Web credibility assessment: affecting factors and assessment techniques
Asad Ali Shah, Sri Devi Ravana, Suraya Hamid and Maizatul Akmar Ismail
Faculty of Computer Science and Information Technology, University of Malaya, Kuala Lumpur, Malaysia
Introduction
The Webster dictionary defines credibility as ‘the quality or power of inspiring belief’(Credibility, 2003). Credibility consists of objective as well as subjective parts, of the believability of the content (Flanagin and Metzger, 2008), which may be in the form of a book, newspaper, electronic document or any other document type containing data. This article will focus on Web content for credibility assessment. According to Fogg and Tseng (1999), credibility is based on two key components: i) trustworthiness and ii) expertise. Although there are multiple dimensions to credibility the majority of researchers agree that a person uses both trustworthiness and expertise to make credibility assessment. Both of these components have objective and subjective components. Subjective components relate to the user’s perceptions or judgment, while objective components refer to properties of the source or content. Trustworthiness of content is defined in terms of being well-intentioned, truthful and unbiased; while expertise is defined as being knowledgeable, experienced and competent (Fogg and Tseng, 1999).
The definition of credibility is discipline-specific as each discipline weighs different components differently. For instance, psychology and communication put more emphasis on reputation and reliability of the source, while information science focuses on the accuracy and quality of the content itself. Therefore, credibility can consist of multiple concepts such as trust, reliability, accuracy, reputation, quality, authority and competence, where each concept may add up to trustworthiness or expertise: reputation, reliability and trust add up to trustworthiness, while quality, accuracy, authority and competence add up to expertise.
Significance of Web credibility
The Web has become a familiar way of acquiring and sharing information that also allows users to contribute and express themselves (Ward, 2006). Wikipedia statistics note that there are over 33.5 million Wikipedia articles in all languages with approximately 672 million views per day (Wikipedia Statistics, 2014). According to the latest figures, out of the total population of just over seven billion people, 42% are Internet users with a 741% increase from 2000 to 2014 (Internet World Stats, 2014). Thus, information seekers will rely more and more on content available over the Web, and research on Web credibility techniques and solutions will become even more essential.
As stated before, credibility refers to the believability and trustworthiness of a source. In the case of Web credibility, it refers to the credibility of the content available on the Web. Web content takes many forms including text, sounds, videos, and images; however the focus of this paper is on the textual content available on the Web.
Lower cost and increased access to information has enabled users to acquire more content from a number of useful sources including Websites, blogs, e-news, wikis, e-books, e-libraries and e-journals. Before the introduction of the Web and easily-accessible digital documents, the cost of information production was high and its distribution was limited (Flanagin and Metzger, 2008). Hence, the sources were fewer in number, and only people and institutions with authority or funds were able to acquire them. This is not the case in the digital environment as content can be published on the Internet easily by any author without being concerned that authorities will restrict them from doing so (Fritch and Cromwell, 2001, 2002; Johnson and Kaye, 2000; Metzger, Flanagin, Eyal, Lemus, and McCann, 2003a; Rieh, 2002; Rieh and Danielson, 2007).
The Web continues to increase because of the information generated by users collectively and individually, providing collective knowledge which may involve experienced or inexperienced novices (Castillo, Mendoza, and Poblete, 2011; Morris, Counts, Roseway, Hoff, and Schwarz, 2012). This does raise the important question of whether the vast amount of information provided is credible or not credible (Fogg et al., 2001; Nakamura et al., 2007; Tanaka et al., 2010) . It can be very difficult for a person to verify given information without any prior knowledge, and the same is true for computers (Giles, 2005; Miller, 2005). The reason for this is that the structure of the Web does not support semantics (Allemang and Hendler, 2011; Berners-Lee, Hendler, and Lassila, 2001), which poses major challenges when conducting credibility assessment using content analysis (Weare and Lin, 2000).
To understand Web credibility, we have provided three scenarios showing how user experience and understanding is affected by the lack of Web credibility assessment. Table 1 lists these scenarios including the user affected and the consequence faced by them.
| No. | User | Scenario | Consequences |
|---|---|---|---|
| 1. | Ill person | The user is ill and decides to seek medical advice via the Web. The user does not checks the credibility of the Website and follows the diagnosis mentioned. | Following the wrong diagnosis may worsen the condition or require serious medical attention. |
| 2. | Media analyst | The user is searching for news material on iPhone 6S. This user will be required to differentiate between rumours and facts posted on different Websites. | The user may take content from a website which has posted rumours only and has not provided any sources. |
| 3. | Student | The user looking for an answer to the question Who is the richest man in the world? | The results return might be inaccurate and outdated depending upon how regularly the Websites are updated. |
It is evident that the issues relating to information credibility on the Internet are important and it is necessary to evaluate information based on its credibility. The ideal solution to this is to involve information editors or professional gatekeepers in credibility assessment (Flanagin and; Metzger, 2007). However, this solution is not practical since new information is being added at an alarming rate and it would not be possible to evaluate all content or requests submitted. Instead of burdening information editors or professional gatekeepers, therefore, the responsibility should be handed over to the individual information seekers or computers. However, the Internet user is generally unaware of the criteria necessary for judging Web credibility (Amsbary and; Powell, 2003; Meola, 2004; Metzger et al., 2003a) so it is necessary to look into a system that uses various factors for determining the credibility of the information.
Purpose of study
The aim of this article is to examine the research about credibility judgment. This includes looking into articles covering approaches to making Web credibility judgments and the factors identified in these articles. We aim to suggest a hybrid model that can take advantage of various techniques to make Web credibility judgment accurate.
This paper is divided into three major sections: perception of Web credibility by users and the difficulties faced by them; evaluation techniques and approaches for evaluating Web credibility judgment; evaluation of these approaches and explanation of the advantages of using a hybrid model over them. The approaches for evaluating Web credibility judgment are divided into two main components i) evaluation performed by users and ii) evaluation performed by computers. Overall, this review highlights the following aspects:
- problems faced by users when doing Web credibility judgment;
- factors affecting Web credibility judgment that are useful for performing evaluation;
- strategies for addressing problems faced by information seekers and computers in evaluating Web credibility judgment;
- hybrid model for evaluating Web credibility judgment;
- future work in information systems and information retrieval for improving Web credibility judgment.
Perceiving Web credibility and difficulties faced
This section covers the perceptions of users towards Web credibility and the difficulties in making credibility judgments. Since the mid-1990s, checking for information credibility over the Web has become an important topic (Kim and Johnson, 2009; Metzger and Flanagin, 2013) due to the ever increasing volume of information on the Web (Internet World Stats, 2014). The area of information credibility gained importance as people started considering the data available on the Web to be more reliable than other sources. Over the past decades, many studies have been conducted to understand the people’s perception of information credibility in different environments and the problems they faced during credibility assessment (Flanagin and Metzger, 2000, 2003, 2008; Metzger, Flanagin, and Zwarun, 2003b). Flanagin and Metzger (2000) study shows that users are more reliant on Web-based information despite it being false and biased. Around 1,000 people who participated in the study considered Web information to be as credible as that from television, radio and magazines, but less credible than that from newspapers.
