Introduction. We present an in-depth case study that follows collaborative data sharing, curation and reuse practices among eleven zooarchaeologists and two curators during a large data reuse project. A data life-cycle model highlights how factors in one life-cycle phase impacted other phases forming virtuous (positive) and vicious (negative) circles. Method. Mixed methods were employed, including individual and focus group interviews, observations, documentary analysis of e-mail threads, and review of curatorial guidelines. Analysis. Interview and e-mail data had two rounds of qualitative coding. General topical codes were established first. Next, relationships among the four life-cycle phases (data production, sharing, curation, and reuse) and factors having positive or negative effects were coded. Results. Data production practices were the most influential on other phases, data sharing practices followed. Curatorial intervention, at times laborious, did reverse factors that negatively influenced curation and reuse. Data reuse had a positive influence on all other phases. Conclusion. Data producers partnering with data curators to steer the data production process, after data management planning and before data deposit, is critical to avoid the proliferation of vicious circles and enable meaningful data reuse. Understanding the impact of data practices, can lead to self-reflection on the part of data producers, sharers, curators, and reusers.
Introduction
In June 2014, 'Data sharing reveals complexity in the westward spread of domestic animals across Neolithic Turkey', was published in PLoS One (Arbuckle et al. 2014). In this article, twenty-three authors, all zooarchaeologists, representing seventeen different archaeological sites in Turkey investigated the domestication of animals across Neolithic southwest Asia, a pivotal era of change in the region's economy. The PLoS One article originated in a unique data sharing, curation, and reuse project in which a majority of the authors agreed to share their data and perform analyses across the aggregated datasets. The extent of data sharing and the breadth of data reuse and collaboration were previously unprecedented in archaeology. In the present article, we conduct a case study of the collaboration leading to the development of the PLoS One article. In particular, we focus on the data sharing, data curation, and data reuse practices exercised during the project in order to investigate how different phases in the data life-cycle affected each other.
Studies of data practices have generally engaged issues from the singular perspective of data producers, sharers, curators, or reusers. Furthermore, past studies have tended to focus on one aspect of the life-cycle (production, sharing, curation, reuse, etc.). A notable exception is Carlson and Anderson's (2007) comparative case study of four research projects which discusses the life-cycle of data from production through sharing with an eye towards reuse. However, that study primarily addresses the process of data sharing. While we see from their research that data producers' and curators' decisions and actions regarding data are tightly coupled and have future consequences, those consequences are not fully explicated since the authors do not discuss reuse in depth.
Taking a perspective that captures the trajectory of data, our case study discusses actions and their consequences throughout the data life-cycle. Our research theme explores how different stakeholders and their work practices positively and/or negatively affected other phases of the life-cycle. More specifically, we focus on data production practices and data selection decisions made during data sharing as these have frequent and diverse consequences for other life-cycle phases in our case study. We address the following research questions:
How do different aspects of data production positively and negatively impact other phases in the life-cycle?
How do data selection decisions during sharing positively and negatively impact other phases in the life-cycle?
How can the work of data curators intervene to reinforce positive actions or mitigate negative actions?
Literature review
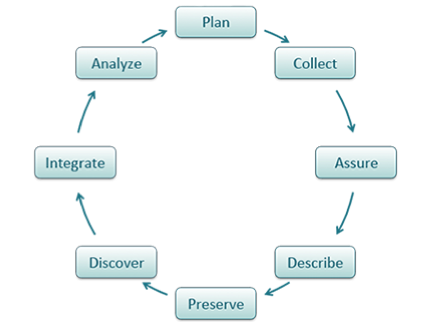
life-cycle models arose out of the records management movement in the mid-twentieth century to accommodate the explosion of paper records, particularly in the federal government. The traditional life-cycle incorporated creation or receipt of a document, distribution, use (e.g., primary use), maintenance, and disposition (e.g., destruction or archiving) (Stephens, 2007). The US National Archives and Records Administration (NARA) presents a three-stage model (Figure 1a), which includes: (1) creation (or receipt), (2) maintenance and use, and (3) disposition. If reuse is considered at all, it is implicit in the disposition or archiving stage. This model has since been applied to all media of records (analog and digital), including research data. For example, the DataONE project investigators present an eight stage life-cycle (Figure 1b): plan, collect, assure, describe, preserve, discover, integrate, and analyse, which is 'a high level overview of the phases involved in successful management, and preservation of data for use and reuse'.
Figure 1a: Life-cycle model from NARA (US. National..., 2017) Figure 1b: Life-cycle model from DataONE (n.d.)
The NARA model examines information or data from a custodial standpoint, whereas the DataONE model represents the researcher's perspective. According to Carlson (2014), life-cycle models are developed based on an individual, organization, or community and seemingly represent only one perspective at a time. The accompanying literature on data practices tends to follow suit. Although examining data producers', data curators', and data reusers' practices separately has provided insight into what happens during the various life-cycle phases, particularly the challenges and needs, data are touched by all of these individuals while traveling through the life-cycle. Without integrated study, it has been difficult to discern how an individual's actions in one phase of the life-cycle influence other individuals' actions in other phases. In the following paragraphs, studies from each of the life-cycle phases are presented to highlight the challenges and needs that could benefit from a more holistic study that considers the interdependencies and influences between phases.
One of the key challenges for researchers who produce and share data is overcoming metadata friction, which is the time and effort required to manage and curate data (Edwards, Mayernik, Batcheller, Bowker and Borgman, 2011). Studies show researchers often use idiosyncratic ways to describe data rather than apply global standards and best practices in data documentation (Carlson and Anderson, 2007; Edwards et al., 2011;Faniel, Kansa, Whitcher Kansa, Barrera-Gomez and Yakel, 2013). This occurs not only with researchers who work alone, but also among members of the same laboratory or research team. According to Darch et al. (2015), the variety of methods scientists use to produce, prepare, and document the same types of data for analysis are often rooted in social, technical, and other material resources. Similarly, in a small team setting, Akmon, Zimmerman, Daniels and Hedstrom (2011) found that differences in opinion about what data descriptions should be captured resulted in uneven recordkeeping. Dealing with data from multiple owners within or across teams exacerbates these challenges. Without common guidelines for describing, managing, and retaining data produced from the same research project, Borgman and colleagues found related datasets not being stored or linked together and individuals having different requirements for what constitutes clean and accurate data (Borgman, Wallis and Enyedy 2006; Borgman, Wallis and Mayernik 2012).
Described as '[t]he activity of managing and promoting the use of data from its point of creation, to ensure it is fit for contemporary purpose, and available for discovery and reuse' (Lord, Macdonald, Lyon and Giarretta 2004, p. 1), data curation is expected to address these challenges. Witt (2008) argues that librarians' role as gatekeepers could increase the viability of shared data by connecting with researchers earlier in the research process to contribute important curatorial support. Moreover, archaeologists have called for early interventions during archaeological data collection and documentation (Atici, Kansa, Lev-Tov and Kansa, 2012). However, the tendency in archaeology as well as other disciplines is for engagement to peak during data management planning, drop or lie dormant during data production and analysis, and peak again during data deposit. At higher education institutions, this gap in service is likely due in part to librarians' concerns about scaling services to meet the needs of a campus community and data producers' desire for services that support their current ways of working. Closing the gap between data management planning and data deposit is critical because the gap impacts data reusers' ability to conduct secondary analyses. Curators can close that gap by engaging with data producers during all phases of the data life-cycle.
