Guardians of the knowledge: relevant, irrelevant, or algorithmic?
Lala Hajibayova
Introduction. We investigate how information retrieval systems, particularly algorithms underlying information retrieval systems, facilitate use of an individual's subject knowledge in the assessment of relevance.
Method. Floridi's conceptualization of information ethics is applied to argue that in order to ensure fair and equitable representation and discovery of information, the ethical norms and standards applied to the biosphere should be extended to information environments.
Analysis. We critically analyse the systems of knowledge representation, organization and discovery through the lens of the theory of relevance to determine whether it sheds light on our understanding of algorithmic relevance.
Results. We argue that an individual's situated perception of relevance should be considered in relation to the algorithmic criteria of relevance to ensure accountable, fair, equal, transparent and, most importantly, ethical assessment of relevance of discovered information. Conclusion. This paper contributes to explicating the role of algorithmic relevance in information representation, organization, and discovery. We argue that Floridi's conceptualization of information ethics from an ecologically-oriented perspective aligns with the ideal of accountability, fairness, equality and transparency in representation, organization and discovery systems. Placing emphasis on the human side of representation, organization and discovery reinforces the ethical norms associated with fair access to knowledge through all processes involved.
Introduction
In June 2016, an 86-year-old British woman's polite Google search statement asking for a translation of the Roman numerals MCMXCVIII, starting with please and ending with thank you, went viral, making billions of Internet users smile (Holmes, 2016). Even though research suggests that formulating information search needs as if engaging in a conversation with a fellow human may potentially improve users' search satisfaction and the effectiveness of the search process (e.g., Hoenkamp and Bruza, 2015), balancing precise and accurate expression of information needs with use of everyday language can be quite challenging. Most importantly, this humorous incident made us once again think about how information discovery systems assess the everyday language of a diverse Internet population and discover the relevant information.
Moreover, taking into consideration the inherently textual nature of information representation, organization and retrieval, the question is how one's assessment of the subject relevance that is based on one's knowledge and/or understanding of the particular subject and task or goal at hand, as well as situated conceptualization of the subject within one's current subjective state (e.g., emotions, time, space) interplays with the algorithms behind the discovery systems. People, objects and events that we encounter on an everyday basis, as well as choices of language to represent these encounters, do not fit neatly into discrete categories (Hajibayova and Jacob, 2015, 2016). A friendly neighbour next door might simultaneously be a woman, a physician, a writer, a Cubs fan, and a Chicagoan, just to name a few identities.
In fact, we do not feel that one category is the only one or the best one: rather, different categories are most relevant or useful at different times (Murphy, 2004). While cognitive efficiency may underlie the use of everyday vocabulary, the theory of situated action suggests that individuals' actions depend on a 'complex world of objects, artefacts, and other actors, located in space and time', however this complex world is not an 'extraneous problem', but the 'essential resource that makes knowledge possible and gives action its sense' (Suchman, 2007, p. 177). However, it is unclear how an individual's preferences in utilizing everyday language in information seeking is interpreted in discovery systems, specifically, how the algorithms underlying discovery systems define relevance based on one's information search query. Moreover, taking into consideration the centrality of individuals' subject knowledge in the assessment of relevance, the question remains as to how information retrieval systems; in particular the algorithms behind the information retrieval systems, facilitate use of an individual's subject knowledge in the assessment of relevance.
Beer states that algorithms are 'being produced from a social context... [T]hey are [an] integral part of that social world' and 'woven into [its] practices and outcomes' (Beer, 2017, p. 4). Therefore, it is important to understand how algorithms shape organization, institutional, commercial and governmental decision-making. In relation to Beer's point, this paper aims to contribute to explicating the role of algorithms in information representation, organization and discovery systems.
The following discussion is structured as follows: first, we define and provide an overview of studies on algorithms, and then we utilize Floridi's conceptualisation of information ethics to argue that in order to ensure fair and equitable representation and discovery of information, the ethical norms and standards applied to the biosphere should be extended to information environments 'to sensitize humanity to the new ethical needs' (Floridi, 2002, p. 45).
Algorithms and algorithmic culture
A shift of computer technologies from being explorative and easy to open up to being exploitive and closed black boxes, coupled with greater and more powerful yet opaque platforms has resulted in the increased power of computer technologies (Turkle, 2005). Thus, inevitably, we become enmeshed in a data driven culture or, in Galloway's (2006) terms, the algorithmic culture that often makes the key life decisions for us that range from a seemingly simple recommendation of relevant search result to more complex decisions associated with identifying people as potential criminals, deciding on loan eligibility, trading stocks at unimaginable speed, and shaping the news feeds (e.g., Beer, 2009; Bucher, 2012; Gillespie, 2018; Hallinan and Striphas, 2016; Seaver, 2018).
Gillespie notes, 'in the broadest sense... [algorithms] are encoded procedures for transforming input data into a desired output, based on specified calculations' (Gillespie, 2014, p. 167). Dourish, drawing on conceptualization of algorithms in the domain of computer science, explains that an algorithm is an 'abstract, formalized description of a computational procedure' (Dourish, 2016, p. 3). Algorithms are differentiated based on their properties, such as probabilistic algorithms, which produce results within particular bounds of certainty, and analytic characteristics, that is, generalized performance characteristics of, for instance, how mean-time performance varies with the size of the data over which it operates (p. 3). Dourish asserts that algorithms do not possess 'stable technical identity', but are determined by 'social engagements rather than by technological or material constraints' (p. 3). For Dourish, concern is not with algorithms as such, but with a 'system of digital control and management achieved through sensing, large-scale data storage, and algorithmic processing within a legal, commercial, or industrial framework that lends it authority' (p. 3).