Metzger et al. (2003b) conducted a survey analysing college students’ perception and behaviour regarding information credibility on the Web. Around 51% of the students used the Internet daily, 30% used it several times a week, and 15% reported using it once in a week. It should also be noted that college students used books (3.99/5) and the Internet (3.59/5) more often for academic information than journals, newspapers and magazines (the results are given as mean values on a scale of 1 to 5). The study also compared students' and non-students' perception of Web information credibility as compared to other sources. Table 2 shows students who consider content on the Internet (4.09) less credible compared to other sources including newspaper, television and magazines. However, non-students show a different pattern as they consider the Internet to be the most credible after newspapers (4.06). It should be noted that the gap is closest for Internet (.03) compared to other sources even though the ranking order of sources is different in both groups.
Metzger et al. (2003b) also noted that despite the fact that students considered content on the Web to be less credible, they still relied heavily on it for doing homework and assignments. They were also unaware of the mechanisms needed for verifying the credibility of information diligently; with proper training this issue could be resolved.
Freeman and Spyridakis (2009) showed how much impact simple features such as contact information can have on credibility of health information. In the study, 144 participants rated the credibility of Web pages with a link Contact us to be more credible than those which did not not have one (Freeman and Spyridakis, 2009). They also pointed out that contact information can provide a major clue to credibility when source characteristics are not available. Source characteristics refers to a source that a reader trusts., such as health information published or authored by physicians, or major health institutions (Sillence, Briggs, Harris, and Fishwick, 2007).
| Information source | Students(n=436) | Non-students(n=307) |
|---|---|---|
| Newspaper | 4.74 | 4.28 |
| Television | 4.17 | 3.87 |
| Magazine | 4.14 | 3.91 |
| Internet | 4.09 | 4.06 |
| Radio | 4.07 | 3.84 |
Twitter is now being used to distribute substantive content, such as breaking news, because of the success of social networking Websites (Castillo et al., 2011; Morris et al., 2012). With the increase in tweets, users have started considering news through tweets credible instead of going to the source. In addition, there is disparity between the features users consider relevant to credibility assessment and those currently revealed by search engines.
It should also be noted that reader characteristics also affect credibility judgment (Ahmad, Wang, Hercegfi, and Komlodi, 2011; Freeman and Spyridakis, 2009). Robins and Holmes (2008); Robins, Holmes, and Stansbury (2010) show that there is a close relationship between people's visual design preferences and credibility assessment on consumer health information sites. Moreover, a person who has experience in the domain and is looking for Web material related to it will be able to judge credibility better (Flanagin and Metzger, 2000; Metzger, 2007). Experienced Web users also tend to consider it to be more credible than less experienced users (Fallow, 2005; Flanagin and Metzger, 2000).
Thus, it can be concluded that Web credibility has become even more important than it used to be, since many users’ perception of information on the Web is that it is more credible compared to other resources. Additionally, Web users require credibility assessment methods to differentiate between authentic and dubious information. However, users face many difficulties in conducting credibility evaluation without guidance.
Science education research indicates that users face difficulties when judging the credibility of documents as they lack the skills to construct evidence-based explanations that involve collecting facts from different sources when making credibility judgments. This problem can be found at elementary level (Sandoval and Çam, 2011; Wu and Hsieh, 2006), middle school level (Glassner, Weinstock, and Neuman, 2005; Kyza and Edelson, 2005; Mathews, Holden, Jan, and Martin, 2008; Pluta, Buckland, Chinn, Duncan, and Duschl, 2008), high school level (Brem, Russell, and Weems, 2001; Dawson and Venville, 2009; Reiser, 2004; Sandoval and Millwood, 2005), undergraduate level (Halverson, Siegel, and Freyermuth, 2010; Korpan, Bisanz, Bisanz, and Henderson, 1997; Lippman, Amurao, Pellegrino, and Kershaw, 2008; Treise, Walsh-Childers, Weigold, and Friedman, 2003) and even in pre-service teachers’ education (Zembal-Saul, Munford, Crawford, Friedrichsen, and Land, 2002).
Pluta et al. (2008) documented the difficulties faced by participants belonging to the middle school level. The study involved 724 students who found it difficult to make decisions about strength of evidence in evaluating scientific models. This resulted in treating all evidence provided as strong i.e. without any variation. At high school level, Kolsto (2001) conducted interviews with 22 10th grade students regarding their perceptions about the trustworthiness of knowledge claims, arguments, and opinions on different issues. The analysis recorded the resolution strategies through which pupils decided on who and what to trust. Along with these strategies, the study also recorded problems faced by the pupils when trying to explain or defend an issue. These included researchers having different opinion in an issue, research might not have been of satisfactory quality and researchers might have been biased. Moreover, the students showed little interest in the mechanisms and methodological aspects involved in assessing the credibility of the evidence at hand (Kolsto, 2001).
Lippman et al. (2008) conducted an experiment with 98 undergraduate students. The experiment involved students trying to analyse and compare contradictory arguments using supporting evidence for measuring credibility in scientific arguments. The study revealed that the students inconsistently applied the epistemological criteria (investigating the origin and justified belief) for empirical data serving as evidence. This was due to their lack of the deep understanding required to judge the quality of a piece of evidence. This resulted in a lot of variation since the students did not always select the strongest evidence available to them. This was due to students’ preference for ease of comprehension instead of the need for relevant empirical and disconfirming evidence (Lippman et al., 2008).
These studies show that students themselves lack the training or tools for judging and understanding evidence for verifying credibility. These studies did point out the problems faced by the students and suggested techniques for addressing them. Next we will cover the different techniques used for evaluating Web credibility that may be useful in addressing problems faced.
Evaluation techniques for measuring Web credibility
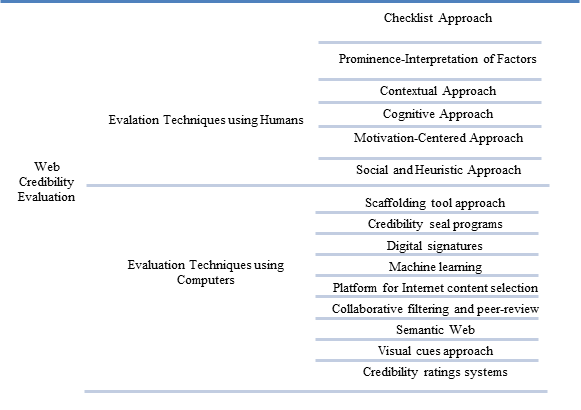
Studies show that users lack training and skill sets in evaluating Web credibility accurately (Flanagin and Metzger, 2000, 2003, 2008; Metzger et al., 2003b) . Researchers have suggested various evaluating techniques for aiding users in making these credibility judgments. There are two general techniques for evaluating credibility of Web content: i) credibility evaluation by users, and ii) credibility evaluation by computers (see Figure 1).
With reference to related literature, it was found that credibility can be measured based on multiple categories. The categories identified in previous papers were used and additional categories were defined for our research. This was done to cater for factors (used in evaluation techniques) that could not be mapped into existing categories. The term factor is defined as ‘something that helps produce or influence a result’ (Merriam-Webster Inc, 2003). In this research, we refer to factor as a quality that is used in an evaluation technique for measuring Web credibility.