According to Carlson and Anderson (2007), trusting data that another person has collected requires 'visualizing data in intelligible forms, but more importantly, making explicit their context of production and setting up appropriate systems of quality checks and assessment' (p. 8). A growing body of data reuse studies support these conclusions. They show the importance of basic metadata such as the name of the data producer, data creation time and date, and data format, file size, and file name when establishing trust in the data, developing sampling frames, and determining data accessibility (Berg and Goorman, 1999; Chin and Lansing, 2004; Faniel and Jacobsen, 2010; Van House, 2002; Van House, Butler and Schiff 1998; Yoon, 2016; Zimmerman, 2008). The studies also show that detailed descriptions of data collection procedures (e.g., how instruments are calibrated, how data are coded and decoded, how errors and limitations encountered during data collection are resolved, how data collection decisions are made) help reusers determine whether data are trustworthy, well understood, and relevant (Birnholtz and Bietz, 2003; Chin and Lansing, 2004; Carlson and Anderson, 2007; Faniel and Jacobsen, 2010; Rolland and Lee, 2013). Yet, this context surrounding data production needed to support data reuse has not been incorporated into data production practices. Such knowledge can augment data description and documentation in ways that support data producers, their research teams, and data reusers, not to mention potentially reduce data curators' time and effort.
In sum, studies show the challenges and needs encountered during data production, sharing, curation and reuse, but they are isolated views. Less is known about how the challenges and needs in one part of the data life-cycle impact other parts and what interventions can be done to allow data to flow more smoothly from person to person. To focus on these interdependencies and influences, our case study employs the theoretical framework of virtuous and vicious circles, which Masuch (1985) introduced. Virtuous or vicious circles arise when some factor in one part of a process influences activities in a subsequent part. Virtuous circles arise when the factor influencing the process is beneficial, facilitating its functioning. Vicious circles occur when the factor is detrimental to the process. This framework has been used in different contexts, such as epidemiology, news and voting behaviour, and design studies (Hillier and Penn, 1994).
We draw from organizational studies, in particular, Garud and Kumaraswamy (2005) who further developed the framework when examining organizational knowledge management and sharing. They argue 'that the very initiatives undertaken to harness an organization's knowledge system by generating a virtuous circle of knowledge accumulation, reuse, and renewal can just as easily generate vicious circles' and 'suggest that knowledge managers must employ process interventions to steer an organization's knowledge system around or out of the vicious circles' (Garud and Kumaraswamy, 2005, p. 10). Garud and Kumaraswamy's findings concerning the critical nature of interventions bears notice, particularly since curation, a key part of the data life-cycle, is seen as a form of intervention. Furthermore, there are several other parallels which make testing this framework interesting. First, it focuses on similar life-cycle phases: knowledge creation, sharing, reuse, and dissemination. Second, examining the creation and/or mediation of virtuous and vicious circles concern the social dynamics of information transfer involved in collaborations (albeit in organizations), which we have extended to a disciplinary group. Third, virtuous and vicious circles pertain to how both tacit and explicit (recorded) information is shared. Finally, the process or systems approach fits our case as we trace the interrelationships among all life-cycle phases: data production, sharing, curation, and reuse.
The Anatolia Project
Our case study is based on the Anatolia Project, during which twelve zooarchaeologists, members of the Central and Western Anatolian Neolithic Working Group, agreed to share, publish, and reuse the data from fourteen archaeological sites in Anatolia (now primarily Turkey). The Anatolia Project was significant because such a large aggregation of faunal (animal bone) data from so many sites, over such a long time period, and over a broad geographic range, had previously never been done. As a result, research questions concerning the spread of domestication and the transition from a hunter-gatherer to an agrarian society could be addressed in a more comprehensive way to trace domestication and the evolution of agrarian society.
At the start of the Anatolia Project, Open Context prepared guidelines to facilitate data sharing, Preparing your Dataset for Publication in Open Context. This document listed thirteen categories of required information including: title, creator, site name, location, period, short description, keywords, abstract, methodological notes, potential applications of the data, related publications, table field descriptions, and license choice. In addition, the curators asked participants to standardise, edit, decode, link images or other media to specific records, and deliver the data in Microsoft Excel using a specific template. Excel was selected to mitigate technical complications of character encoding, given that many place names were in Turkish.
The zooarchaeologists began sharing the raw data with Open Context's two curators in the fall of 2012. According to the curators, '[i]n most cases, contributing researchers submitted minimal documentation' (Kansa, Kansa, & Arbuckle, 2014, p. 60). The bulk of the data curation occurred during the fall of 2012 and winter of 2013. Curation included data documentation, standards alignment where possible, additional data cleaning and decoding using OpenRefine, and publication in a standardised format. In total, 294,000 faunal records resulted from archaeological sites spanning the Epipaleolithic through the Chalcolithic periods, a range of more than 10,000 years and 42 chronological phases (Kansa, Kansa, and Arbuckle, 2014). In addition to assigning digital object identifiers to all datasets and publishing the data on their own website, Open Context archived the data at the California Digital Library for long term preservation.
For data analysis, the curators delivered the cleaned data to project participants as comma-separated values (.csv) files. At that point, participants were only given portions of the data pertaining to a particular animal species (pig, goat, sheep, cow, etc.) to analyse domestication changes over time. Data reuse began in winter 2013. Data curators helped manage the sharing process and liaised between sharers and reusers. Data curation and reuse occurred simultaneously, and participants in each stage communicated regularly. In the early stages of reuse, participants asked the curators questions about data coding, completeness, and chronology. The initial data reuse goal was a presentation at the International Open Workshop 'Socio-Environmental Dynamics over the last 12,000 Years: The Creation of Landscapes III,' at Kiel University from April 16-19, 2013.
At the workshop, participants critiqued each other's results, discussed the problems with their portions of the datasets, and received feedback from colleagues. The curators took notes on the workshop's discussion, which contributed to finalizing the datasets for publication in Open Context. After the workshop, the lead author of the PLOS One article worked with the participants, as well as site directors, other zooarchaeologists, and other available data, to refine the analyses for publication.
Methods
The unique nature of the Anatolia Project formed the basis of our case selection. First, two of the three authors of this article were granted unprecedented access to the pertinent events. Second, case study data were collected in real time, which meant relying on participants' long-term memories for many of our questions was not necessary. Third, the case enabled us to examine much of the data life-cycle, from data preparation and sharing through presentation at a professional conference and the resulting online access copy of the article. Lastly, the case study offered opportunities to develop schema for interactions when producing, sharing, curating, and reusing data. While we acknowledge the uniqueness of the case, we also were able to identify opportunities and challenges for data producers, sharers, curators, and reusers to act positively to create virtuous circles and smooth out data handoffs throughout the life-cycle.
Data Collection
Our mixed methods design included individual interviews during data sharing and early in the data reuse process, documentary examination, observation of the participants at the Kiel workshop, and a post-workshop focus group interview. The data were collected from November 2012 through May 2013. Study participants included two data curators, eleven zooarchaeologists, and the workshop commentator.
We conducted semi-structured interviews with eight of eleven zooarchaeologists representing ten archaeological sites. During the interviews, we asked participants about their backgrounds, the archaeological site, and the data they were sharing. We also asked about interactions with other data producers and data curators at different phases of the project.