In this vein, Gillespie points that in order to prevent individuals from seeing how content is 'protected and potentially circumvented... technology designers... "weld the hood shut" – something very much at odds not only with open source design, but with the traditions of user appropriation and innovation' (Gillespie, 2007, p. 18). Yeung (2017) contends that the 'naïve faith in algorithmic accountability' totally ignores the opacity of the underlying algorithms and, overall, dominance of a handful of powerful providers of online services for interplay of market rules. Along these lines, Striphas states that due to 'private, exclusive and indeed profitable' algorithmic data, processing companies like Google and Amazon are becoming decisive, and 'despite their populist rhetoric, [they are] the new apostles of culture' (Striphas, 2015, p. 407) (see also Chalmers and Edwards, 2017). For instance, with the acquisition of the Goodreads social book reviewing platform, Amazon not only synchronized individuals' access to crowds' reading recommendations, but also significantly increased its influence on their reading choices.
Given that algorithms are built into organizational structures, the question is how they shape or, in Thaler and Sunstein's term, 'nudge information to influence what we know and becomes part of [the] choices we make in our everyday lives without significant refrainment or forbiddance of our options' (Thaler and Sunstein, 2008, p. 6). Research suggests that algorithmically driven information processing reinforces stereotypes and marginalization (e.g., Bozdag, 2013; Gandy, 2009; Noble, 2018). Seaver's (2018) example of a programmer's compilation of a music recommender system illustrates that programmer's recommendations are shaped by arbitrariness of personal preferences and the torque of structural bias. The online environment is a perfect test site for experimenting with new things, monitoring what happens and playing with variations: for instance, Google has publicly noted that it runs continual experiments on its users to try to identify causality and consequence of what might drive changes in user behaviour as well as changes in the way in which information is found and displayed (Willson, 2017).
Seaver posits that the essence of algorithmic system is a 'steady accumulation of feedback loops, little circuits of interpretation and decision [-making that] knit together into a vast textile', wherein 'every stitch is held together by a moment of human response' and 'potential rejection shaped by something outside the code' (Seaver, 2018, p. 377). For instance, in their analysis of gender representation in Google's image search results and its effects on perceived search result quality, images selected, and perceptions of reality. Kay, Matuszek, and Munson (2015) found that search results for occupations slightly exaggerated gender stereotypes and portrayed the minority gender for an occupation less professionally. The authors argued that this stereotype exaggeration may be consistent with perceptions of result quality – people believe results are better when they agree with the stereotype – but risks reinforcing or even increasing perceptions of actual gender segregation in careers (p. 3827). Noble argues that lack of social and human context in algorithmically driven decision-making is an issue for everyone engaging with information technologies on an everyday basis; however, it is of 'particular concern for marginalized groups, those who are problematically represented in erroneous, stereotypical, or even pornographic ways in search engines and who have also struggled for nonstereotypical or nonracist and nonsexist depictions for decades' (Noble, 2018, p. 10).
Gillespie (2018) writes that even though Google maintains that an 'unflinching index' (p. 185) to all internet resources regardless of their content is provided, its algorithms for sorting and rendering search results are quite opaque. Pasquale (2016) states that without knowing what Google actually does when it ranks sites, we cannot evaluate when it is acting in good faith to help users, and when it is biasing results to favour its own commercial interests. Another main concern is that Gillespie raises is that, unlike its index, Google's autocomplete feature, which draws from user-generated content and users' queries to suggest the most relevant options, has the 'effect of putting words in your mouth', in that '[t]he suggestion – whether it is on-point or disturbingly obscene – seems to come from Google as a recommendation, and is then fitted onto your half-query, as if you were about to say it yourself' (p. 186).
Analysis of Google generated image categories in relation to everyday language, also raises questions as to how the image categories in an observed range may be considered relevant. For example, one of the basic level terms utilized in the study by Rosch, Mervis, Gray, Johnson and Boyes-Braem ( 1976), fruit returns a broad range of Google generated categories from actual representation of the concept fruit (such as mulberry, strawberry, watermelon) to seasons (such as summer, autumn, spring), holidays (such as Halloween, Christmas), countries (such as Brazil, Costa Rica, Thailand), emotions (such as happy, love, fun) and nutrition facts (such as fibre, vitamin D, iron). In this regard, Gillespie points out that: 'In the face of ambiguous search results that could also be explained away as the result of circumstance, error, or bias, users are left with only folk theories as to why what's there is there, and what might be missing' ( 2018, p. 196).
Drawing attention to the levers of social media platforms, such as YouTube and Facebook, that are used to moderate (i.e., remove, filter, suspend), recommend (e.g., report news of, make personalized suggestions for), and curate (feature and rank) content, Gillespie argues that these moderation techniques and strategies 'tune the unexpected participation of users, produce the "right" feed for each user, the "right" social exchanges, the "right" kind of community' (2018, p. 208, emphasis in the original). However, these right decisions have a dual character: they may be ethical, legal and healthy recommendations, or they may be serving the interests of these platforms, including promotion of engagement, increase in revenues and facilitation of collection of personal data (Gillespie, 2018). While content moderation is 'fundamental to this collective assertion of value' (p. 210), it should entail not merely cleaning up the 'trouble,' but taking up the 'guardianship of the unresolvable tensions of public discourse, hand back with care the agency for addressing those tensions to users, and responsibly support that process with the necessary tools, data, and insights' (Gillespie, 2018, p. 211).
