take them at face value? (Academic tutors within health faculties emphasise critical appraisal of literature, and selection of quality evidence.) | RQ1, RQ2, IQ6 |
| Relevancy | How do students determine what is or isn't relevant? | RQ1, RQ2, IQ5 |
| Satisfaction with searching | Why are students either satisfied or dissatisfied with their search? | RQ1, RQ2, IQ6 |
| Searching techniques | What techniques do students employ in their searches? | RQ1, RQ2, IQ1, IQ2, IQ4, |
| Sources used | What sources are used to find information? | RQ1, RQ2, IQ1, IQ4, IQ5 |
The qualitative analysis would ideally be conducted after the quantitative analysis to allow time for the researcher to mentally detach from the first set of findings and avoid the first set of results intruding on the subsequent analysis. In team projects those responsible for the qualitative component would not be involved in the analysis of the quantitative survey.
Classifying data into discrete groups using hierarchical cluster analytic techniques is suited to research where the number of groups is not certain. Its exploratory nature allows relationships and principles between the groups to manifest through the research (Beckstead 2002). Using a-priori categories also lends itself to the development of taxonomic structures (Bradley et al. 2007) to classify multifaceted phenomena according to a set of conceptual domains. Dendrograms for clustering of concepts from specific to general can be used, a process that not only highlights the relationship between concepts but also how they have been grouped. Whilst usually computer generated from content analysis and depicting quantitative results (Beckstead 2002), a dendrogram can be used as a means of purely depicting a hierarchical display. This clustering can form part of the data display component of the analysis. The data reduction component in Miles and Huberman's (1994) strategy is similar in technique to Burnard's (1991) stages 3-5 in which categories are developed and streamlined. There are other methods of data display, of course, and post-it notes or labelled cards might be used if software is not easily available.
The data analysis emphasised qualitative description (also termed 'thematic surveys' (Sandelowski 2010; Sandelowski and Barroso 2003)). This type of study uses a method of analysis that entails the presentation of the facts in everyday language, whilst allowing a level of interpretation of the data; and is amenable to obtaining straight and largely unadorned answers to questions of relevance to practitioners (Sandelowski 2000). In this method Sandelowski suggests that data collection (usually via semi-structured interviews or focus groups) is directed toward discovering the 'who, what, and where, of events and experiences' (Sandelowski, 2000: 338), with content analysis the preferred technique. It is also suggested that a 'targeted event' be employed as a focus; and that pre-existing codes (or a framework for analysing the data (Sandelowski, 2010) can be used as long as they are modified during the course of the analysis. In this case the critical incident technique provided the 'targeted event'. Again the development and modification of codes reflects both Burnard's (1991), and Miles and Huberman's (1994) techniques of data reduction and clustering. The outcome of the study should then be presented in descriptive summaries.
Table 2 illustrates the fit between the three main contributors to the data collection and analysis methodology for the qualitative interpretative categorisation framework. The later stages (6-14) of Burnard (1991) are included in the table (in italics), but the main contribution of Burnard was for the earlier stages of data collection and analysis (up to stage five). The later stages seem more appropriate for research projects that are purely qualitative.
| Qualitative interpretative categorisation | Burnard | Miles and Huberman | Sandelowski |
|---|---|---|---|
| Initial categorisation from research questions for start list | Pre-existing codes may be used as a start list | Pre-existing codes may be used as a start list | |
| Note taking and close reading | Close reading and note taking (stage one) Open coding (stage two) |
Modification of codes during analysis – reading and reflection | |
| Reflection on reading, organising data into themes according to start list Filling out categories with themes, reorganisation | Immersion in the data (stage three) Developing broader categories (stages four and five) words and phrases grouped together (reduced) | Data reduction | Identification of patterns |
| Checking coherence of themes within revised categories Clustering | Developing broader categories (stages four and five) | Data reduction and display | Checking description is coherent and comprehensive |
| Development of dendrograms via data clustering | Guarding against bias (stage six) Establishing categories cover all aspects (stage seven) |
Conclusion (tentative) | Minimal interpretation, recourse to theory not essential |
| Assembly of final set of categories and dendrograms | Recoding as necessary (stages eight and nine), individual analysis (stage ten), validity check (stage eleven), organisation and writing up (stages twelve to fourteen) | Conclusion and verification | Checking that summary meets the needs of the audience |
The complete framework can be shown schematically (Figure 1) using Creswell's (2009) data analysis process overview (seven boxes on the left hand side of the diagram) as a base. Figure 1 emphasises the reflexive and interactive nature of the coding, data reduction, data display processes.
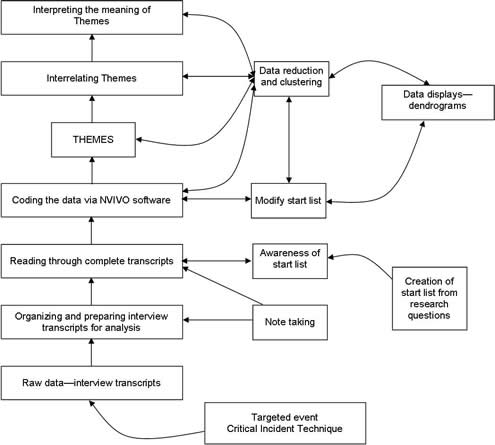
Creswell also suggests that his general framework should be blended with the specific research strategy steps. The blending of Creswell's general data analysis framework with the qualitative interpretative categorisation process provides a complete technical framework for the qualitative research analysis undertaken in this study. The starting point for data collection is the use of the critical incident technique.