The method adopted for reviewing papers is based on the systematic review methodology guidelines of Kitchenham (2004). The requirement set for selecting papers was based on the coverage of Web credibility along with details of factors used for evaluation. The data was recorded in the forms of tables listing different approaches and credibility categories on which the factors were mapped. By going through the different approaches discussed in this section, factors used to evaluate credibility can be identified. Tables 4 to18 list the factors found in these approaches from the year 1996 onward. The factors have been classified using categories like accuracy, authority, aesthetics, professionalism, popularity, currency, impartiality and quality, and are discussed in our earlier research (Shah and Ravana, 2014). These categories are defined in Table 3.
| Category | Explanation |
|---|---|
| Accuracy | Correctness of the information provided by the author. |
| Authority | Experience and popularity of the author. This includes author’s qualifications and credentials in the Web community |
| Aesthetics | Combination of colours, layout, images, videos, fonts, use of bulleted lists, or presentation of tabular data used on the Web page |
| Professionalism | Policies and features available on the Website |
| Popularity | Website’s reputation among Web users and reviewers |
| Currency | Frequency of updates applied to the content |
| Impartiality | Lack of bias in the content |
| Quality | Whether the article has been peer-reviewed or not and other factors contributing towards quality of the content |
Credibility evaluation by users
This section covers the different approaches adopted for evaluating credibility where the end judgments lies either with the user, educator or evaluation expert (Metzger, 2007). It highlights the different approaches and skills required by Internet users to evaluate Web credibility: checklist approach, cognitive approach, prominence-interpretation of factors approach, contextual approach, motivation-centred approach, and social and heuristic approach.
Checklist approach
Initial efforts at solving Web information credibility started out with the objective of promoting digital literacy. The American Library Association and National Institute for Literacy were two of the first groups to take this initiative (Kapoun, 1998; Rosen, 1998; Smith, 1997). Their objectives were aimed at assisting Internet users by providing them with the necessary training to evaluate online information. They found that the skills required for evaluating credibility were similar to the ones used during information evaluation in other channels of communications. The research highlighted five criteria in the development of skills before a user was competent to evaluate credibility of Internet-based information: accuracy, authority, objectivity, currency (newly added or updated), and coverage or scope (Alexander and Tate, 1999; Brandt, 1996; Fritch and Cromwell, 2001) . Out of the five criteria, users only tend to check for two. Studies conducted by Flanagin and Metzger (2000, 2007); Metzger et al. (2003b) show that most Internet users more often assessed a Website’s credibility only on currency, comprehensiveness and objectivity, while verifying author’s identity, qualifications, and contact information were evaluated the least. From these results, it can be said that the users prioritized criteria that were easy to evaluate rather than ones which were time consuming.
Sanchez, Wiley, and Goldman (2006) showed that credibility assessment could be enhanced by providing training to the students. They identified four areas where the students required support: source of information; type of information being presented; how the information fits into an explanation of the phenomena; and evaluating the information with prior knowledge of the subject. Baildon and Damico (2009) also presented a similar model that went through a series of yes-no questions for evaluating credibility.
The checklist approach evaluates the content comprehensively and covers all of the categories falling under credibility. However, the approach demands a lot of time from the user to fully utilize it. The factors identified under checklist approach are listed in Table 4.
| Category | Factors Identified |
|---|---|
| Accuracy |
Ability to verify claims elsewhere (e.g., external links) Citations to scientific data or references Source citations |
| Authority | Author identification Author qualifications and credentials Presence of contact information |
| Aesthetics |
Easy navigation, well-organized site Interactive features (e.g., search capabilities, confirmation messages, quick customer-service responses) Professional, attractive, and consistent page design, including graphics, logos, colour schemes, etc. |
| Professionalism |
Certifications or seals from trusted third parties Absence of advertising Absence of typographical errors and broken links Domain name and URL (suffix) Download speed Multi-language support Notification or presence of editorial review process or board Sponsorship by of external links to reputable organizations Presence of privacy and security policies |
| Popularity |
Past experience with source or organization (reputation) Ranking in search engine output |
| Currency |
Presence of date stamp showing information is current |
| Impartiality |
Message relevance, tailoring Plausibility of arguments |
| Quality |
Comprehensiveness of information provided Paid access to information Professional-quality and clear writing |
Cognitive approach
Fritch and Cromwell (2001, 2002) propose a model for introducing a cognitive authority for assessing Web content information. By definition, cognition is the ‘mental process of knowing, including aspects such as awareness, perception, reasoning, and judgment’(Jonassen and Driscoll, 2003). The model presented is iterative in nature, where information seekers evaluate the credibility and quality at levels of author, document, institution, and affiliations, and this is later integrated for global judgment. The model looks into factors such as verifying the author or institution information, and whether the content is reviewed by peers, and provides evidence for supporting an argument, layout and presentation of the content, regularly updated content and accuracy of the document against other known evidence-based guidelines and theories. Though the factors overlap with the criteria set out for the checklist approach, the mechanism for evaluating differs. The cognitive approach gives importance to technological tools (such as Who is, Traceroute, and NSlookup or Dig) for users for evaluating different criteria (Fritch and Cromwell, 2001, 2002).
Wathen and Burkell (2002) propose an iterative model based on a review of literature in psychology and communication. The model divides credibility evaluation into three stages, each evaluating certain criteria. The first stage deals with the overall impression of the Website by looking at properties like appearance, colours, graphics and layout. The second stage verifies trustworthiness, accuracy and currency of the document. The last stage takes into account factors relating to the user’s cognitive state when evaluating the document. Therefore, the result may differ from user to user, depending on his or her experience of the topic at hand. (Metzger and Flanagin, 2013) highlight the use of cognitive heuristics in credibility judgment. Their findings illustrate the types of cognitive heuristic adopted by users to determine the credibility of the Web content and Web resources.
The cognitive approach introduces cognitive skills of the user for evaluating the content and thus the results produced will differ between different users. This adds a new dimension for evaluating Web credibility but the results may be questionable if we take into account the person assessing the content. Table 5 lists the factors identified under this approach.
| Category | Factors identified |
|---|---|
| Accuracy |
Accuracy of the document against other known evidence-based guidelines and theories Trustworthiness, accuracy User’s cognitive state evaluating the document. |
| Authority | Verifying the author or institution information, |
| Aesthetics |
Layout and presentation of the content, Website’s visual appearance, colours, graphics and layout. |
| Professionalism | None |
| Popularity | None |
| Currency |
Regularly updated content Currency of the document. |
| Impartiality | The content is reviewed by peers and provides evidence for supporting an argument |
| Quality | None |
Prominence-interpretation of factors approach
Though the checklist and cognitive approaches provide criteria for evaluating credibility, conventional Internet users nonetheless set their own criteria for measuring it. It is safe to say that Internet users perceive information differently to researchers and set their own precedence and interpretation for evaluating credibility.
Eysenbach and Köhler (2002) conducted a study to verify this claim. The study involved twenty-one participants who were asked to identify the criteria they thought were important for evaluating credibility. The researchers reported that the criteria which the participants chose gave precedence to the official authority of the source, presence of scientific citations, professional design, ease of use, and multiple language or user’s preferred language support. One interesting observation made by the researchers was that very few participants looked into the authenticity of the source when evaluating the Website.
Dochterman and Stamp (2010) explored how Web users make credibility judgments. They formed three focus groups, which were asked to examine Websites and comment on them. A total of 629 comments were collected about users’ perceptions of Web credibility assessment. The focus groups narrowed down 12 the credibility factors impacting their judgment, including authority, page layout, site motive, URL, crosscheck ability, user motive, content, date, professionalism, site familiarity, process, and personal beliefs.