A salient question is whether algorithmic accountability can be achieved. From an empirical perspective, Otterbacher (2018) proposes techniques for examining social biases in retrieval systems that take into account data provenance, validation and testing procedures, and the role of users' own biases in perpetuating social stereotypes in image search engine results. However, experimental study of analysis of users' awareness of gender bias in image search results by Otterbacher, Checco, Demartini and Clough (2018) revealed few differences in how the images were perceived: users identified as more and less sexist described the images in a very similar manner. Selbst and colleagues (2018) state that technical interventions can be ineffective, inaccurate, and even dangerously misguided in the societal context that surrounds decision-making systems.
Dourish contends that an understanding of how algorithms operate should be based on associations with other 'computation forms, such as data structures' ( Dourish, 2016, p. 2) as they have emerged from practices with and relations to these forms. In this vein, Ananny and Crawford's ( 2018) critical interrogation of the ideal of transparency suggests the inadequacy of transparency for understanding and governing algorithmic systems. The authors argue that:
If the truth is not a positivist discovery but a relational achievement among networked human and non-human agents, then the target of transparency must shift. That is, if a system must be seen to be understood and held accountable, the kind of "seeing" that an actor-network theory of truth requires does not entail looking inside anything, but across a system. Not only is transparency a limited way of knowing systems, but it cannot be used to explain, much less govern, a distributed set of human and non-human actors whose significance lies not internally but relationally. (Ananny and Crawford, 2018, pp. 983-984)
Applying Dourish's and Ananny and Crawford's conceptualisations of accountable and transparent algorithms, we argue that governance and accountability of algorithmic systems should be based on open and transparent examination of dynamic relationships among both human and non-human agents. In Foucault's sense, such algorithmic accountability and transparency calls for examination of power relations, in particular, 'the forms of resistance against different forms of power as a starting point' in order to 'bring to light power relations, locate their position, and find out their point of application and the methods used' (Foucault, 1982, p. 780). This approach allows for analysis of power not only 'from the point of view of its internal rationality' but, most importantly, from the perspective of 'power relations through the antagonism of strategies' (p. 780).
In the following section, we will examine algorithms in knowledge representation, organization and discovery systems.
Algorithms in information representation, organization and discovery
In today's world, wherein knowing has become so closely associated with Internet access and, in particular, ability to find information using search engines (Hjørland, 2012; Sundin, Haider, Andersson, Carlsson and Kjellberg, 2017), information institutions seem to be in a race to embrace advancements of technologies to provide Google-like services to satisfy the individual's everyday information needs. Huvila (2016, p. 570) proposes three premises for understanding how knowing is framed in the contemporary search engine society: easiness, i.e., assumption of the primacy of convenience and emancipation; solvability, i.e., framing of information as a commodity that is embedded and available within technological infrastructures; and, appropriation of technologies and infrastructures for information needs, i.e., significance of diverse use of information technologies rather than mere reliance on their asserted purposes. However, he cautions that easiness of accessing information is coupled with concealment of the inherent complexity of not only of how things work, but most importantly 'how exactly we happen to know the things we know':
The presence of a similar opaque layer that separates people and technologies is more visible than ever in the context of the use of search engines. The tools we use make extraordinary efforts to provide us with quick answers instead of making us to attempt to figure out answers by ourselves or helping us to understand the premises of these often seemingly simple solutions. (Huvila, 2016, p. 571)
One of the most common manifestations of algorithms in knowledge representation, organization and discovery systems is the library catalogue's suggestions of relevant and/or similar titles. Another example are one-stop discovery systems, which are also inherently opaque due to the algorithms behind these platforms that pre-empt our understanding of how and why the retrieved information is discovered. It is also unclear whether and/or how these algorithms further complicate the inherent limitations and biases of knowledge representation and organization professionals and systems, such as tendencies to favour mainstream views (e.g., Metoyer and Doyle, 2015; Olson, 2002).
Big data trends that use user-generated content, such as Goodreads book reviews, which are linked to the traditional bibliographic description of resources in such mainstream systems for representation and organization of resources as WorldCat, also raise questions associated with determining the relevance of suggested user-generated reviews as well as about data quality and ethical concerns related to satisfying one's information needs with user-generated content. Moreover, researchers have found cultural and gender biases in crowdsourced data that have often been used in linked data projects. Callahan and Herring's (2011) analysis of Polish and English editions of Wikipedia, for instance, revealed the systematic differences in coverage of English and Polish cultures, histories and values, with English language coverage having a significant advantage. Luyt's (2015) study of the Wikipedia talk pages on the Vietnam War, revealed that the level of analysis of the talk pages as well as individual contributions are rather shallow.
Collecting and archiving freely available user-generated data, such as the Library of Congress project of archiving the publicly available Twitter tweets, also raise a plethora of concerns ranging from the status of these archival projects, such as whether they serve the purpose of merely automatic backup, preserving historical records or something else, to potential uses of the collected data without users' consent, such as the government surveillance of tweets associated with Michael Brown's assassination in Ferguson (Canella, 2018). Moreover, the practical challenges of archiving the Twitter data, an archive still yet to be opened for public use, and making them accessible, useful and, most importantly, ethical, have undoubtedly challenged the Library of Congress. Zimmer (2015) points out the policy challenges associated with archiving user-generated tweets, such as the creation of appropriate access policies, the question of whether any information should be censored or restricted, and the broader ethical considerations of the very existence of such an archive, especially with regard to issues of privacy and user control.
As the concept of relevance is considered a basis for assessment of the quality of information organization and discovery, in this paper the theory of relevance is applied to determine whether it sheds light on our understanding of system or algorithmic relevance.
Relevance of knowledge representation, organization and discovery
According to relevance theory (a cognitive pragmatics theory of human communication (Sperber and Wilson, 1995)), in the process of interacting with various sources of information, individuals maximize their ability to identify the relevance of the stimuli that they process. Yus explains that in relevance processing one of the most essential mechanisms is the 'human ability to combine contextual... information with new incoming information to yield relevant conclusions, as in... 1) new information..., 2) information already available (from encyclopedic knowledge), and relevant conclusion inferred by combining the two mentioned criteria' (Yus, 2010, p. 681).