While these direct methods offered personal perspectives on the practices, documentary evidence provided an understanding of the work as it took place. We collected the guidelines the data curators prepared for data sharers; e-mail exchanges between the curators and the zooarchaeologists during the data sharing and reuse phases of the project; presentation slides from the Kiel workshop; the final project report; articles written by the data curators and the zooarchaeologists; and the final datasets in Open Context. The e-mail threads provided the primary documentary evidence we used as they portrayed an up-to-date representation of the conversations and the questions that arose during data sharing, curation, and reuse. We received e-mail exchanges between the two curators and eleven zooarchaeologists amounting to 333 individual e-mail messages. The e-mails are the only data source where we collected information from all participants in the study.
We observed the day-long Kiel workshop and audiotaped the relevant presentations. Most of the data reusers presented their findings and shared comments on their data reuse experience. Most of the data reusers were working with a specific subset of the data, but several worked with multiple subsets or collaborated with other members of the team. In addition to the participants in our study, the Kiel workshop featured a commentator and one presenter who stood in for one absent participant.
An hour-and-a-half focus group was held the day after the workshop. Five of the eleven zooarchaeologists, one data curator, and the workshop commentator (who is also a zooarchaeologist) participated in the focus group. We began the focus group with an exercise asking participants to specify whether twelve types of contextual information (e.g., measurement standards, stratigraphic information, coding sheet, research design) were important for reuse and then to rank the twelve types from most- to least-important. We used this exercise to prime and direct our focus group discussion about their reuse experience during the Anatolia Project.
Data analysis
The individual and focus group interviews and the e-mail exchanges were transcribed, checked for accuracy, and coded using NVivo. Three coders were involved in two rounds of coding. In round one codes were developed deductively and inductively using three sources: themes from the research literature, elements in the interview protocol, and topics that arose from the interviews themselves. The two assigned coders met regularly to discuss their level of agreement, determine whether they were assigning the codes appropriately, and nominate new codes for inclusion in the code set. The coders both coded each transcript.
In the first round of coding one of the emergent themes was the phenomenon we call virtuous and vicious circles. In the second round of coding, one of the original coders and a third individual coded on this theme by delineating the factors in one phase of the data life-cycle that impacted another either positively or negatively. They performed axial coding and analysis to better deconstruct the virtuous or vicious circles (Strauss and Corbin, 1990). The coders met regularly to compare notes and verify codes. There were 194 instances of coding representing links between different phases of the data life-cycle.
Next, we coded for factors described in each link. Factors were coded inductively. For example, data inconsistency was an overall factor and was used when the type of inconsistency was not specified. However, if the type of inconsistency was identified, we coded for that factor (e.g., chronology, measurement, standards). Twenty factors emerged from this coding process. Coding the links between the data life-cycle phases, followed by the subsequent identification of factors were essential processes for our analysis of the virtuous and vicious circles.
The other data, such as the conference presentations and our notes from the conference, project reports, and protocols generated by the curators were used as contextual information. These were not coded, but used to verify the information in the e-mail, interviews, and focus groups.
Findings
Previous research has shown that actions that occur in one phase of the data life-cycle indeed impact other phases (Carlson and Anderson, 2007). Our research bears this out and provides a fine-grained analysis of how this emanated in the Anatolia Project. In all, we found 194 links between life-cycle phases, where factors in one phase of the life-cycle impacted another. Our findings are structured around two frequently occurring factors: data inconsistency and data selection. These best demonstrate the interconnectivity as well as the creation of virtuous and vicious circles at the different phases in the data life-cycle. This findings section contains excerpts from several data sources we analysed during this project to shed light on our evidence for certain claims. While we attempt to provide partial context to elucidate the circumstances of each interaction, we purposely do not provide the data in full text, because doing so would necessarily de-anonymise the subjects.
Data inconsistency
Overall, production practices had an outsized impact on other life-cycle phases. Data production includes a wide range of practices including research design, data collection (e.g., excavation or survey), data recording, and data analysis (e.g., dating, measurement, and identification). Data creation practices in production were the root of many vicious circles that moved throughout the life-cycle. We begin our discussion of how data inconsistencies arising in the production phase influenced other life-cycle phases of the Anatolia project as well as how they were handled. Discussions of data production practices were salient during data sharing and curation. The zooarchaeologists identified several data production decisions that affected sharing. Data collection, terminology, chronology and stratigraphy, and measurement were mentioned most frequently.
Data collection
Overall, participants wanted to share good data. As a consequence, some engaged Curator12 in discussions of data quality prior to sharing. Transparency was a way to forestall the development of potentially vicious circles. For example, Zooarchaeologist10 was concerned about the introduction of bias given that some types of animal bones could be more easily identified than others:
One big bias that comes in is the criteria people use for deciding what counts as an identifier rather than what doesn't. And you could just include everything you can identify, but then you get biases because your red deer metatarsals are incredibly distinctive…and then it will look like your assemblage consists entirely of red deer.
Sampling decisions similar to the red deer discussion also affected curation protocols. Zooarchaeologist03 warned Curator13 of his varied data collection protocols in an e-mail, 'This is a reminder that my data ... need to be re-run since some contexts were sampled for all taxa while other were sampled only for sheep and goats.' In another e-mail exchange, Curator12 wrote Zooarchaeologist08 after noticing his data did not have individual identification numbers. It turned out that Zooarchaeologist08 also employed a sampling methodology and that led to describing fauna at a higher level of aggregation. He described his process in response:
I am preparing now the required datasets... Because part of the material... was recorded... with only few parameters (number of specimens by taxa for the bones which cannot be measured), I will not be able to provide completely full datasets—in the sense of "bone one by one"—for every occupation levels. However, all the data regarding the teeth and the measurable specimens have been recorded.
It is only after the curator noticed something was off and followed up with Zooarchaeologist08 that Zooarchaeologist08 thought to disclose his full data collection protocol. In this example, curation influenced sharing, thus averting a potential vicious circle.
Terminology
Data recording practices at the different sites led to differences in the terminology used to describe fauna. The different abbreviations and numerical shorthand systems plagued the curators. Zooarchaeologist06 described what he used for wild boar and domestic pig:
Usually I have different rows for mammal, fishes, molluscs. So, all these could be shifted into one row, and sometimes I'm just using abbreviations, or I just say wild boar is Sus scrofa, or domestic pig is Sus scrofa form of domestica with abbreviations. So this could be... so my original entries could be deleted because... or replaced by the, let's say, official links to the names.
Going into the project, the curators knew this would be a problem, that it could potentially induce a vicious circle, and that the inconsistent terminology needed rectification. As a result, they used a linked data approach to standardise species identification across datasets when possible to enable data integration and engaged the zooarchaeologists in this discussion.
Chronology and stratigraphy
Because chronology (periodization or dating) and stratigraphy were sometimes difficult to verify based on the shared data alone, the curators asked participants to share more information or protocols used during data production, particularly any guidelines for dating or placing objects within a particular stratum. In one conversational turn, Curator12 asks Zooarchaeologist02 to verify her chronology and explain her recording process for the stratigraphy:
I'm working on aligning your data now to the project. Do you have some periodization info you can give me for the main strata—Stratum 5, Stratum 6, and Context BBD look like the main ones. Even something like "Epipal" and "Late Neolithic" would be useful—I'd liked to have the divide between those two. You also have 10 specimens from Area A. If you have it, it would be ideal if you could provide the info for those 10, which come from Stratum 1, Context AAB, and Context AAR.