The Persuasive Technology Lab at Stanford university proposed some key components of Web credibility and presented a general theory called prominence-interpretation theory (Fogg, 2003). The theory was formed after conducting extensive quantitative research on Web credibility in various studies involving more than 6500 participants. It is based on two key components for evaluating information’s credibility, i.e., Prominence (The user notices something) and Interpretation (The user makes a judgment about it).
The approach focuses mainly on the user’s preferred factors and thus the results will vary from user to user. Moreover, some of the categories may totally be ignored by users if they don’t consider the category important. Two users with similar preferences may therefore have different results depending upon their experience with Web credibility assessment. The factors identified under the approach are listed in Table 6.
| Category | Factors identified |
|---|---|
| Accuracy |
Cross checkability Official authority of the source, Presence of scientific citations, Object characteristics including its type (journal vs forum) Citation |
| Authority |
Author details The characteristics of source dealt with details of the author |
| Aesthetics |
Website presentation Page layout Site familiarity Professional design Easy to use Presentation and structure of the document. Website’s motives |
| Professionalism |
URL Site motive Multi-language or user’s preferred language support Type of source (.com, .edu, etc.) Information on the page. |
| Popularity | Website reputation |
| Currency | Content date |
| Impartiality |
User’s experience Involvement of the user Individual differences Topic of the Website Task of the user User’s assumptions Skills and knowledge of the user Evaluation of context when it is being conducted User motive, Personal beliefs |
| Quality | None |
Contextual approach
Though the checklist and other comparable approaches do provide a complete guideline for credibility assessment, they are not practical to use and often require a lot of time to evaluate Websites. Some checklist approaches have over 100 questions per Web page visit, which affects the usability of the approach. Meola (2004) identified the failings of the checklist approach and presented a contextual model to overcome these. Flanagin and Metzger (2000) highlighted the reluctance of users to spend too much time on evaluating the credibility of Web information, while Meola (2004) also challenged the need to perform validation on all Websites when there are professionals managing Websites properly. He distinguished Websites by dividing them into two categories, i.e., free Websites and fee-based Websites.
In contrast with the checklist approach, the model proposed by Meola in 2004 emphasized the shifting of the information externally. Meola stated that information ‘is located within its wider social context, facilitating reasoned judgments of information quality’, thus introducing external information for verifying the information. The model proposed three techniques for achieving this: using peer reviewed and editorially reviewed resources, comparing information with credible resources, and corroborating information from multiple sources. Meola stressed that the contextual approach is more practical and easier to use. Moreover, it takes less time to guide users towards adopting credible resources and to train them than to go through a checklist for every website.
The contextual approach tries to cover the disadvantages found in existing approaches by taking the context of the content into consideration. This saves users’ time on credibility assessment for content that has already been reviewed by experts. Though it does not address all the categories falling under credibility assessment. Table 7 lists the factors found under contextual approach.
| Category | Factors Identified |
|---|---|
| Accuracy | Comparing information with credible resources Corroborating information from multiple sources |
| Authority | None |
| Aesthetics | None |
| Professionalism | None |
| Popularity | None |
| Currency | None |
| Impartiality | Using peer-reviewed and editorial reviewed resources |
| Quality | Using peer-reviewed and editorial reviewed resources |
Motivation-centred approach
While evaluating Web information credibility using humans, Metzger (2007) looked into the benefits and shortfalls of different approaches and suggested a dual processing model that considers both users’ motivation and their ability to evaluate. Besides motivation, users’ experience and knowledge is also catered for in this approach. This is useful for users who are seeking specific or targeted information. The user can also be given the option to adopt the detailed list of factors used in the checklist or contextual approach, if required. Depending upon the severity or importance of credibility assessment, the necessary approach can be adopted. The model is divided into three phases: exposure phase, evaluation phase, and judgment phase. The exposure phase asks the user about his or her motivation and ability to evaluate. Depending upon the option chosen, the process can be taken to the next stage. The evaluation phase offers options to the user for evaluation. These options include no evaluation if the content does not require credibility assessment, heuristic or peripheral evaluation which considers only simple characteristics like design or layout, and systematic or central evaluation for users who want rigorous and accurate credibility assessment. Finally, the judgment can be made in the final phase (Metzger, 2007).
The motivation-centred approach, tries to address the problems in other solutions by following a dual processing model approach. Based on the user’s motivation and experience, the model is adjusted to provide the best evaluation mechanism for that user. This allows the user to get the desired Web credibility assessment without overwhelming an inexperienced user with a lot of factors to check. The categories and the factors taken into consideration by this approach are listed in Table 8.
| Category | Factors Identified |
|---|---|
| Accuracy | Systematic or central evaluation |
| Authority | Systematic or central evaluation |
| Aesthetics | Heuristic or peripheral Evaluation |
| Professionalism | Heuristic or peripheral Evaluation |
| Popularity | Heuristic or peripheral Evaluation |
| Currency | None |
| Impartiality | Check user’s exposure on the basis of his or her motivation and ability to evaluate |
| Quality | None |
Social and heuristic approach
Most researchers assume that, for credibility assessment, users work in isolation and put in a lot of time and effort for effective evaluation (Metzger, Flanagin, and Medders, 2010). However, not all Web users have the time and the skills necessary for conducting an effective evaluation, and have to rely on solutions that involve others for making credibility assessments including using group-based tools.
Metzger et al. (2010) conducted a study to examine 109 participants and their evaluation of Web credibility using the social and heuristic approach. By using social computing, Websites users reach a conclusive decision by getting involved in discussions. Among social factors, the participants focused on social information (good and bad reviews), social confirmation of personal opinion, endorsement by enthusiasts on the topic and resource sharing via interpersonal exchange. Among the cognitive heuristics factors that the participants used were reputation, endorsement, consistency, expectancy violation, and persuasive intent.
Savolainen (2011) analysed 4,739 messages posted to 160 Finnish discussion boards. Factors for the evaluation of quality and the judgment of information credibility were suggested for effective credibility assessment. For evaluation of quality of the message's information content, the most frequently used criteria pertained to the usefulness, correctness, and specificity of information. Credibility assessment included the reputation, expertise, and honesty of the author of the message.
The approach tries to address the Web credibility assessment problem by taking advantage of the social element of the Web and users’ heuristics skills for finding the solution. This is done by suggesting strategies for finding the answer in discussion boards. This allows the user to locate answer suggested by expert users on a given topic. In most cases, the approach points towards solved solutions that are related to a user’s question. This allows the user to use social and heuristics skills for each reaching a credibility answer without taking too much time. Table 9 lists the factors and the credibility categories this approach can be used for evaluating.
| Category | Factors identified |
|---|---|
| Accuracy | Correctness, and Specificity of information. |
| Authority | Expertise of the author Reputation of the author |
| Aesthetics | None |
| Professionalism | None |
| Popularity |
Social factors include social information (good and bad reviews), Social confirmation of personal opinion, Endorsement by enthusiast on the topic and Resource sharing via interpersonal exchange. Cognitive heuristics factors include reputation, Endorsement, Consistency, Expectancy violation, and Persuasive intent. |
| Currency | None |
| Impartiality |
Endorsement by enthusiast on the topic Honesty of the author of the message |
| Quality | For evaluation of message’s quality usefulness |
Credibility evaluation by computers
One of the shortfalls of using humans as evaluators for credibility assessment is that the results vary depending upon users’ perception and interpretation of the information. Moreover, the methods are either too time consuming, require user training or, in some cases, require motivation to perform the task. Therefore, researchers have proposed methods using computers for evaluation or assisting in Web information credibility evaluation.