In information science, relevance is fundamental in evaluating the effectiveness of information retrieval systems (Maglaughlin and Sonnenwald, 2002; Mizzaro, 1997; Saracevic, 2007a; 2007b). Saracevic states that in the domain of information science relevance is considered as a 'relation between information... and contexts, which include cognitive and affective states and situations (information need, intent, topic, problem, task...)... based on some property reflecting a desired manifestation of relevance (topicality, utility, cognitive match...)' (Saracevic, 2007a, p. 1918).
Huang and Soergel (2013) identify two paradigms in information relevance studies. Whereas the first paradigm aimed to define various aspects of relevance, such as its situational nature (Wilson, 1973) and pertinence (Foskett, 1972), the second paradigm has embarked on a shift to studies of information from real users' perspectives, i.e., investigation of its individual, dynamic and situational nature (Huang and Soergel, 2013). Schamber, Eisenberg and Nilan (1990), for instance, critically evaluated the traditional source-to-destination model of information retrieval, stating that it is 'too linear, mechanistic, and static to serve as a valid conceptual framework for exploring the human relevant judgment process' (p. 770). Schamber and colleagues (1990), applying Dervin's (1983) notion that sense-making involves the centrality of the user in the assessment of meaning-ness of the information in a dynamic information continuum, point out that the 'locus of relevance is within individuals' perceptions of information and information environment – not in information as represented in a document or some other concrete form' (p. 771, emphasis in original). In this vein, Cosijn and Ingwersen (2000) further develop the situational perception of relevance as socio‐cognitive relevance, i.e., a relation between information and situation, task at hand as perceived in a sociocultural context.
In his seminal work, Saracevic (1975, p.338) proposed the following criteria for evaluation of relevance: the subject knowledge view of relevance (i.e., the relation between the user's knowledge of the subject and a topic about the subject); the subject literature view of relevance (i.e., the relation between the subject and the literature); the logical view of relevance (i.e., the relation between premises and conclusions based on logical consequences); the system view of relevance (i.e., the contents of a resource or the processes of a particular information system and their relation to a subject or topic); the destination view of relevance (i.e., human judgment of the relation between a resource and a topic); the pertinence or destination of knowledge view of relevance (i.e., the relation between the stock knowledge of the user and subject knowledge); and the pragmatic view of relevance (i.e., the relation between the immediate problem of a user and the information provided, which involves utility and preference as the basis for inference). For Saracevic, the 'subject knowledge view of relevance is fundamental to all other views of relevance, because subject knowledge is fundamental to communication of knowledge' (1975, p. 333, emphasis in original). Saracevic has also acknowledged that there are multiple information systems and user related factors that may directly affect information relevance, and 'any specific consideration of relevance is tied in with systems of relevance' (Saracevic, 1997, p. 339).
Saracevic (2007b, p. 2) further developed his conceptualization of relevance, proposing a stratified framework of relevance that comprised the following five levels:
- System or algorithmic relevance: the relation between a posed query and an information resource in a collection as either retrieved or failed to be retrieved. Comparative effectiveness in inferring relevance is the criterion for system relevance;
- Topical or subject relevance: the relation between the topic as stated in a query and the topic as covered in the retrieved resources. Aboutness is the criterion for topical relevance;
- Cognitive relevance or pertinence: the relation between the user's knowledge and cognitive need and the retrieved resources. Cognitive correspondence, informativeness, novelty, information quality, and the like are criteria for cognitive relevance;
- Situational relevance or utility: the relation between the situation or task at hand and information resources (retrieved or in the system file, or in existence). Usefulness and appropriateness in decision making or problem solving or reduction of uncertainty or the like are criteria of situational relevance;
- Motivational or affective relevance: the relation between the user's motivation or intent and the information resources (retrieved or in the system file, or in existence). Satisfaction, success, accomplishment, and the like are criteria for motivational relevance.
Hjørland (2010) contends that relevance is always human and that 'determin[ing] which items are relevant in relation to a given goal/task requires subject knowledge' (p. 231). Developing Foskett's (1972) and Saracevic's (1975) positions on the subject knowledge view of relevance, Hjørland endorses a pragmatic view of relevance, emphasizing that, although the expert assessment of relevance may be necessary, 'experts may have different interests, goals and values... and they are not seen as neutral or objective assessors' (p. 232). He further states that users, including subject experts, might not be 'automatically competent to judge relevance' (p. 231) as 'the opinions of experts change when they change theories' (p. 232). However, studies of information relevance are predominantly based on experimentation, in particular, investigation of stimulus and responses. Moreover, for the most part, relevance research considers people and/or systems are black boxes (Saracevic, 2007b). In this regard, Saracevic states that: 'The black box approach is especially limited and potentially even misleading in results, particularly when systems involved in studying human behaviour and effects are a complete black box' (p. 2141).
What Neyland and Möllers (2016) describe as the 'careful plaiting of relatively unstable associations of people, things, processes, documents and resources' (p. 45) of algorithmic systems, so that the systems can be seen, understood and used, requires reconsideration of perceptions of system or algorithmic relevance and careful investigation of non-topical variables associated with relevance. Otherwise, the conceptualization of information relevance is deferred to technological determinism, that is, the belief that technology is an underlying force in human society that acts as an independently force in our lives, advances according to its own inner dynamic, and is unrestrained by social arrangement, culture and thought (Volti, 1992). In this respect, McLuhan (1994) states that 'By continuously embracing technologies, we relate ourselves to them as servomechanisms. That is why we must, to use them at all, serve these objects, these extensions of ourselves, as gods' (p. 46). However, this perception of technology limits thorough understanding of the human and ethical side of social appropriation of technology that informs and shapes as well as limits the advancement of technological development. In this vein, Huang and Soergel (2013) state that 'topicality is not limited to system determined relevance, nor is the system limited to determining topical relevance' (p. 25), and retrieval systems may incorporate non-topical 'variables pertaining to the user, task, and situation, as well as to integrate reasoning based on nonmatching types of topical connections' (p. 25).