The protocols for interpreting the chronology and phasing of faunal remains were essential for answering the research questions posed for the Anatolia Project. Unable to understand the unique working styles that precipitated such inconsistencies, the curators' processes impacted sharing to ensure data would be interpreted accurately during reuse. While this could stop vicious circles from forming, we also found that curators could potentially introduce vicious circles into the data life-cycle between sharing and curation. For example, Curator13 discussed the inferences he had to make when preparing the data:
Once I have the dates, then it'll take a bit of time to generate new export tables. There is a huge amount of inference…that goes into this, which is time and processor consuming. But it is the price one pays for trying to stay close to the researcher's original descriptions. But I'd love to get this all out the door today, since Zooarchaeologist10 is headed off to the field and we need to give people plenty of time for analysis.
Zooarchaeologist01 discussed problems with both the terminology used to identify pigs and the chronology or periodization. She also disclosed her solution for dealing with the date ranges during reuse:
I think I had to fiddle with it quite a lot...Because people use different terms for different things so I seem to remember there was issues between what people... called the wild pigs and the domestic pigs and the order of the words. So there was kind of lots of that sort of manipulation that went on. But I think the biggest thing that I have tried to deal with was... 'cause the date ranges weren't particularly useful... a date range is very hard to deal with data. I think I just took the average of the date range. That's what I ended up doing and deciding that was the date.
Measurement
Interestingly, the use of data recording standards during data production did not eliminate data inconsistency throughout the life-cycle. One major frustration stemmed from conflicting usage of Payne's 1973 system for categorizing tooth eruption and wear. While the standard is widely used and accepted, recording practices differed and some of the zooarchaeologists enhanced the standard with personal or regional variations. During data production, Zooarchaeologist03 developed a version of the Payne system for recording articulating teeth which led to the following exchange with Curator13 during sharing:
Curator13: We're over-counting your teeth! I'm adding a query term to exclude the "articulates" specimen!
Zooarchaeologist03: Sorry my data are causing trouble. I usually use the number of specimens with Diagnostic Zones to quantify my taxonomic frequencies (articulated teeth will have a 0 for this field). But maybe it is easier to exclude the articulating teeth.
Curator13: Not a problem, it's fun to have some challenges like this, since it really shows how interesting it is to work with data. I generated explicit articulation links in your dataset so it's was easy to exclude those specimen that articulated with another specimen. Ilipinar worked similarly, though the ids in that dataset were not consistent, so I wasn't able to match most of the bones with articulation links.
In a series of e-mails with Zooarchaeologist03, Curator12 discussed the problems of curating the tooth wear data in a way that made integrating across the datasets easier:
We do have tooth wear data, but it just wasn't in a format that could be clearly integrated. Some sites have clear A, B, C phases, while others have number codes by tooth. We could provide all of that to the analysts, but it will be a lot of columns of pretty disparate data…Just so you have an idea of the issue with tooth wear...The following sites all record a single field "Payne Wear" (or something similar) where they give a summary letter age to the specimen... The two [site name] datasets and [Zooarchaeologist05]'s two datasets all code each tooth in a separate field with a Payne number. But they don't come up with a letter code for the entire specimen. (So, they have p3/P4, M1, M2, M3 all listed separately but don't summarise them into one field)....
Consequently, the vicious circle carried forward to affect reuse. Zooarchaeologist05 described experiences with analysing tooth wear data from different sites:
And we all use the same thing, it's Sebastian Payne's 1973 article; assigning numbers and letter codes to individual teeth. But that was the worst thing I've ever had to do in my entire career because people use it so differently. The same thing, same source, we all started from the same thing and supposedly we all used the same reference codes.
At one point there was a particularly long e-mail chain, where the curators 12 and 13, translated the data producer's (Zooarchaeologist06) tooth wear interpretations for data reuser (Zooarchaeologist05):
Zooarchaeologist05: [Zooarchaeologist06] entered "dp4 5-7; m1-3" into Payne stage field. It is not difficult to get that he has a mandible fragment with dP4 and M1 present. But I am confused as to what "5-7" and "1-3" refer to here.
Curator12 to Zooarchaeologist05: I see what you mean. I thought these were Payne wear notations, but they don't make sense because they only go up to 10 or so.
Curator12 to Zooarchaeologist06: Can you send me some information about how you coded Payne tooth wear for your two sites? …
Zooarchaeologist06: Yes I understand what you mean the problems started as I/we use/used another way coding teeth abrasion…Meanwhile I'm recording the eruption and abrasion in our 'traditional' way and I'm using Payne's wear stages, but I don't assign the stages A, B, C… to the raw data. The coding is very simple … I just took the drawings of Payne and numbered them:
In this case, after several additional turns in the conversation, the tooth wear coding and how Zooarchaeologist06 used the Payne standard were clear. This exchange also inspired change; Zooarchaeologist06 altered his recording practices to those of the Payne standard:
Well, in my case it changed already because... I had a completely different recording system for [teeth]... So, meanwhile, I'm working with the material by just using the Payne... I'm just measuring the teeth now. So that changed already. Yeah, I think all the descriptives are more or less the same. What I would add to the databank about the pathologies [is butchering, traces] and stuff like that.
He was not the only one. Two other zooarchaeologists also rethought their data production protocols as a result of data reuse, particularly their data collection and recording practices:
When I worked with other people's data...That also made me more conscious about the way I look at my own data... it actually has changed, tremendously changed the way I look at my own data and data collection. (Zooarchaeologist05)
The two things that I would now do differently: One of them is writing down with my data what exactly all those criteria are. Which I always kind of had a few notes on it, but some more... Writing down more systematically exactly what those criteria have been. And second one is just dropping numeric codes, not doing all of the numeric codes anymore. (Zooarchaeologist10)
Findings show how different zooarchaeologists reusing these data dealt with vicious circles rooted in data production practices that led to inconsistency in the data. While the curators worked to overcome and ameliorate the problems, this was not always possible. When vicious circles were carried forward, data reusers employed various strategies: asking the curators questions, using the curators as intermediaries, asking questions directly to the data producers, or excluding data that was not understandable. In the next section we examine data sharing and different strategies to make data meaningful to others and thus create a more virtuous circle.
While these findings show the origins of vicious circles and the ways in which curatorial interventions attempted to transform them into virtuous ones, exposure to other's data during reuse was a powerful influence on the zooarchaeologists. Two participants exhibited an increased data sharing culture and articulated greater interest in data sharing. Reflecting on what it would take to ease reuse, Zooarchaeologist04 pondered how thinking more about sharing could influence data production:
I'm really curious to see where this will go to after this relatively small project - will [it] lead to sharing more data, doing more collaborative papers, even asking each other before we start collecting data from a particular site for example, asking like, do you want me to collect data in this way so that eventually in, I don't know, three years we can publish together?
Understanding the importance of better prepared datasets and documentation for sharing and reuse, Zooarchaeologist10 specifically asked his university whether it had funds to support preparing some of his datasets for publication. 'I sent an e-mail yesterday… specifically saying, ‘Do you support funding for online data application?'… I have small datasets which I quite like to send to Open Context now... Which I probably wouldn't have thought about doing before'.
As a result of these conversations, Curator 12 also speculated how data sharing might impact data production in the future:
It's really interesting to see how when you have access to each other's raw data and you see how people record things. And already we've had a bunch of things emerge, where people are saying, 'We all need to be doing this'. … We're raising the bar for like, 'What are we recording?' And hoping to channel it a little bit into more standard fields, which is really interesting 'cause that doesn't tend to happen because people never see people's raw data.