Metzger (2007) suggested alternative approaches to human evaluation. She emphasized the problems faced when conducting evaluation with humans and the benefits that can be achieved using computers. She suggested various approaches including credibility seal programmes (for assisting users in located trusted Websites), credibility rating systems, directories, databases, or search engines showing credible content only, a platform for Internet content selection labels that establish the credibility of Internet information, digital signatures, collaborative filtering, and peer review (Metzger, 2007). Most of these approaches or their variants are being used today for evaluating Web information credibility along with new approaches. The approaches discussed are: scaffolding tool approach, visual cues approach, credibility seal programmes, credibility ratings systems, digital signatures, platform for Internet content selection, collaborative filtering and peer-review, machine learning, and semantic Web.
Scaffolding tool approach
Scaffolding tools provide helpful features to make the credibility assessment process easier. Some of these systems are in the form of Web-based learning platforms while others assist in fetching credible information off the Web.
STOCHASMOS, a Web-based learning platform, acts as a scaffolding tool for helping students in scientific reasoning (Kyza and Constantinou, 2007). This is done by helping students to construct evidence-based explanations. The platform provides features including omnipresent tools, inquiry environment tools and STOCHASMOS reflective workspace tools.
Nicolaidou, Kyza, Terzian, Hadjichambis, and Kafouris (2011) shared a credibility assessment framework for supporting high school students. This framework helps students to develop skills for assessing credibility of information over the Web. The results gathered from the group discussion showed that the students became aware of the credibility criteria, allowing them to identify sources of low, medium and high credibility. The exercise was done using the STOCHASMOS learning environment. When using the framework for solving socio-scientific problems, the students went through passive prompts to identify and rate credibility from 1 (low) to 5 (high) (Nicolaidou et al., 2011). The framework required students to insert evidence (including its source) to support an argument. Moreover, the evidence had to be rated on criteria related to credibility containing funding, author’s background, type of publication and whether the study included comparison between groups of studies.
This approach guides users to make better credibility judgements by providing an interface using computers. Instead of doing the work manually, the approach helps user do the task more easily by providing a mechanism to find evidence related to content’s credibility. However, it does not provide any credibility assessment on its own. Table 10 lists the factors identified under this approach.
| Category | Factors identified |
|---|---|
| Accuracy | None |
| Authority | None |
| Aesthetics | Includes evidence of low, moderate and high credibility in the learning environment |
| Professionalism | Supports practice of the credibility assessment process through given criteria and self- and technology-regulated iterative reflective discussions Provides teacher mentoring and modelling at critical times Provides opportunities for public discussions of the final decisions |
| Popularity | None |
| Currency | None |
| Impartiality | None |
| Quality | Makes context relevant to students’ lives Provides the context of a socio-scientific dilemma Constrains complex tasks in meaningful ways Supports collaboration and peer review Constructs evidence-based scientific reasoning |
Visual cues approach
Most search engines and Web pages do not show all the relevant information that is necessary for making an accurate credibility assessment. Using visual cues to show the score of different characteristics affecting credibility can greatly help Web users in selecting credible Web resources.
Yamamoto and Tanaka (2011) highlighted the problems of Web search engines. Instead of results lists showing only titles, snippets, and URLs for search results, visualization about the Website’s accuracy, objectivity, authority, currency and coverage may also be presented to enhance the credibility judgment process. Moreover, results are re-ranked by predicting the user’s credibility judgment model through users’ credibility feedback for Web results.
Schwarz and Morris (2011) also presented a similar approach in which they identified different factors that are not available for end users. Moreover, some of the important features, such as popularity among specialized user groups, are currently difficult for end users to assess but do provide useful information regarding credibility. The factors were gathered from search results and the Web page itself. For search results, expert popularity, summary, URL, awards, title, result rank, page rank, overall popularity were selected and for the Web page itself factual correctness, expert popularity, citations, familiarity with site, title, domain type, look and feel, author information, awards, page rank, overall popularity, popularity over time, number of ads and where people are visiting from were selected. The proposed solution presents visualizations designed to augment search results and thus lead to Web pages that most closely match the most promising of these features.
In other research, a semi-automated system was proposed that facilitates the reader in assessing the credibility of information over the Web (Shibuki et al., 2010). The method provides a mediatory summary of the content available on Web documents. A mediatory summary is one where both positive and negative responses are included in the summary in such a way that the user is guided towards the correct conclusion. This is done based on the relevance of a given query, fairness, and density of words. Moreover, the final summary is generated by comparing documents retrieved in both the submitted query and the inverse query.
In contrast to scaffolding tool approach, visual cues approach provides relevant information to users for making better credibility judgements; users do not have to find that information themselves. The relevant information is provided either in terms of scores or information relating to each category. The approach is quite comprehensive and covers all the categories of credibility. Table 11 lists the factors identified under this approach.
| Category | Factors identified |
|---|---|
| Accuracy |
Referential importance of Web page Citations Relevance of a given query, |
| Authority |
Social reputation of Web page Expert popularity Author information Author awards |
| Aesthetics | Familiarity with site |
| Professionalism |
Domain type Awards Title Factual correctness Number of advertisements |
| Popularity |
Social reputation of Web page Resultrank PageRank Overall popularity PageRank Popularity over time Where people are visiting r\from |
| Currency | Freshness and update frequency of Web page |
| Impartiality |
Content typicality of Web page Summary Positive and negative responses of the given query, Fairness |
| Quality |
Content typicality of Web page Coverage of technical topics on Web page Density of words |
Credibility seal programmes
Credibility seal programmes suggest trusted Websites to Internet users by marking a Website with an approval logo. Verification entities such as TRUSTe, BBB, and Guardian e-Commerce verify Websites by looking into sites’ privacy policies (Jensen and Potts, 2004). As many as 77% of the most visited Websites share their privacy policies (Adkinson, Eisenach, and Lenard, 2002).
TRUSTe is dedicated to building a consumer’s trust towards the Internet. By signalling the user, the programme assures the user that the Website is credible. TRUSTe does an initial evaluation of the Website and its policies to verify its consistency with TRUSTe licensee’s requirements. After initial evaluation, a privacy program is placed that continues to monitor the Website and its policies periodically. All initial and periodic reviews are conducted at TRUSTe’s facility by accessing the Website and its policies. If TRUSTe finds a Website not following its stated privacy practices then action will be taken, including complaint resolution, consequences for privacy breach, and privacy education to consumers and business (Benassi, 1999). To prevent unauthorized use of the trademark, TRUSTe provides a “click to verify” seal which links the user to TRUSTe secure server to confirm Website’s participation. Rodrigues, Wright, and Wadhwa (2013) reviewed prior seal programme approaches and suggested an approach that enables these programs to unlock their full potential by the use of more comprehensive privacy certification mechanisms, including data protection certification mechanisms, seals, and marks.