Thus, while system determination of relevance may draw on a range of actions of human and nonhuman agents, nevertheless, regardless, these actions reflect human inputs on how things can and/or cannot be classified as relevant in a given context. Consequently, the classification that underlies the system's relevance may in Bowker and Star's (2000) terms 'appear natural, eloquent, and homogenous within a given human context [but] appear forced and heterogeneous outside that context' (p. 131). For instance, in their seminal work, Bowker and Star's analysis of the International Classification of Diseases revealed that, along with the scientific and clinical criteria of classification of diseases, various health, political and cultural factors are taken into account to formalize these diagnostic criteria. For instance, in the 11th edition of the Classification experts made a decision to add gaming disorder to the diagnostic categories to help address associated unhealthy behaviour, such as compulsion, impulse control problems, or behavioural addiction (Wichstrøm, Stenseng, Belsky, Soest, and Hygen, 2019). Thus, the question is, What factors and/or context as well as associated ethical standards, norms and policies define the system's relevance?
The argument in this paper is that agents' situated perception of relevance should be considered in relation to the system's criteria of relevance to ensure accountable, fair, equitable, transparent and, most importantly, ethical assessment of relevance of discovered information.
Ethics of knowledge representation, organization and discovery
The ethical power of algorithms is the ability to create a relation among humans and non-human actors that resembles and reconstructs probabilities, and to make the set of potential outcomes the model anticipates likely and sensible (Mackenzie, 2015). Ananny (2016) points out that even though algorithms are unpredictable objects of study, 'their ethics might still be investigated systematically by redescribing an ethical framework in terms of traceable, operationalized concepts and then looking for evidence of such concepts among the elements of algorithmic assemblages' (p. 109). In this vein, Floridi (2008) argues that the ethical norms and standards should be applied equally to both human and non-human agents regardless of location in cyber- or biosphere, i.e., regions of the planet that supports life:
Being able to treat nonhuman agents as moral agents facilitates the discussion of the morality of agents not only in cyberspace but also in the biosphere—where animals can be considered moral agents without their having to display free will, emotions, or mental states—and in contexts of distributed morality, where social and legal agents can now qualify as moral agents. (p. 15)
Floridi (2013) envisages information ethics as more impartial and universal, less ethically biased, and inclusive of every instance of information whether it is implemented physically or not. For Floridi, being human and the infosphere are co-referential. Floridi (2006) has also argued that information ethics, as ethics of creative stewardship, are addressed equally to users and producers of information. From this perspective, information representation and organization professionals are like demiurges who should assume an ecologically-oriented perspective and support a morally-informed construction of the environment. Floridi thus argues that in order to shift from individual virtues to global values, people need to take an ecopoietic approach and recognize their responsibilities to the environment, including its present and future citizens, acting as enlightened creators, stewards or supervisors, not just as its virtuous users and consumers.
Floridi's (1999) conceptualization of information ethics is highly suitable to an information culture and society, as it enhances our perception of moral imperatives and sharpens 'our sense of value... to make the rightness or wrongness of human actions more intelligible and explicable,' and by doing so 'helps us to give an account of what we already intuit' (p. 56). Most importantly, the ecologically-oriented perspective aligns well with fair representation, organization and discovery systems as it shifts concerns from the expectation of neutrality of systems to the necessity to humanize the representation, organization and discovery of knowledge to build open, inclusive and equitable systems.
This emphasis on the human side of representation, organization and discovery is mutually reinforcing with the ethical obligations of information professionals to provide accountable, fair, equal, and transparent access to the information.
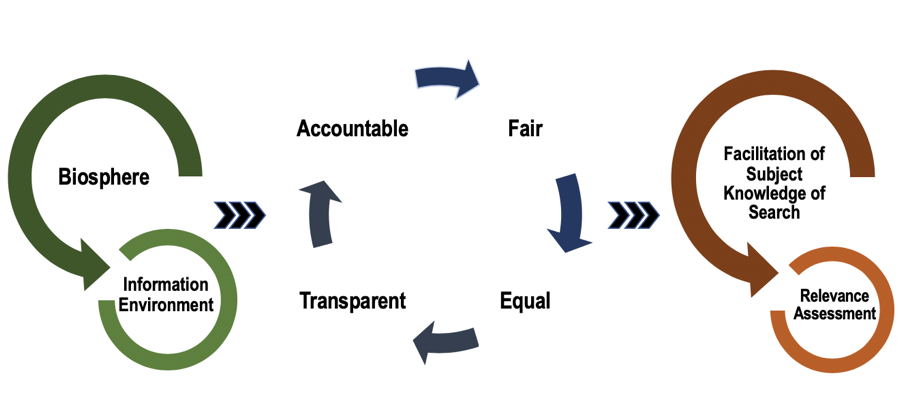
Developing the ideas of fairness (e.g., the system should avoid discrimination across people), accountability (e.g., the system should be reliable and be able to justify actions it takes), confidentiality (e.g., the system should not reveal secrets) and transparency (e.g., the system should be able to explain returned results) in approaches to retrieval (Culpepper et al., 2018), this paper conceptualises these interwoven criteria as follows (see Figure 1):
Accountable provision of access to information implies representation and organization of the information in compliance with standards and regulations that apply to both human and non-human agents (such as artificial intelligence tools, systems, platforms, connectivity), so decisions to provide and/or not provide certain information to a particular group of users could be justified with reference to appropriate standard(s), regulation(s) and/or policies. An accountable approach should reflect (or ideally do better than) the established relationship between legal rules and procedures and human behaviour.