Curator12's statement reveals a central principle to virtuous circles in data; that enforced changes in practice would not only alter the course of the Anatolia Project; 'raising the bar' and the transparency brought about by increased access changes scholars' perceptions on what is acceptable in their work. Data sharing, in this instance, resulted in zooarchaeologists seeing one another's data, pulling back the curtain on the massive inconsistencies and lack of standardization. Such collaboration does not merely affect this project's success; it results in lessons learned by all parties, thus enabling virtuous circles to continue to augment further projects and datasets.
Data selection
The interviews and focus group revealed that a number of the zooarchaeologists shared only selected data from larger datasets. Data selection was the most frequently coded factor demonstrating how production affected sharing. These selection decisions also had implications for curation and reuse. Data sharers made different decisions about sharing or not sharing parts of the data as well as whether they would inform the curators of their data selection decisions. Reasons for not sharing included judgments that certain parts of the data were not pertinent to the research questions for the Anatolia Project, the perceived effort involved in explaining parts of the data to a reuser, and data ownership.
Data selection occurred despite curatorial encouragement to share as much as possible, resulting in a dire lack of complete information during secondary analysis. Because sharers made judgments based on their own analytical work, selection practices reduced the adaptability of their data for the Anatolia Project as well as others. As the Anatolia Project developed, selection scenarios were discovered that led to vicious circles for reusers, but the challenges selection caused were resolved by curators, who encouraged virtuous circles. For example, Curator12 encouraged one participant to share all of his data, not just the portion most relevant to the Anatolian project:
While you work on the decoding, think about including all taxa and elements for each of your sites. While the other taxa (non sh/g/bos/pig) won't be considered in our study, for the data publications, it makes more sense to have full datasets. Otherwise, future analysts might think your site only had sheep and goat.
Ironically, participants made data selection decisions to ease the burden on the curator as well as to provide reusers with just the specific data they needed for the Anatolia project. Zooarchaeologist04 reports:
I also cleaned everything as much as possible, so for example I only sent sort of standard things like species. So I didn't send for example butchery marks, which I have a very specific code for…it wasn't necessary for this particular data sharing so that was cut...But I sent, yeah, information about 20,000 specimens, 20,000 fragments, very big data from a long sequence from the site though, like a thousand years, it covered. I only sent mammal data. I see that one person or two they also sent non-mammal data… because now I need that data. Um, so I was doing this, I filtered this a little bit. I didn't change it.
Rationales for data selection
Several of the zooarchaeologists provided rationales for how they determined the data they would share. These discussions focused on the circumstances of production: data ownership (Zooarchaeologist10), inconsistent recording of data (Zooarchaeologist03), missing data (Zooarchaeologist08), and the effort involved in reformatting the original data (Zooarchaeologist11). In each of these instances, the zooarchaeologist entered into a conversation with Curator12 who documented the production factors driving the selection rationale. For example, Zooarchaeologist11 explained her selection criteria to Curator12 noting that she could only share what had already been entered into digital (spreadsheet) format:
The raw data from [site name] are handwritten and the files that I sent you: this is how I have compiled the data at that moment for publication. If you need a more detailed spreadsheet, I'll have to start from scratch and that is something that I can't do now... I'm sorry. I hope that the files will anyhow be useful in some way.
During reuse, Zooarchaeologist03 had trouble with the chronological phasing, but acknowledged that since archaeological excavations take place over years if not decades, chronological phasing is often reinterpreted in light of new excavation. His solution, unlike Zooarchaeologist01 in the previous section, was to exclude data that he felt were not precisely phased:
I tried to use as much as I could, but some of the data did not have clear chronological phasing for example. So, for a site like [site name], which has dozens of phases and a huge period of time. If there are specimens that are not precisely phased like in that time period, I did not use those. And that's a problem with this project, that's a problem with all archaeological projects, because the understanding the phasing always changes over time and it often takes sort of 10 years into a project before the chronology really gets worked out. Such, that's just the nature of working with these datasets.
By raising these issues with the curator while deciding what to share, producers may have disrupted vicious circles and saved time and energy on the part of the curators and reusers.
Communication before sharing was an opportunity for the curator and producer to discuss factors affecting the data, negotiate data selection, and educate the data producer about what the curator could fix, rather than having the producer decide to only share what was perceived as good data. For example, Zooarchaeologist10 used data ownership, marked by the transfer of authority at an archaeological site, as his rationale for sharing data only through 2008:
So [the new site director] has now come in and started working and they're using different criteria for what counts as the evidence that we record to species and which of the evidence that we don't record to species routinely only if it's something special. And that's gonna very subtly, very subtly but systematically bias the entire… But people need to be aware of that. And that's why one of the reasons why we haven't included any of [the site director's] new data.
Zooarchaeologist09 decided not to share some site-specific information because it added noise:
You had to decide whether you would like to share everything or not because there's a lot of archaeologically-related information like unit numbers or some kind of division of the unit which probably is not comprehensible to people who do not know of the site and the importance of it. So I think that I just removed couple of information of that site and of the noise that I thought would not be comprehensible and not of use.
The following focus group exchange showed the zooarchaeologists' ambiguous feelings about selection:
Zooarchaeologist08: I extract only a part of the database and I share with other colleagues. It's not complete…
Focus group leader: Is it important to know what other data might exist or is getting a portion of the dataset with a minimum number of fields good enough?
Zooarchaeologist08: Probably yes.
Zooarchaeologist10: It depends what you're reusing it for.
Zooarchaeologist10 considered reusers' potential difficulties when selecting the data but also noted the limits of his own efforts to correct or clean the data. Many of the selection decisions were made to avoid creating problems or vicious circles. However, as we will see in the next section focusing on data reuse, selection decisions did create some vicious circles and went on to impact the reuse phase.
Data selection and reuse
Data selection during sharing impacted reuse as strongly as it did data curation. Some of the zooarchaeologists informed the curators of their selection decisions, enabling the curators to document the selection criteria and create a virtuous circle. In other cases, the zooarchaeologists only revealed their data selection when asked. Two separate factors in these situations have the potential carry forward vicious circles. First, the selection of data itself, and second, the non-disclosure of data selection. While documenting selection criteria does create more work for the data producer and/or the curator, curatorial documentation of selection criteria does curtail vicious circles. This becomes evident during data reuse where our findings demonstrate how selection can impact reuse.
Zooarchaeologist04 relayed how selective data sharing impacted Zooarchaeologist01's ability to carry out her analyses:
But [Curator12] sent us only part of the data that we needed. I got the pig biometry and then, yeah, there was a problem, for example for [Zooarchaeologist01]... she just received, I think the [biometric] species and the fusion and dental data which she had to know the biometry too... She had to know more.
While Zooarchaeologist01 chose to use all of her assigned data, she cited the missing data and lack of clarity concerning the representativeness of the data as impediments to analysis despite the hard work of the curators. She also mentioned other data reuse projects and the problems associated with aggregating very old data dating from the nineteenth century:
We don't see is all the hard work at the beginning, where… [the curators] somehow managed to make all of this data appear... And also, yes, I guess I don't know what was left behind... It was like, ‘Was there lots of other stuff that isn't there? Is there data that you can't use?' Because I used everything that was given to me. And again, I don't know what's missing. And I do know from lots of sites you just can't use data because it's stupid data...but where we work you get stuff that's been dug up in the... 1890s and stuff, and then those datasets, if they exist, are just entirely corrupted prior to you actually getting the data anyway. So, I guess, yes, I just trusted that the datasets [from the Anatolia Project] were representative of what they were representative of.