Credibility seal programmes act as filter to allow credible information only. One of the shortfalls of this approach is that information provided to user is often limited. This is because only the Websites marked as credible by seal programmes will be considered for answer extraction and a Website containing the necessary info may be ignored. Moreover, the approach only addresses few of the credibility categories. The factors covered by this approach are listed in Table 12.
| Category | Factors identified |
|---|---|
| Accuracy | None |
| Authority | None |
| Aesthetics | None |
| Professionalism |
Privacy policies Meeting the requirement of the license This includes complaint resolution, Consequences for privacy breach, Privacy education to consumers and business Privacy certification mechanisms including data protection certification mechanisms, seals, and marks |
| Popularity | None |
| Currency | None |
| Impartiality | None |
| Quality | None |
Credibility rating systems
The rise in online social networking Websites and collaborative editing tools has allowed users to share content and approve information because of features such as rating tools, comment boxes, collaborative linking and community-editable content. These tools allow users to give feedback, suggest changes, criticize and, in some cases, edit information. Social navigation tools, recommendation systems, reputation systems, and rating systems are all different types of social feedback systems for Websites serving the same purpose (Dieberger et al., 2000; Metzger, 2005; Rainie, 2004; Resnick and Varian, 1997; Shardanand and Maes, 1995) .
Giudice (2010) conducted a study to determine the impact of audience feedback on Web page credibility. For the study, three practice and eight experimental Web pages containing audience feedback in the form of thumbs-up and thumbs-down were chosen. These pages had four types of rating: good (90% positive, 10% negative), bad (10% positive, 90% negative), neutral (50% positive, 50% negative) or no rating. Moreover, a range of audience feedback, consisting of high (20,000 audience members) and low levels (2,000 audience members), was also used for checking the behaviour of the participants (Giudice, 2010). A total of 183 participants underwent the study. The results showed that the participants considered a page more credible if the Web page had a good rating from its audience. The study also showed that the size of the audience had no major impact on the participants’ decision (Giudice, 2010).
A rater rating system proposed by Pantola et al. (2010) measures the credibility of the content and the author, based on the rating the author has received. For computing the overall credibility of an article, an algorithm goes through several steps including determining a set of raters, getting the set of ratings, computing consolidated ratings, computing credibility rating, computing contributor reputation, and computing rater reputation.
Adler and Alfaro (2007) proposed a content-driven reputation system that calculates the amount of content added to or edited by authors which is preserved by subsequent authors. This allows younger authors and editors to gain a good reputation if the content is considered to be by the original author and penalized if it is the other way round. Tests conducted on Italian and French Wikipedia, having over 691,551 pages, showed that changes performed by low reputation authors resulted in poor quality material (less credible), i.e., a larger than average probability of having poor quality.
Papaioannou, Ranvier, Olteanu, and Aberer (2012) proposed a decentralized social recommender system for credibility assessment. The system takes into account social, content and search-ranking components before passing a final judgment. Wang, Zou, Wei, and Cui (2013) also proposed a trust model of content using a rating supervision model. The model analyses the behaviour and trustworthiness of the network entities using the data dimension, time dimension and application dimension. An artificial neural network is applied on these dimensions to form a trust model for checking data credibility. The RATEWeb framework also provides a mechanism for providing trust in service-oriented environments (Malik and Bouguettaya, 2009). It is based on a collaborative model in which Web services (a software application that supports direct interaction with other software applications using XML messages) share their experience of service providers with other Web services using feedback ratings. These ratings are used to evaluate a service provider’s reputation.
Although the approach looks promising, because ratings help Web users in judging the credibility of content, some programmes do use unfair means to get high ratings to mislead users (Liu, Yu, Miao, and Kot, 2013; Liu, Nielek, Wierzbicki, and Aberer, 2013). A two-stage defence algorithm has been proposed by X. Liu et al. (2013); this defends against attackers that imitate the behaviour of trustworthy experts and gain a high reputation, thus resulting in attacks on credible Web content.
In contrast to credibility seal programmes, credibility rating systems use the ratings provided by experts and users. The process is easy enough to involve all kinds of users for rating a Website’s content. Though useful, it does require the raters to be active so they may be able to rate all new content when it is added. Also if everyone is able to rate content, inexperienced raters may overshadow the ratings submitted by expert raters. However, we found that this approach is able to cover more categories compared to credibility seal programmes. The factors used under this approach are listed in Table 13.
| Category | Factors Identified |
|---|---|
| Accuracy |
Audience feedback in the form of thumbs-up, thumbs-down Ignores rating submitted by unqualified authors |
| Authority |
Determining set of raters, Getting the set of ratings, Computing consolidated ratings, Computing credibility rating, Computing contributor reputation and Computing rater reputation. |
| Aesthetics | None |
| Professionalism | None |
| Popularity |
User ratings for the page. Different content features of Web page Similarities with other online content Ranking in the search result |
| Currency | Updates to the document |
| Impartiality | None |
| Quality | None |
Digital signatures
The digital signature is an electronic way of showing the authenticity of a document. The digital signature gives the reader a reason to trust the document because it has been created by an authentic entity (Asokan, Shoup, and Waidner, 1998; Ford and Baum, 2000).
Digital signatures can also be used as a characteristic for identifying credible and authentic documents. Kundur and Hatzinakos (1999) presented an approach for applying digital watermarking to multimedia documents to authenticate them for court cases, insurance claims, and similar types of situation, and to make them tamper-proof. The technique embeds watermarks so that tampering of the document may be detected when reading in localized spatial and frequency regions. Yang, Campisi, and Kundur (2004) proposed a double watermarking technique for applying digital signatures to cultural heritage images. The same can be applied to electronic text documents as well to verify the author of the content. The Joint Unit for Numbering Algorithm (JUNA) project applies a visible watermark on text, images, multimedia documents instead of using complex methods for embedding them within the electronic file (Hailin and Shenghui, 2012). In combination with cloud computing concepts, the model proves to be more practical, lower in cost, and a safer copyright protection scheme than others. In another technique, researchers propose an anti-copy attack model for digital images by embedding and watermarking the images (Chunxing and Xiaomei, 2011).
Digital signatures provide an easy mechanism to verify the credibility of the document. This proves quite useful when measuring the accuracy and authority of the document. However, its scope is limited and thus not all categories of credibility are covered. Table 14 lists the factors found under digital signatures approach.
| Category | Factors Identified |
|---|---|
| Accuracy | Digital watermarks |
| Authority | Digital watermarks |
| Aesthetics | None |
| Professionalism | Digital watermarks |
| Popularity | None |
| Currency | None |
| Impartiality | None |
| Quality | None |
Platform for Internet content selection
The purpose of this platform is to select and show credible content only (World Wide Web Consortium, 2003). The idea was originally put forward by Resnick and Miller (1996), whereby they emphasized the importance of and need for a platform that filters credible information. This is also useful for selecting content appropriate for certain age groups such as children and teenagers. The system does this by using labels (metadata) associated with Internet content that may contain information relating to privacy, code signing, and so on.
The platform for Internet content selection project has now been superseded by a protocol for Web description resources which is based on Web 3.0 (Archer, Smith, and Perego, 2008). This was done because of the limitations in the existing architecture of the Internet where computers were not able to understand the semantics and relationship between different content and Web pages. However, researchers have been investigating solutions related to this. (Geng, Wang, Wang, Hu, and Shen, 2012) proposed a platform that allowed for credibility quality assessment of cross-language content.