Fair provision of information sources and services involve not only permission for use of copyrighted information, but, most importantly, responsible use of all information, such as freely available online user-generated content, including that which is copyrighted under Creative Commons content. Fair use recognizes the value of free information flow around the internet as well as the importance of certain restrictions on how the freely available information can be used. Such restrictions may entail, for example, differentiating use of non-human generated information, such as use of social media information generated by bots that automate interaction with other users and could be quite influential in issues associated with policy and politics, or use of Creative Commons licensed information for development of new technology, such as user-generated images as a dataset for improvement of facial recognition technology (Merkley, 2019). Equal representation, organization and discovery in a system assume availability of a balanced representation and organization of information regardless of one's culture, race, sexuality and/or beliefs. This approach assumes adherence to the established ethical norms, regulations and/or policies in relation to human behaviour. Transparent knowledge representation and organization systems provide and maintain and understandable (to all participants) views of standards and policies applied to the given information as well as clarity concerning other dynamic relationships of the given information in the system. Transparency also implies provision of provenance of the presented information. Because this approach may potentially infringe upon one's privacy, underlying requirements of involved agents' consent, privacy and anonymity should be prioritised.Application of the ethical norms and standards of the biosphere to information environment and utilization of established principles of accountability, fairness, equity and transparency to knowledge representation, organization and discovery systems through awareness of ethical concerns of involved human and non-human agents may lead to the establishment of ethical and democratic systems of representation, organization and discovery that facilitate use of an individual's subject knowledge in the assessment of relevance (Figure 1).
Conclusion
Representing a position aligned with Floridi's ecologically-oriented perspective on information, in this paper we have endorsed a significant reconsideration of algorithmic relevance, particularly in relation to all contextually situated factors that are algorithmically assessed to discover the information. This reconsideration of information retrieval should reveal to all users the effects of algorithms on information representation, organization and discovery.
This paper also calls for reconsideration of the current perception that knowledge representation, organization and discovery systems know best what resources are relevant to satisfy peoples' everyday information needs. Even though there are a number of factors that affect individuals' preferences for particular vocabularies with which to communicate and search for information, such as audience, background knowledge, and culture, there should be a more comprehensive consideration of systems' criteria of relevance in information representation, organization and discovery, especially of how algorithms nudge, because they are, as Yeung (2017) states, 'extremely powerful and potent due their networked, continuously updated and pervasive nature' (p. 118).
This paper also argues that Floridi's conceptualisation of information ethics from an ecologically-oriented perspective better aligns with the ideal of accountability, fairness, equality and transparency in representation, organization and discovery systems. Most importantly, placing emphasis on the human side of representation, organization and discovery reinforces the ethical norms associated with fair access to knowledge through all processes involved. This approach would facilitate practices that acknowledge what Taylor (1962) asserted more than a half century ago and is even more salient in the current digital age, that the 'inquirer is an integral part of the information system and not a stranger knocking at the door for directions' (p. 396).
Acknowledgements
Heartfelt thanks go to Dr. Sharon Pugh for editing the multiple iterations of this work, the editors and reviewers for the constructive suggestions that helped to improve this paper.
About the author
Lala Hajibayova is Assistant Professor, School of Information, Kent State University, PO Box 5190, Kent, OH 44242-0001, USA. She received her PhD in information science from Indiana University. She investigates how individuals' contextualized experiences of engaging and representing artefacts facilitate cultural and scientific productions as well as design of human-centred systems that embrace a multiplicity of views and comply with ethical norms. She can be contacted at lhajibay@kent.edu
References
- Ananny, M. (2016). Toward an ethics of algorithms: convening, observation, probability, and timeliness. Science, Technology, & Human Values, 41(1), 93–117.
- Ananny, M. & Crawford, K. (2018). Seeing without knowing: limitations of the transparency ideal and its application to algorithmic accountability. New Media & Society, 20(3), 973–989.
- Beer, D. (2017). The social power of algorithms. Information, Communication & Society, 20(1), 1-13.
- Beer, D. (2009). Power through the algorithm? Participatory web cultures and the technological unconscious. New Media & Society,11(6), 985–1002.
- Bowker, G.C. & Star, S.L. (2000). Sorting things out: classification and its consequences. Cambridge, MA: MIT Press.
- Bozdag, E. (2013). Bias in algorithmic filtering and personalization. Ethics and Information Technology, 15(3), 209-227.
- Bucher T. (2012). Want to be on top? Algorithmic power and the threat of invisibility on Facebook. New Media & Society, 14(7), 1164–80.
- Callahan, E. & Herring, S. (2011). Cultural bias in Wikipedia content on famous persons. Journal of the American Society for Information Science and Technology, 62(10), 1899-1915.
- Canella, G. (2018). Racialized surveillance: activist media and the policing of Black bodies. Communication, Culture and Critique, 11(3), 378–398.
- Chalmers, M. K. & Edwards, P. N. (2017). Producing "one vast index" Google Book Search as an algorithmic system. Big Data & Society, 4(2), 1-16. Retrieved from https://doi.org/10.1177/2053951717716950.
- Cosijn, E. & Ingwersen, P. (2000). Dimensions of relevance. Information Processing & Management, 36(4), 533–550.