Category development - discussion
The first steps of the coding involved emphasis on close reading and faithful description of the events in the transcripts. This was in line with Burnard's (1991) open coding principles (Table 1). The first steps also tried to map some of the new codes assigned to the initial start list of categories, but this was a reflexive, and interactive process (as indicated by Sandelowski (2000) - Table 1). It became clear early in the analysis that a separate category for 'searching differently' was required and as such a new category 'revision of searching' was created. This category pulled some data from the 'search techniques' category which was becoming overloaded with separate search strategies. Changes in the search process as the search progresses remained within the 'search techniques' category, but the category was renamed to the broader 'search strategy' to better indicate that the data within included both the initial search and the follow up. In addition the 'critiquing' category was excluded as this generally received a 'yes/no' response and did not yield any significant further information. These changes are outlined in table 3. The interview transcripts were checked to ensure that the interviewees were not using different words to describe the phenomenon.
| Initial start list | Final categories |
|---|---|
| Amount of information | Amount of information |
| Confidence | Confidence |
| Critiquing | |
| Relevancy | Pertinence |
| Revision of searching | |
| Satisfaction with searching | Satisfaction with searching |
| Searching techniques | Search strategy |
| Sources used | Sources used |
Within the search strategy category an initial sub-category of problems with searching appeared to be mainly keyword searching and could be included within satisfaction with searching as this had a sub-category of keywords. This then became the sub-category keyword selection within the dissatisfaction element of the whole category. Excerpts from the transcripts include: 'I think a problem I did encounter was the keyword focuses' and 'Sometimes if you put in keywords and it doesn't… it comes up with something totally different you think "Oh that's not for me" so you close it down and click on the next one'.
In addition relevancy became a sub-category within the category pertinence to better indicate the precise bearing of the retrieved document in relationship to the information need. Relevancy might seem the obvious term to an information professional, but close reading of the transcripts indicated that the students perceived information seeking priorities differently.
Creation and utilisation of nodes took place throughout, but it was the use of the dendrograms that enabled these to be grouped as each transcript was analysed. Tentative groups could be confirmed with additional analysis of transcripts. Dendrograms can be generated within NVIVO, and are often used as a cluster analysis technique to explore patterns within the data. Sources or nodes in the cluster analysis diagram that appear close together are more similar than those that are far apart. the example in Figure 2, the dendrogram was organised chronologically, as this suited the emerging pattern within the data.
The sets of results were then laid out in separate categories each with a dendrogram indicating the nodal structure within the category. The initial start list of categories showed minimal amendments with only three significant alterations (Table 3). The themes (nodes) within the category provide a much fuller description of the content of the category.
Example dendrogram: amount of information
The amount of information category contains nodes pertaining to the student's perception of the quantity of information needed for an assignment with nodes grouped into sub-categories of: at the start, the initial stages, and at the end (Figure 2). This category differs from revision of searching which covers searching for different information or topics or a different method of searching.
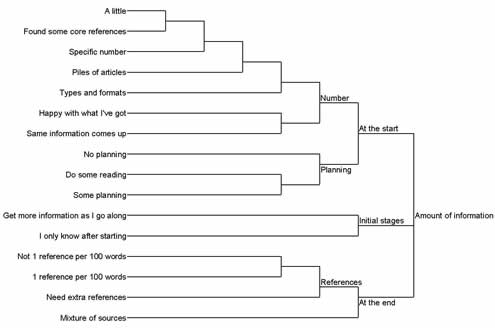
What became clear from the interviews was a difference between the amount of information needed at the start of the assignment compared to at the end. There was an emphasis on getting only a few quality references to get going, but then a desire to have plenty of references at the end – more quantity. There was also a general feeling of needing one reference per 100 words.
Current analysis of the seven categories has enabled the development of an information seeking process model based on Bystrom and Jarvelin's (1995) task-based model. This model, on reflection, was a better fit for the qualitative data, than the Kuhlthau (1991) model. It is envisaged that the information seeking profiles that are being re-evaluated as part of the mixing stage of the study will feed into this model to create an information seeking framework.
Discussion
So why bother blending techniques? What is the rationale? Why not use a pre-existing research framework of one of the traditional types of qualitative research for example: grounded theory or phenomenology?
Simply put, these methods do not fit. In fact, no single type of qualitative method does fit this research. There is little point trying to 'shoehorn' a method into line to fit the research. Both grounded theory and phenomenology contain aspects that are either not possible to do or irrelevant. For example, to do grounded theory properly requires theoretical sampling which was not possible because of the demands of ethical review. Equally, as phenomenology is concerned with the 'lived experience' it would focus on how students 'felt' about information seeking rather than what they actually did. The research here blends from a pragmatic methodological perspective various well known approaches to data collection and analysis, to generate a new framework that can be applied in specific situations where the researcher is constrained by time pressures, or simply wants a pragmatic, rather than a highly interpretive approach. This research is also pragmatic as the evidence should help the design of information literacy programmes for nursing students.