Ambiguity also surrounded missing data. The zooarchaeologists were not sure if data were truly missing, never collected, or if their colleague made a selection decision not to include certain types of data. Zooarchaeologist02 was contacted by several other participants asking whether she had selected data and had additional data to fill in some gaps. Zooarchaeologist02 recalls, 'More people just asking "Do you have any pig measurements? Do you have anything that they couldn't see?"... And it was a simple question, me responding, "No, I didn't have any measurements".' In the focus group, Zooarchaeologist08 noted that 'the datasets are not complete,' and went on to say he assumed that everyone only shared the data most pertinent to the research questions.
In the section on data inconsistency, we saw how data reuse had the potential to influence future data production and sharing. During reuse, Zooarchaeologist05 asked Curator12 to verify whether data were missing or had not been shared. Curator12 responded by stating how act of reuse influenced curation, helping her achieve better quality control:
No problem with the questions [on missing data] – it's really important to check on these things! Plus, you got what is perhaps the most challenging dataset because of the different ways everyone records Payne's stages, so I expected you might have questions. BTW - Having you going through the data like this helps with editorial quality control, which is super helpful in the data publishing process.
The types of questions the curators received helped them to understand where they could be more transparent about the data and thus informs both curation as well as their interactions with future data producers working on other datasets.
Discussion
Data production, particularly the introduction of local practices leading to inconsistent data across sites, had an outsized influence on subsequent phases in the data life-cycle. There was also a greater propensity of data production factors to create vicious circles. In contrast, curation practices represented the most positive force for changing vicious into virtuous circles. Furthermore, data selection decisions, both communicated and not communicated, impacted the work of sharing, curation, and reuse. Finally, the act of reuse had a positive influence on all other phases in the life-cycle.
The role of data production in the formation of vicious circles
Data production had the greatest influence on other phases in the data life-cycle.
Data collection and data management inconsistencies were the most problematic. However, we found that the zooarchaeologists developed strategies to deal with inconsistent data, rather than abandon reuse. Data production issues stemmed from interpretation and localised data collection and recording practices. While interpretation will always be variable, localised and idiosyncratic recording practices can be mitigated through both higher level disciplinary-wide standards (e.g., controlled vocabularies and agreed upon metrics for existing standards such as Payne) and best practices as well as more attention to detail and consistent data entry at archaeological sites, such as the development of systems with automatic checks, standardised training of those recording data and systems that provide some automatic checks on data entry (Faniel et al.
, 2018). However, research shows different data collection and recording practices often occur among researchers working in teams for various technical as well as organizational reasons (Darch et al., 2015; Akmon et al., 2011). These kinds of embedded localised practices have been identified with the development of vicious circles. In terms of the Anatolian Project, each individual archaeological site may indeed have benefitted from embedded practices and research protocols. As the data moved away from the site, however, a vicious circle began to form as the larger archaeological community could not readily use the data to address larger research questions about social, cultural, and economic changes across geographic regions.
Garud and Kumaraswamy (2005) designated these localised practices as a single loop learning—practices that work well inside a unit—but view such practices as ultimately stifling. They argue that, in a virtuous circle, information sharing leads to double loop learning and innovation. 'The balance that an organization strikes between these two types of learning can have an important bearing on whether or not it can harness its knowledge system to yield a virtuous knowledge circle' (Garud and Kumaraswamy, 2008, p. 11). To fully counteract the vicious circles that such localised inconsistent production practices cause, a larger cultural shift must occur within archaeology and other fields with similarly nascent systems of sharing and reuse. Injecting double loop learning mechanisms will encourage better data sharing and reuse.
Data selection as a factor in data sharing
Data selection was a key factor influencing both curation and reuse. However, the variety of rationales for data selection was illuminating. Data producers made selection decisions for practical, legal, and personal reasons. These decisions balanced the amount of time they wanted to spend preparing the data with what they perceived the data reuser would need. The accessibility of data, changes in data recording practices, data ownership, and not wanting to share incomplete data all came up when participants discussed selection. Furthermore, not all the participants disclosed their selection decisions to the curator during data deposition. Although the curators requested extensive metadata and contextual information, requests did not specify the need for data selection decisions during deposition. Yet, our findings suggest that this is important contextual information for reuse.
The positive impact of curation
While some of the zooarchaeologists mentioned the impact of curation on reuse, we know from other studies that the effort involved in reusing data has an impact on the willingness to reuse data (Curty and Qin, 2014). In our case study, the curators did a substantial amount of work to lessen the effort of the data reusers. In their initial Guidelines document, the curators asked data sharers to decode their datasets, but only a couple of the zooarchaeologists did so. This could have created vicious circles, but the curation efforts both lessened the amount of effort required of data sharers and mitigated problems in the shared data thus creating virtuous circles.
In our case study, we found that curation practices consistently transformed potentially vicious into virtuous circles. This often involved a heroic effort on the part of curators. Garud and Kumaraswamy (2005) refer to this type of activity as 'steering' (p. 27), or actively intervening in the data life-cycle to fix a problem causing a vicious circle. The critical role of the curator in steering throughout the data life-cycle is important to consider. Garud and Kumaraswamy (2005) see the role of steering and targeted intervention as necessary. Witt (2008) and Ogburn (2010) both argue for this type of intervention in data curation. This raises several issues for curation practices. First, the necessity of intervention early in the data life-cycle, during production or even in the research conceptualization phase to ensure data collection practices are transparent and adaptable for many subsequent research needs. Second, this implies that curators must assume more responsibility to ensure the deposit of high-quality data and documentation thereby enabling data sharing and facilitating reuse. Finally, it requires data producers and reusers to put an extraordinary amount of trust in the curators, letting the curators suggest standards, data structure solutions, and data recording norms.
The role of reuse in fostering virtuous circles
Data reuse was the one phase that positively influenced all other phases. In our case study, the act of reuse initiated personal reflection about how to improve one's own data production in terms of collection, recording, and management practices. Reuse also provided the curators with information about which curation activities added the most value for data reuse. Likewise, successful reuse encouraged greater data sharing. While we only saw a modicum of evidence for these changes in attitude, we observed the beginnings of a stronger collaborative data sharing and reuse culture. How we might encourage the emergence of these virtuous circles bears consideration. If reuse, even with frustrations, can change attitudes toward better data production, curation, and sharing, imagine the possibilities of disciplinary change if curators assumed an even greater steering role and the factors causing such frustrations were diminished through concerted change in the research culture.
Conclusion
Although it is known that actions in one part of the data life-cycle impact other parts, this study highlights the extent of the impact. One optimistic note about this case is that, although we saw the development of vicious circles, we also saw that they can be reversed. By framing the discussion around the data life-cycle, complex interdependencies and influences between phases became exposed. The reach that data production practices had on the other phases was palpable, as were the laborious curatorial interventions, which worked to reverse factors that negatively influenced curation and reuse. As shown in the case, some zooarchaeologists had difficulties preparing their data for deposit. Until this activity, most were unaware of the undue influence their idiosyncratic data documentation and management practices could have on themselves, data curators and reusers. As the reusers worked with the data, such influences drastically impeded their work and threatened success of the Anatolia Project, challenges that curators mitigated during engaged intervention.