- Culpepper, J.S., Diaz, F., Smucker, M.D., Allan, J., Arguello, J., Azzopardi, L.,... Zuccon, G. (2018). Research frontiers in information retrieval: report from the Third Strategic Workshop on Information Retrieval in Lorne (SWIRL 2018). ACM SIGIR Forum, 52(1), 34-90. Retrieved from https://sigir.org/wp-content/uploads/2018/07/p034.pdf (Archived by the Internet Archive at https://bit.ly/2JTtEoA)
- Dervin, B. (1983). An overview of sense-making research: concepts, methods and results to date. Paper presented at the International Communication Association (ICA) Annual Meeting, Dallas, USA. Retrieved from https://bit.ly/2rqqIJt (Archived by the Internet Archive at https://web.archive.org/web/20180911210207/http://faculty.washington.edu/wpratt/MEBI598/Methods/An%20Overview%20of%20Sense-Making%20Research%201983a.htm )
- Dourish, P. (2016). Algorithms and their others: algorithmic culture in context. Big Data & Society, 3(2), 1-11, Retrieved from https://doi.org/10.1177/2053951716665128 (Archived by the Internet Archive at https://web.archive.org/web/20190330232809/https://journals.sagepub.com/doi/10.1177/2053951716665128).
- Floridi, L. (2013). The ethics of information. Oxford: Oxford University Press.
- Floridi, L. (2008). Foundations of information ethics. In K.E. Himma and H.T. Tavani (Eds.) The handbook of information and computer ethics (pp. 3-24). Hoboken, NJ: John Wiley & Sons
- Floridi, L. (2006). Information ethics, its nature and scope. Computers and Society, 35(2), 21-36. Retrieved from http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.499.6848&rep=rep1&type=pdf
- Floridi, L. (2002). Information ethics: an environmental approach to the digital divide. Philosophy in the Contemporary World, 9(1), 39-45.
- Floridi, L. (1999). Information ethics: on the philosophical foundation of computer ethics. Ethics and Information Technology, 1(1), 37-56.
- Foskett, D.J. (1972). A note on the concept of 'relevance'. Information Storage and Retrieval, 8(2), 77–78.
- Foucault, M. (1982). The subject and power. Critical Inquiry, 8(4), 777-795.
- Galloway, A. (2006). Gaming: essays on algorithmic culture. Minneapolis, MN: University of Minnesota Press.
- Gandy O. (2009). Coming to terms with chance: engaging rational discrimination and cumulative disadvantage. Farnham, UK: Ashgate.
- Gillespie, T. (2018). Custodians of the Internet: platforms, content moderation, and the hidden decisions that shape social media. New Haven, CT: Yale University Press.
- Gillespie, T. (2014). The relevance of algorithms, In T. Gillespie, P.J. Boczkowski & K.A. Foot (Eds.), Media technologies: essays on communication, materiality, and society (pp. 167-193). Cambridge, MA: MIT Press.
- Gillespie, T. (2007). Wired shut: copyright and the shape of digital culture. Cambridge, MA: MIT Press.
- Hajibayova, L. & Jacob, E.K. (2016). An investigation of the levels of abstraction of tags across three resource genres. Information Processing & Management, 52(6), 1178-1187.
- Hajibayova, L. & Jacob, E.K. (2015). Factors influencing user-generated vocabularies: How basic are basic level terms? Knowledge Organization, 42(2), 102-112.
- Hallinan, B. & Striphas, T. (2016). Recommended for you: the Netflix Prize and the production of algorithmic culture. New Media & Society, 18(1), 117-137.
- Hjørland, B. (2012). Is classification necessary after Google? Journal of Documentation, 68(3), 299-317.
- Hjørland, B. (2010). The foundation of the concept of relevance. Journal of the American Society for Information Science and Technology, 61(2), 217-237.
- Hoenkamp, E. & Bruza, P. (2015). How everyday language can and will boost effective information retrieval. Journal of the Association for Information Science and Technology, 66(8), 1546-1558.
- Holmes, O. (2016, June 16). Manners maketh Nan: Google praises 86-year-old for polite internet searches. The Guardian. Retrieved from https://www.theguardian.com/uk-news/2016/jun/16/grandmother-nan-google-praises-search-thank-you-manners-polite (Archived by the Internet Archive at https://bit.ly/2ryB3TR).
- Huang, X. & Soergel, D. (2013). Relevance: the improved framework for explicating the notion. Journal of the American Society for Information Science and Technology, 64(1), 18-35.
- Huvila, I. (2016). Affective capitalism of knowing and the society of search engine. Aslib Journal of Information Management, 68(5), 566-588.
- Kay, M., Matuszek, C. & Munson, S.A. (2015). Unequal representation and gender stereotypes in image search results for occupations. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems (CHI’15) (pp. 3819-3828), Seoul, Korea, April 18-23, 2015. New York, NY: ACM.
- Luyt, B. (2015). Debating reliable sources: writing the history of the Vietnam War on Wikipedia. Journal of Documentation, 71(3),440-455.
- Mackenzie A. (2015). The production of prediction: what does machine learning want? European Journal of Cultural Studies, 18(4-5), 429–445.
- Maglaughlin, K. L. & Sonnenwald, D. H. (2002). User perspectives on relevance criteria: a comparison among relevant, partially relevant, and not‐relevant judgments. Journal of the Association for Information Science and Technology, 53(5), 327-342.
- McLuhan, M. (1994). Understanding media: the extension of man. Cambridge, MA: MIT Press.
- Merkley, R. (2019, March 13). Use and fair use: statement on shared images in facial recognition AI. [Web log post]. Creative Commons Retrieved from https://creativecommons.org/2019/03/13/statement-on-shared-images-in-facial-recognition-ai/ (Archived by the Internet Archive at https://web.archive.org/web/20190313200100/https://creativecommons.org/2019/03/13/statement-on-shared-images-in-facial-recognition-ai/)
- Metoyer, C. A. & Doyle, A.M. (2015). Introduction. Cataloging & Classification Quarterly,53(5-6), 475-478.