This approach is similar in concept to seal programmes but with the flexibility to look into metadata covering different credibility categories. This provides a fast and easy mechanism for credibility assessment but requires structured data on Websites. Moreover, it is not able to determine categories such as impartiality and quality of the content without the support of semantics and relationships between content. Table 15 lists the factors identified under this approach.
| Category | Factors identified |
|---|---|
| Accuracy | Labels (metadata) associated with Internet content that may contain information relating to its source |
| Authority | Labels (metadata) associated with Internet content that may contain information relating to author details |
| Aesthetics | None |
| Professionalism | Labels (metadata) associated with Internet content that may contain information relating to privacy, code signing, etc. |
| Popularity | None |
| Currency | None |
| Impartiality | None |
| Quality | None |
Collaborative filtering and peer review
Peer review and collaborative filtering approaches are among the most trusted approaches because experts rate the content. Loll and Pinkwart (2009) suggested a technique using the benefits of this approach. They suggested the model should be used for eLearning application to promote credible content to learners.
PeerGrader was one of the first systems for helping students in peer evaluation (Gehringer, 2000, 2001). The system allowed students to submit their work to be reviewed blindly by other students. This enabled students to gain experience in grading and improving the quality of their work. Although the solution was useful, it depended upon the reviewer’s active and quick response to articles and assignments. Another Web-based collaborative filtering system, Scaffolded Writing and Rewriting in the Discipline (SWoRD) system, Cho and Schunn (2007); Cho, Schunn, and Wilson (2006) addressed this problem by allowing multiple students or teachers to review an assignment. Todd and Hudson (2011) conducted an experiment on 25 undergraduate students taking a public relations course in which he introduced peer graded evaluation and monitored improvements in students’ writing skills. Students showed a positive feedback with scores ranging from 4.8 to 5.6 on a seven-point scale.
Peer review also plays a major role in judging the quality and credibility of articles submitted to conferences and journals. The process involves multiple reviewers assessing an article for plagiarism, quality and credibility (Parsons, Duerr, and Minster, 2010). Peer review also enhances the credibility of the data published, and the author of a peer-reviewed paper receives greater recognition than the author of a report.
Peer review can also be used for reviewing Websites or content and rating them. This is also known as collaborative filtering. Just like the credibility rating systems, Websites are evaluated by people but in this case they are experts in the area and their recommendations are considered highly authentic (Su and Khoshgoftaar, 2009). The collaborative filtering technique may also adopt memory-based ratings (set by a panel) which gives a predicted value-based on data, or hybrid recommenders (Su and Khoshgoftaar, 2009).
The approach is dependent on the activity of experts reviewing content. For it to be successful it is necessary for newly added content to be reviewed in a timely fashion. Other than that, the content peer-reviewed is considered highly credible over others. Moreover, the approach is comprehensive enough covering nearly all of the credibility categories. The categories and factors covered by the approach are listed in Table 16.
| Category | Factors identified |
|---|---|
| Accuracy | Content reviewed by an editorial board |
| Authority | Author’s prior contributions |
| Aesthetics | None |
| Professionalism | Editorial board members listed |
| Popularity | Ranking of journal or proceeding |
| Currency | Content reviewed by an editorial board |
| Impartiality | Editorial boards |
| Quality |
Reviewer’s experience Content reviewed by an editorial board Ranking of journal or proceeding Selection of journals and conference papers meeting the requirements |
Machine learning approach
This approach focuses on learning the contents of the Web document or resource in order to come up with a reasonable assessment. However, it is vital to identify the different features the algorithm should be looking into to ensure accurate measurement.
Olteanu, Peshterliev, Liu, and Aberer (2013) proposed an algorithm that looks into content and social features for addressing traditional Websites as well as social networking Websites like Facebook and Twitter. The algorithm maps the result on a 5-point Likert scale using supervised algorithms. A test conducted on datasets showed 70% or more precision and recall as well as improving the absolute error (MAE) by 53% in regression.
The approach works best with a structured data Website but is not dependent on it. If designed properly, a good machine learning algorithm will be able to cover all the credibility categories. However, this requires training and may lead to unexpected results at times. Moreover, the solution is not cost-effective and companies providing such solutions may ask users to pay a small fee in order to use its credibility assessment features. The factors covered by machine learning approach are listed in Table 17.
| Category | Factors identified |
|---|---|
| Accuracy |
Metadata features Link structure |
| Authority | Author details under metadata |
| Aesthetics |
Appearance Web page structure |
| Professionalism | Content features including text-based features |
| Popularity | Social features including online popularity of the Web page, |
| Currency | Metadata features |
| Impartiality | Reviews by experts |
| Quality | Reviews by experts |
Semantic Web
Semantic Web simply means giving meaning to the Web (Berners-Lee et al., 2001). It focuses on the inclusion of semantic content to enable computers to understand the content available on the Web compared to unstructured and semi-structured documents in a Web of data (Kanellopoulos andamp; Kotsiantis, 2007). It uses resource description framework (RDF) documents for storing metadata and uses Web ontology language for defining ontologies. With machines able to understand the content available on the Web, judging the credibility of content will become much easier.
One of the main platforms using the semantic Web is the protocol for Web description resources, which is the W3C recommended method for describing Web resources and documents. Using a protocol for Web description resources, one can access the metadata related to Web documents using resource description framework documents, Web ontology language, and a hypertext transfer protocol. This allows Web users to select and make decisions on Web resources of interest. Moreover, the credibility of the content can also be verified using semantic reasoners (Archer et al., 2008). The HETWIN model uses semantic technologies for evaluating the credibility and trustworthiness of Web data (Pattanaphanchai, O'Hara, and Hall, 2012).
The Semantic Web is the future of the Web and can be regarded as Web 3.0. The inclusion of semantics allows Web reasoners to do content analysis with ease and cover credibility categories not covered by other approaches. However, since not all content over the Web is structured (i.e. being able to be processed by semantic Web reasoners), some important content may be overlooked. Though ideal, it does require Websites to maintain structured data. The factors identified under semantic Web approach are listed in Table 18.
| Category | Factors identified |
|---|---|
| Accuracy |
Metadata related to Web documents using RDF, OWL and HTTP protocols Content analysis OWL expression Rules Metadata about accuracy and relevance of documents to evaluating credibility |
| Authority | The meta data relating to author |
| Aesthetics | None |
| Professionalism | Metadata relating to privacy policies |
| Popularity | None |
| Currency | Metadata relating updates to document |
| Impartiality | Content analysis |
| Quality | Content analysis |
Discussion
This section discusses the findings presented in earlier sections of the article. It also covers the problems found in the existing approaches which affect the accuracy and effectiveness of Web credibility judgment. A hybrid model is proposed with reasons why this is essential for improving accuracy in Web credibility judgment.
Issues in the existing approaches
Although researchers have come up with solutions to measure Web credibility, these solutions can still not be applied to all domains (including blogs, social networking Websites, medical and health queries, academic and research areas) and Web resources (HTML, XML, images, videos, etc). The criteria used for evaluating the credibility of one particular Web resource may not be useful for evaluating another. For example, when comparing a journal article with a blog entry, the number of criteria required to authenticate the credibility of the journal is quite low compared to the blog.