This project turned into an experiential learning exercise that led the reusers to consider changes in their own data production practices; it also helped curators identify areas of intervention. Judging from reusers' remarks, such intervention directly enabled the project's success through focused collaboration. Data producers partnering with data curators to steer the data production process – after data management planning and before data deposit – is critical, as is making time to periodically reflect on current data production and management practices as a means to improve processes and reduce work for themselves as well as others. In addition to developing the Anatolia Project workflow, the lessons learned by scholars as a result of this case study lead us conclude that the experience of data reuse—and a more robust reuse culture at large—can lead to improved production practices, increased openness to sharing, greater curatorial awareness, and greater success in data reuse. Future research projects need to examine the nature of such effects. For example, how might rigorous data production standards limit producers, despite the benefits for reusers? Also, further study in other disciplines of how practices in the different life-cycle phases interact to form vicious and virtuous circles can help situate our project in an interdisciplinary context.
Acknowledgements
This research was made possible in part by a grant from the United States Institute of Museum and Library Services, Laura Bush 21st Century Librarian Program, 'Research Experience for Masters Students', #RE-01-15-0086-15. We also want to acknowledge the Encyclopedia of Life, Computable Data Challenge award to the Alexandria Archive Institute for the 'Biogeography of Animal Domestication Using EOL' project and the National Endowment for the Humanities Digital Humanities Implementation grant #HK-50037-12, 'Applying Linked Open Data: Refining a Model of Data Sharing as Publication', which supported the project we were able to study.
About the authors
Elizabeth Yakel is a Professor and Associate Dean for Academic Affairs at the University of Michigan School of Information in Ann Arbor, Michigan, USA. She graduated from Brown University, USA with a Bachelor's degree in English and earned a Master's degree in Library and Information Science and a PhD at the University of Michigan. Her research currently focuses on data reuse and how to ensure that research data remains technically renderable as well as meaningful over time to those who did not originally collect or produce the data. Her research has been funded by the Andrew W. Mellon Foundation and the Institute for Museum and Library Services (IMLS), among others. She can be contacted at: yakel@umich.edu. Ixchel M. Faniel is a Senior Research Scientist at OCLC in Dublin, Ohio, USA. She graduated from Tufts University, USA with a Bachelor's degree in Computer Science and earned a Master of Business Administration and PhD in Business Administration at the University of Southern California, Marshall School of Business, USA. Her interests include improving how people discover, access, and use/reuse content. She is currently examining research data management, sharing, and reuse within academic communities and students' identification and evaluation of digital resources. Ixchel's research has been funded by the National Science Foundation (NSF), Institute of Museum and Library Services (IMLS), and National Endowment for the Humanities (NEH). She can be contacted at fanieli@oclc.org. Zachary Maiorana is a second-year Master of Science in Library and Information Science student as well as a Pre-professional Graduate Assistant for the Library's Researcher Information Systems division and an Administrative Support Graduate Hourly for the Library's Preservation Services unit at the University of Illinois at Urbana-Champaign, USA. His current research interests include human interactions with information in data life-cycles as well as innovations in shared print collection management. He received his Bachelor's degree in English and linguistics with minors in history and German from The Ohio State University, USA. He can be contacted at: zjm4@illinois.edu.
References
Akmon, D., Zimmerman, A., Daniels, M. & Hedstrom, M. (2011). The application of archival concepts to a data-intensive environment: Working with scientists to understand data management and preservation needs. Archival Science, 11(3–4), 329–348.
Arbuckle, B. S. (2013a). Erbaba Höyük and suberde zooarchaeology [Data set]. San Francisco, CA: Alexandria Archive Institute, Open Context. Retrieved from https://opencontext.org/projects/CDD40C27-62ED-4966-AF3D-E781DD0D4846 (Archived by WebCite® at http://www.webcitation.org/763GA9H7f)
Arbuckle, B. S. (2013b). Köşk Höyük faunal data [Data set]. San Francisco, CA: Alexandria Archive Institute, Open Context. Retrieved from https://opencontext.org/projects/05F5B702-2967-49B1-FEAA-9B2AA0184513 (Archived by WebCite® at http://www.webcitation.org/763I0dG8e)
Atici, L. (2013a). Zooarchaeology of Karain Cave B [Data set]. San Francisco, CA: Alexandria Archive Institute, Open Context. Retrieved from https://opencontext.org/projects/731B0670-CE2A-414A-8EF6-9C050A1C60F5 (Archived by WebCite® at http://www.webcitation.org/763I32LmR)
Atici, L. (2013b). Zooarchaeology of Öküzini Cave [Data set]. San Francisco, CA: Alexandria Archive Institute, Open Context. Retrieved from https://opencontext.org/projects/8894EEC0-DC96-4304-1EFC-4572FD91717A (Archived by WebCite® at http://www.webcitation.org/763IUNRN5)
Atici, L., Kansa, S., Lev-Tov, J. & Kansa, E. (2012). Other people's data: a demonstration of the imperative of publishing primary data. Journal of Archaeological Method and Theory, 20(4), 663-681
Berg, M. & Goorman, E. (1999). The contextual nature of medical information. International Journal of Medical Informatics, 56(1–3), 51–60.
Birnholtz, J. P. & Bietz, M. (2003). Data at work: Supporting sharing in science and engineering. In GROUP ‘03 Proceedings of the 2003 International ACM SIGGROUP Conference On Supporting Group Work, Sanibel Island, Florida, USA (pp. 339–348). New York, NY: ACM.
Borgman, C. L., Wallis, J. C. & Mayernik, M. S. (2012). Who's got the data? Interdependencies in science and technology collaborations. Computer Supported Cooperative Work, 21(6), 485–523.
Borgman, C., Wallis, J. C. & Enyedy, N. (2006). Building digital libraries for scientific data: an exploratory study of data practices in habitat ecology. In J. Gonzalo, C. Thanos, M. F. Verdejo & R. C. Carrasco (Eds.), Research and advanced technology for digital libraries. 10th European Conference, EDCL 2006, Alicante Spain, September 17-22, 2006, Proceedings (pp. 170–183). Berlin, Heidelberg: Springer Verlag. ( Lecture notes in computer science, 4172).
Buitenhuis, H. (2013). Ilıpınar zooarchaeology main zooarchaeological dataset [Data set]. San Francisco, CA: Alexandria Archive Institute, Open Context. Retrieved from https://opencontext.org/tables/3746e117f8bd3c648568cdd59d00272c (Archived by WebCite® at http://www.webcitation.org/763LXEu9L)
Çakırlar, C. (2013). Zooarchaeology of Neolithic Ulucak [Data set]. San Francisco, CA: Alexandria Archive Institute, Open Context. Retrieved from https://opencontext.org/projects/99BDB878-6411-44F8-2D7B-A99384A6CA21 (Archived by WebCite® at http://www.webcitation.org/763LhYzSD)
Carlson, J. (2014). The use of life cycle models in developing and supporting data services. In J. M. Ray (Ed.), Research Data Management: Practical Strategies for Information Professionals (pp. 63-86). West Lafayette, IN: Purdue University Press.
Carlson, S. & Anderson, B. (2007). What are data? The many kinds of data and their implications for data re-use. Journal of Computer-Mediated Communication, 12(2), 635–651.