- Mizzaro, S. (1997). Relevance: the whole history? Journal of the Association for Information Science and Technology, 48(9), 810-832.
- Murphy, G. (2004). The big book of concepts. Cambridge, MA: MIT Press.
- Neyland D. & Möllers, N. (2016). Algorithmic IF … THEN rules and the conditions and consequences of power. Information, Communication & Society, 20(1), 45–62.
- Noble, A. U. (2018). Algorithms of oppression: how search engines reinforce racism. New York, NY: New York University Press.
- Olson, H. A. (2002). The power to name: locating the limits of subject representation in libraries. Dordrecht, The Netherlands: Kluwer Academic Publishers.
- Otterbacher J. (2018). Addressing social bias in information retrieval. In P. Bellot, et al. (Eds.), Experimental IR meets multilinguality, multimodality, and interaction. CLEF 2018, (pp. 121-127). Cham, Switzerland: Springer. (Lecture Notes in Computer Science, Vol. 11018).
- Otterbacher, J., Checco, A., Demartini, G. & Clough, P. (2018). Investigating user perception of gender bias in image search: the role of sexism. In Proceedings of the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR-2018). New York, NY: ACM Press.
- Pasquale, F. (2016). The black box society: the secret algorithms that control money and information. Cambridge, MA: Harvard University Press.
- Rosch, E., Mervis, C, Gray, W., Johnson, D. & Boyes-Braem, P. (1976). Basic objects in natural categories. Cognitive Psychology, 8(3), 382-439.
- Saracevic, T. (2007a). Relevance: a review of the literature and a framework for thinking on the notion in information science. Part II: Nature and manifestations of relevance. Journal of the American Society for Information Science and Technology, 58(13), 1915-1933.
- Saracevic, T. (2007b). Relevance: a review of the literature and a framework for thinking on the notion in information science. Part III: Behavior and effects of relevance. Journal of the American Society for Information Science and Technology, 58(13), 2126-2144.
- Saracevic, T. (1997). The stratified model of information retrieval interaction: extension and applications. Proceedings of the American Society for Information Science, 34, 313-327.
- Saracevic, T. (1975). Relevance: a review of and a framework for the thinking on the notion in information science. Journal of the American Society for Information Science, 26(6), 321-343.
- Schamber, L., Eisenberg, M.B. & Nilan, M.S. (1990). A re-examination of relevance: toward a dynamic, situational definition. Information Processing & Management, 26(6), 755-776.
- Seaver, N. (2018). What should an anthropology of algorithms do? Cultural Anthropology, 33(3), 375–385.
- Selbst, A.D., Boyd, D., Friedler, S., Venkatasubramanian, S. & Vertesi, J. (2018). Fairness and abstraction in sociotechnical systems. In FAT* 19 Proceedings of the Conference on Fairness, Accountability, and Transparency (pp. 59-68). New York, NY: ACM.
- Sperber, D. & Wilson, D. (1995). Relevance: communication and cognition. Oxford: Blackwell.
- Striphas, T. (2015). Algorithmic culture. European Journal of Cultural Studies, 18(4-5), 395-412.
- Suchman, L. (2007). Human-machine reconfigurations: plans and situated actions. New York, NY: Cambridge University Press.
- Sundin, O., Haider, J., Andersson, C., Carlsson, H. & Kjellberg, S. (2017). The search-ification of everyday life and the mundane-ification of search. Journal of Documentation, 73(2), 224-243.
- Taylor, R. S. (1962). The process of asking questions. Journal of the Association for Information Science and Technology, 13(4), 391-396.
- Thaler, R. H. & Sunstein, C.R. (2008). Nudge: improving decisions about health, wealth, and happiness. New Haven, CT: Yale University Press.
- Turkle, S. (2005). The second self: computers and the human spirit. Cambridge, MA: MIT Press.
- Volti, R. (1992). Society and technological change. New York, NY: St. Martin’s Press.
- Weitzner, D.J., Abelson, H., Berners-Lee, T., Feigenbaum, J., Hendler, J. & Sussman, G.J. (2007). Information accountability.Cambridge, MA: Massachusetts Institute of Technology. (Computer Science and Artificial Intelligence Laboratory Technical Report MIT-CSAIL-TR-2007-034.) Retrieved from https://bit.ly/34vMhGO
- Wichstrøm, L., Stenseng, F., Belsky, J., von Soest, T. & Hygen, B. W. (2019). Symptoms of internet gaming disorder in youth: predictors and comorbidity. Journal of Abnormal Child Psychology, 47(1), 71-83.
- Willson, M. (2017). Algorithms (and the) everyday. Information, Communication & Society, 20(1), 137-150.
- Wilson, P. (1973). Situational relevance. Information Storage and Retrieval, 9(8), 457–471.
- Yeung, K. (2017). ‘Hypernudge’: big data as a mode of regulation by design. Information, Communication & Society, 20(1), 118-136.
- Yus, F. (2010). Relevance theory. In B. Heine & H. Narrog (Eds.), The Oxford handbook of linguistic analysis (pp. 679-702). Oxford: Oxford University Press.
- Zimmer, M. (2015). The Twitter archive at the Library of Congress: challenges for information practice and information policy. First Monday, 20(7). Retrieved from https://journals.uic.edu/ojs/index.php/fm/article/view/5619 (Archived by the Internet Archive at https://web.archive.org/web/20180602234906/http://journals.uic.edu/ojs/index.php/fm/article/view/5619).