Models for assessment using humans are perhaps the easiest to implement, as the evaluator only needs to be aware of the criteria for evaluating a document or Website. However, studies have shown that it is impractical and time-consuming to check each and every criterion when evaluating the credibility of a Web page (Meola, 2004). Moreover, the assessment is also affected by the evaluator’s experience and motivation (Metzger, 2007)[Author query: Remove Miriam J]. To address these issues, users should be trained or should perhaps let experienced users do the evaluation for them. The alternative solution is computer evaluation, which does seem more practical in assisting users regarding credibility of a page. However, any one solution can only be applied to a limited number of Web pages and resources. For instance, semantic Web solutions perhaps provide the best possible solution for judging the credibility of an electronic document but this is only possible if the Web document is written using Web ontology language and metadata is stored in ontologies. Similarly, credibility ratings, peer review, and digital signatures might only be available for a handful of documents. This poses a major problem for some of the newer Web systems available such as social networking services (SNS), blogs, forums, Wikis and computer-supported collaborative learning (CSCL) environments, as they are not rated immediately. With few solutions for measuring credibility of content available on these systems, Web users are handicapped.
Limited solutions for new Web systems
Although much work has been done in measuring the credibility of traditional Websites and Web resources, there are few effective solutions in use for measuring the credibility of newer Web systems. Since these systems are among the systems that draw most of the Internet traffic, there is a dire need for an effective credibility assessment method. Although some of the solutions are available for selected platforms, there are no hybrid models for addressing both prior and existing systems. The process involves looking into different factors that may help in measuring the credibility of such systems such as tags, number of likes and shares, reference to the original content, author’s identity, and popularity of the Web page.
Need for a hybrid model
To address the issues found in existing approaches, our solution is to come up with a hybrid model that is able to evaluate the credibility of both traditional and newer Web systems. This can only be achieved by understanding the traditional Web systems and Web resources and using the factors common to traditional and newer systems. The hybrid model must have criteria that are able to address any type of Web resource that needs to be measured. Moreover, it should also be able to take context into consideration, and thus be able to prioritize criteria depending upon the type of content that is being evaluated. Lastly, it should be able to understand the relationship between criteria. For example, the number of citations of a document should have a positive effect on the author’s credibility.
For effective Web credibility judgment, the model cannot be limited to one approach only. This is the reason why both human and computer assessors need to be involved in the model. Although computers can handle information extraction effectively, they cannot judge the preference or experience of the Web users at hand. Figure 2 shows the proposed hybrid model for making Web credibility judgment.
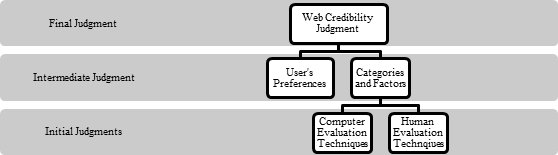
The initial judgment comprises the different computer and human techniques selected for the measuring process. The selection of techniques is also dependent on the categories and factors for measuring these categories. It is not important that all the categories are included in the final assessment. The selection process could involve a group of educators or experts designing the model. The user’s preference can also be included if necessary. This allows assigning of weightings to different categories, which can have a major impact on the final credibility score. Lastly, the final Web credibility judgment score is presented to the Web user to allow him or her to make the best judgment call. The user interface designed for displaying the score may be in the form of a graph, numerical data or a summary depending on the researcher’s preference.
Identification of factors
To allow researchers to start working towards a hybrid model, it is important to identify the factors used in measuring credibility, which is what this research has aimed to do. This is similar to Olteanu’s model, where he stresses the identification of factors to address the problem of assessing Web credibility correctly (Olteanu et al., 2013). In this article, Tables 4 to 9 list the factors for evaluation by humans and Tables 10 to 18 list the factors for evaluation by computers that either are used in measuring credibility or have an impact on the perceptions of the users evaluating the content. These factors can be used in the hybrid model to measure credibility effectively. Moreover, this will also allow researchers to get results that are more accurate by catering for all the possible factors that affect the credibility of that particular resource. Researchers can use this data in forming the algorithms that use the factors listed in the tables.
Conclusion
With the growth of the Web, it is important to have effective ways of assessing credibility for existing and future Web systems. For this, we looked into the perceptions of users and the problems faced by them. We also looked into Web credibility techniques and the approaches proposed by researchers over the years. Evaluation techniques using humans are easy to implement but require users to be motivated and well-trained to achieve the best results. Even when this is the case, checking every detail is time-consuming, making it impractical for everyday Web use. Evaluation techniques using the computer provide faster judgment but a single technique may only be applicable to a handful of Web resource types causing inaccurate results for others. Our findings show that there is a dire need for a hybrid model for evaluation that will not only be useful for traditional Web systems but will also be able to address problems faced in measuring the credibility of newer Web systems. This paper identifies the factors (and categories they belong to) used for evaluation according to different techniques . The research was limited to finding effective solutions that address the main types of Web resources and new systems. Although we were able to find solutions that address systems individually they do not target multiple Web resources. For the future, we wish to expand our hybrid approach to suggesting formulae for computing different categories important for Web credibility judgment while also making sure that it is limited to a few systems only. In addition, the formulae need to be tested against existing solutions to judge their effectiveness and practicality.
Acknowledgements
The preparation of this manuscript has been supported by University of Malaya Flagship Grant (FL001-2012) and University of Malaya Research Grant UMRG (RP028E-14AET).
About the authors
Asad Ali Shah is currently a PhD student under the supervision of Dr. Sri Devi Ravana at the Faculty of Computer Science and Information Technology at University of Malaya. He did his Masters in Advanced Computer Science from University of Manchester, United Kingdom. His research interests lies in the area of the semantic Web and information retreival. Before starting his PhD, he was teaching at the National University of Sciences and Technology, Pakistan as a lecturer for over four years. He can be contact at asad.safdar@hotmail.com.
Sri Devi Ravana received her Bachelor of Information Technology from the National University of Malaysia in 2000, followed by the Master of Software Engineering from University of Malaya, Malaysia and PhD degree from the Department of Computer Science and Software Engineering, The University of Melbourne, Australia, in 2001 and 2012, respectively. Her research interests include information retrieval heuristics, text indexing and information technology in Education. She received a couple of best paper awards in international conferences within the area of information retrieval. She is currently a Senior Lecturer at the Department of Information Systems, University of Malaya, Malaysia. She is also the recipient of her University’s Excellent Service Award in 2006 and 2013. She can be contacted at sdevi@um.edu.my.
Suraya Binti Hamid is currently a senior lecturer at the Department of Information System of the Faculty of Computer Science and Information Technology at University of Malaya (UM), in Kuala Lumpur, Malaysia. She received her PhD in Computer Science from University of Melbourne, Australia. Her research interests are in information Services and e-Learning, social media and Web tdechnology. She can be contacted at suraya_hamid@um.edu.my.
Maizatul Akmar Binti Ismail is currently a senior lecturer at the Department of Information System of the Faculty of Computer Science and Information Technology at University of Malaya (UM), in Kuala Lumpur, Malaysia. She received her PhD in Computer Science from the University of Malaya. Her research interests are the semantic Web in education and recommender systems. She can be contacted at maizatul@um.edu.my.