Our research could be considered to fall within the compass of generic qualitative research defined as exhibiting characteristics of qualitative endeavour (Caelli et al. 2003). However rather than focusing on a known methodology, generic qualitative research either combines several methodologies or approaches, or claims no methodological viewpoint at all (Caelli et al. 2003). Our research also could be described as basic interpretive in which data are 'inductively analysed to identify recurring patterns or common themes that cut across the data' (Merriam, 2002: 7). Having no defined boundary for the type of research method used in the research reflects Sandelowski's (2010) view that efforts to define and generalise do not capture the variations in the actual practice of methods; and that there is no perfect execution of any method as methods are always accommodated to the real world of research practice and are therefore reinvented. As Patton states 'because each qualitative study is unique, the analytical approach will be unique' (Patton 2002: 433). Having no clear canonical path also allows flexibility in the application of methods to appropriately answer research questions (Chamberlain 2000) preventing methodolatry, the overemphasis on selecting and describing methods that overtakes the story being told (Janesick 2000). Avis (2003) goes further to suggest that methodological theory can be overemphasised to the detriment of the research process and that method should not be used to justify production of evidence that 'closes off critical scrutiny of the evidence by locating it as internal to a particular methodological theory' (Avis 2003: 1004). This is in line with Miles and Huberman's pragmatic statement that any method that produces 'clear, verifiable, credible meanings from a set of qualitative data – is grist to our mill' (Miles and Huberman 1994: 3).
For many, the world of qualitative research may seem very complex. One prominent qualitative researcher has described the field as 'unhelpfully fragmented and incoherent' (Atkinson 2005). Atkinson stresses the values of formal analysis, 'preserving and respecting the different layers of action and representation through which cultures are enacted and social action is performed' (Atkinson 2005: para 20). In this research, the intention was to reach a fuller understanding of the information seeking of nursing students. That means trying to see the situation from the perspective of the student, as well as appreciating where the assumptions of those designing an information literacy programme come from. For example, we had assumed that students might talk about evaluation of the information obtained, and the development of their critical thinking, as many of the information literacy models, and their academic tutors assume. However, interviews revealed that students were often more concerned with the weight of evidence in a different way, finding enough justification for their arguments. There are layers of action (students doing assignments, academics designing programmes of study, librarians designing and conducting information literacy programmes), and many activities, and professional (or other) assumptions that are associated with these sets of actions. It is important to stress that though the names for the initial category and the final category have not changed; the final category is much more closely defined and redefined than the initial category, which was, simply, a rather flat label. To cite Dey (1993: 102):
The meaning of a category is therefore bound up on the one hand with the bits of data to which it is assigned, and on the other hand with the ideas it expresses. These ideas may be rather vague at the outset of the analysis. The meaning of a category is something that evolves during the analysis, as we make more and more decisions about which bits of data can or cannot be assigned to the category.
It is possible that dendrograms might be more difficult to manage manually with a larger number of interviewee transcripts to handle, but there are software programs that can help in the process of creating a workable dendrogram with larger datasets. For information behaviour research, and when working with a strong structure such as the narrative structure underpinning the critical incident technique, there seems less risk of additional complexity.
Conclusions
This paper has set out the rationale and justification for the development of the qualitative interpretative categorisation method that can be pragmatically used in a range of situations. It is particularly well suited to concurrent mixed-method studies where the researcher is constrained by time pressures, or the research is the responsibility of a team. The method therefore offers a systematic way of dealing with interview data obtained alongside survey data in research done by practitioners. Using this approach encourages proper interrogation and questioning of the data, avoiding the risk of fitting the data to preconceived assumptions.
Some researchers may prefer the integrity of an approach developed by one researcher, and might criticise the qualitative interpretative categorisation as a 'pick and mix' approach. In some ways that is what it is, but the intention was to develop a systematic approach to data analysis that was informed by previous critiques of qualitative research. The approach emphasises the data display and data reduction possibilities of dendrograms. Such visual methods make the generation of categories a more transparent process, and this is helpful in many situations where the information behaviour research findings need to be explained to practitioners.
Acknowledgements
The overall research project received funding from the Arts and Humanities Research Council.
About the authors
Peter Stokes is a Subject Librarian at Anglia Ruskin University, Peterborough, UK. He received his Masters in Health Information Management from Aberystwyth University and is currently undertaking a PhD at the same university. He can be contacted at: peter.stokes@anglia.ac.uk
Christine Urquhart has directed several studies of information seeking and use in the health sector and also co-directed a longitudinal study of the impact of electronic information services on the information behaviour of students and staff in UK higher and further education. She also prepares systematic reviews for the Cochrane Collaboration, principally the Effective Practice and Organization of Care group and is a co-author of reviews on nursing record systems and telemedicine. She was Director of Research in the Department at Aberystwyth for several years and established the training programme for doctoral students. She can be contacted at cju@aber.ac.uk