Carruthers, D. (2013). Pınarbaşı EOL computational data challenge revised zooarchaeology dataset [Data set]. San Francisco, CA: Alexandria Archive Institute, Open Context. Retrieved from https://opencontext.org/tables/2e995b59d5adf5b079fde6cea24b251d (Archived by WebCite® at http://www.webcitation.org/763OPxu01)
Chin, G. & Lansing, C. S. (2004). Capturing and supporting contexts for scientific data sharing via the biological sciences collaboratory. In CSCW '04 Proceedings of the 2004 ACM Conference On Computer Supported Cooperative Work, Chicago, Illinois, USA (pp. 409–418). New York, NY: ACM.
Curty, R. G. & Qin, J. (2014). Towards a model for research data reuse behavior. Proceedings of the American Society for Information Science and Technology, 51(1), 1–4. Retrieved from https://onlinelibrary.wiley.com/doi/full/10.1002/meet.2014.14505101072 (Archived by WebCite® at http://www.webcitation.org/763OouVeo)
Darch, P. T., Borgman, C. L., Traweek, S., Cummings, R. L., Wallis, J. C. & Sands, A. E. (2015). What lies beneath?: Knowledge infrastructures in the subseafloor biosphere and beyond. International Journal on Digital Libraries, 16(1), 61–77.
DataONE. (n.d.). Data life cycle. Albuquerque, NM: DataONE. Retrieved from https://www.dataone.org/data-life-cycle (Archived by WebCite® at http://www.webcitation.org/763Oy7vwJ)
Edwards, P.N., Mayernik, M.S., Batcheller, A.L., Bowker, G.C. & Borgman, C.L. (2011). Science friction: data, metadata, and collaboration. Social Studies of Science, 41(5), 667–690.
Faniel, I. M. & Jacobsen, T. E. (2010). Reusing scientific data: How earthquake engineering researchers assess the reusability of colleagues' data. Computer Supported Cooperative Work, 19(3–4), 355–375.
Faniel, I. M., Austin, A., Kansa, E., Kansa, S. W., France, P., Jacobs, J., … Yakel, E. (2018). Beyond the archive. Advances in Archaeological Practice, 6(2), 105–116.
Faniel, I., Kansa, E., Whitcher Kansa, S., Barrera-Gomez, J. & Yakel, E. (2013). The challenges of digging data: a study of context in archaeological data reuse. In Proceedings of the 13th ACM/IEEE-CS Joint Conference on Digital Libraries - JCDL '13, Indianapolis, Indiana, USA (p. 295). New York, NY: ACM Press.
Galik, A. (2013a). Barçın Höyük zooarchaeology [Data set]. San Francisco, CA: Alexandria Archive Institute, Open Context. Retrieved from https://opencontext.org/projects/74749949-4FD4-4C3E-C830-5AA75703E08E (Archived by WebCite® at http://www.webcitation.org/763PKQj7D)
Galik, A. (2013b). Çukuriçi Höyük zooarchaeology [Data set]. San Francisco, CA: Alexandria Archive Institute, Open Context. Retrieved from https://opencontext.org/projects/BC90D462-6639-4087-8527-6BB9E528E07D (Archived by WebCite® at http://www.webcitation.org/763PTtvqx)
Garud, R. & Kumaraswamy, A. (2005). Vicious and virtuous circles in the management of knowledge: the case of Infosys Technologies. MIS Quarterly, 29(1), 9-33
Gourichon, L. & Helmer, D. (2014). Faunal data from Neolithic Menteşe [Data set]. San Francisco, CA: Alexandria Archive Institute, Open Context. Retrieved from https://opencontext.org/projects/42EAD4DB-BAED-4A58-9B9B-7EC85266D2A9 (Archived by WebCite® at http://www.webcitation.org/763Pm87Hw)
Hillier, B. & Penn, A. (1994). Virtuous circles, building sciences and the science of buildings: using computers to integrate product and process in the built environment. Design Studies, 15(3), 332–365.
Kansa, S. W. (2013). Domuztepe EOL computational data challenge revised zooarchaeology dataset [Data set]. San Francisco, CA: Alexandria Archive Institute, Open Context. Retrieved from https://opencontext.org/tables/6354e1db8815494679677836472c639c (Archived by WebCite® at http://www.webcitation.org/763QcGLkM)
Lord, P., Macdonald, A., Lyon, L. & Giarretta, D. (2004). From data deluge to data curation. In Proceedings of the UK e-Science All Hands Meeting 2004 (pp. 371–375). Swindon, UK: Engineering and Physical Sciences Research Council. Retrieved from http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.111.7425 (Archived by WebCite® at http://www.webcitation.org/763Qqcikq)
Marciniak, A. (2013). Çatalhöyük Area TP zooarchaeology [Data set]. San Francisco, CA: Alexandria Archive Institute, Open Context. Retrieved from https://opencontext.org/projects/02594C48-7497-40D7-11AE-AB942DC513B8 (Archived by WebCite® at http://www.webcitation.org/763w4Sv2r)
Masuch, M. (1985). Vicious circles in organizations. Administrative Science Quarterly, 30(1), 14-33.
Ogburn, J. L. (2010). The imperative for data curation. Portal: Libraries and the Academy, 10(2), 241–246.
Strauss, A. L. & Corbin, J. M. (1990). Basics of qualitative research: grounded theory procedures and techniques. Thousand Oaks, CA: Sage Publications.
Rolland, B. & Lee, C. P. (2013). Beyond trust and reliability: reusing data in collaborative cancer epidemiology research. In CSCW '13 Proceedings of the 2013 conference on computer supported cooperative work, San Antonio, Texas, USA. (pp. 435–444). New York, NY: ACM.
Stephens, D. O. (2007). Records management: making the transition from paper to electronic. Overland Park, KS: ARMA International.
US. National Archives and Records Administration. (2017). The records management life cycle. In NARA records management training – MIST instructional design project [SlideShare slides]. Retrieved from https://www.slideshare.net/adinscore/nara-records-management-training-mist-instructional-design-project/28 (Archived by WebCite® at http://www.webcitation.org/763wG0Khg)
Van House, N. A. (2002). Trust and epistemic communities in biodiversity data sharing. In Proceedings of the Second ACM/IEEE-CS Joint Conference on Digital Libraries - JCDL '02, Portland, Oregon, USA (pp. 231-239). New York, NY: ACM Press.
Van House, N. A., Butler, M. H. & Schiff, L. R. (1998). Cooperative knowledge work and practices of trust: sharing environmental planning data sets. In CSCW '98 Proceedings of the 1998 ACM Conference on Computer Supported Cooperative Work, Seattle, Washington, USA (pp. 335–343). New York, NY: ACM.
Witt, M. (2008). Institutional repositories and research data curation in a distributed environment. Library Trends, 57(2), 191–201.
Yoon, A. (2016). Red flags in data: Learning from failed data reuse experiences. ASIS&T Annual Meeting Proceedings, 53(1), 1-6.
Zimmerman, A. S. (2008). New knowledge from old data: the role of standards in the sharing and reuse of ecological data. Science, Technology & Human Values, 33(5), 631–652.
How to cite this paper
Yakel, E., Faniel, I.M. & Maiorana, Z.J. (2019). Virtuous and vicious circles in the data life-cycle. Information Research, 24(2), paper 821. Retrieved from http://InformationR.net/ir/24-2/paper821.html (Archived by WebCite® at http://www.webcitation.org/78mo44T8I)