vol. 13 no. 3, September, 2008
vol. 13 no. 3, September, 2008 | ||||
This work is the first part of a broader set of studies where our intention is to model the information practices related to the research process of molecular medicine. The meta-theoretical frame for our research is Ingwersen and Järvelin's model of interactive information seeking ( Ingwersen and Järvelin 2005; Järvelin and Ingwersen 2004). We share the view of the authors of the meta-theory about the importance of context, task context and information systems context in information retrieval and search research. We also realize that the interaction between numerous factors in the context is very complicated and should be better understood. This knowledge is a prerequisite for the development of systems and tools which benefit users, which could be one of the final, practical aspirations of research in information studies.
Molecular medicine is seen as consisting of several different areas/domains like genetics, biochemistry, bioinformatics etc. and studies on human diseases on the molecular level. In this paper, we concentrate on the description and analysis of the information environment of molecular medicine. There are two reasons for choosing this approach instead of devoting this paper, for example, to information behaviour or information practices. Firstly, we have found it necessary for increasing our understanding of the domain. Our findings will serve as working knowledge for the forthcoming research which will focus more on tasks and context related to the information practices in this domain. As Ingwersen and Järvelin (2005) urge information practices and activities should not be studied in isolation but in context. We have chosen molecular medicine as a study object because this scientific field seems to have an exceptionally rich and varied context. We believe that the effects of context to the developed information practices are not well understood in information science or information retrieval. Secondly, it is well known that molecular medicine as a discipline is developing rapidly and that the growth of information as well as tools for handling and analyzing it are developing at increasing speed. Even though we do not know how different factors in the context of the research process interact, we assume that the environment is closely related to the research work and the information practices developed by the researchers, and some characteristics of it might affect the development of the whole domain. Because of this, the information environment in molecular medicine deserves special attention.
The term information environment has often been used without precise description. For example, Srinivasan and Pyati (2007) used the term to express the context in which information research must be situated. We want to pose the difference between information environment and information use environment. By information use environment, Taylor (1991) means elements related to users and the uses of information, and the framework within which the information is used. In the present study we define information environment as the entirety of information resources, consisting of various information objects, like data in databases, published documents etc., and the tools and services that are needed to retrieve, manage and analyse them. We have chosen to use this term because it is sufficiently broad and holistic in its nature. By using it, the variety of resources and tools as well as their relations can be taken into consideration.
In research work, the research process can be described as a set of work tasks forming the means to achieve the research goals. Information related activities form work tasks, which are the focus of this study. Information activities refer to the implemented actions used to interact with the information environment (Järvelin and Ingwersen 2004). The work task components and activities related to the handling of information form the information practices of the research field. Information activities are not necessarily easy to perceive or study because of their informal or implicit nature (Barry 1995). Information activities include the following three types of activities: information seeking, handling of produced data, and handling of research output.
In this study we have presumed that there is interdependence between the information environment, the research process and the related work tasks (see Ingwersen and Järvelin 2005: 313-356; compare also to Bartlett and Toms 2005). We need a better understanding of the relationships and interaction to be able to develop new information systems for effective access and use of various information resources.
The aim of the present study is to describe and analyse the information environment in the context of research work in molecular medicine. The study object consisted of two research units in molecular medicine and the empirical data were collected from the documentation of the units and the researchers working in them. We focused on three problem areas. Firstly, the characteristics of the research work and resources used in current work tasks, also looking at the researchers' experience in research, background disciplines and the current research groups. Secondly, categorizing information resources by their type and main purpose of use. Thirdly, describing the difficulties and hurdles that the users reported when using information resources.
The research questions related to these problem areas were:
This study was performed as a qualitative case study in order to get a deeper understanding about the research process and the information resources used. We chose two applicable, high quality research units from Finland as research objects. Even though we were aware that the size of these units is smaller compared to the largest international centres, we knew that they were performing well and had a high impact in the research community. This was verified by measuring the number of citations that some recent articles of the researchers received. This paper presents findings from an online questionnaire and semi-structured interviews, thus providing both a broad overview and deeper insight for the analysis.
The data collected from the surveys from the two units were merged and the results and the analysis cover the whole data set. The follow-up interviews were used for gathering information about the use, integration and problems with the information resources.
The outline of the paper is as follows: firstly, definitions of central concepts and background information on related research and the research units that are the focus of the study are presented. Secondly, the methods are described and the results reported. The paper ends with discussion and conclusions.
Related studies can be classified into the following categories. First, the large category of studies on the general usage of information resources (Curtis et al. 1997; De Groote and Dorsch 2003; Knowlton 2007; Tenopir et al. 2004). These studies, mainly based on survey data, concentrate on user behaviour towards the change process from print to electronic for scientific journals or to the impact of new information technologies. Secondly, studies that analyse the high level tasks of molecular biology or classifying of bioinformatics tasks, where the aim is planning better query systems and other tools (e.g., MacMullen and Denn 2005; Stevens et al. 2001; Tran et al. 2004). Thirdly, user studies on bioinformatics. As Geer notices, there are few studies about bioinformatics user groups and their special information needs (Geer 2006). We were not able to find much literature about the information environment of molecular medicine as a whole. There are two papers that describe information-oriented tasks in molecular biology and bioinformatics and consider the research processes of these disciplines from the point of view of information science (Bartlett and Toms 2005; MacMullen and Denn 2005).
According to the study by Grefsheim et al. (1991) from the late 1980s, there were three major sources of information among the biotechnologists, namely their own experiments, personal communication with other scientists, and print or electronic textual material. Personal communication was mentioned as the most important source for timely information in this as well as many other earlier studies (see also Bartlett and Toms 2005). Already in the late 1980s, 60% of the respondents in Grefsheim's study mentioned special databanks as a very useful source of information. Almost ten years later in a study by Yarfirz and Ketchell (2000), the share had risen to 83%. Brown (2003) analysed the use and acceptance of genome and proteomic databases from the perspective of scientific discourse at the beginning of this decade. In her study, 93% of the respondents were accessing such databases at least once a month. She noticed that the databases played an integral role in the daily activities as well as in scientific communication among molecular biologists.
Bartlett and Toms (2005) took another perspective to the use of information in bioinformatics. They combined information behaviour research and task analysis in bioinformatics by taking one specific task, the functional analysis of a gene, as their focus and they succeeded in modelling its protocol. The choice of the task was based on a recommendation made by one bioinformatics expert.
Geer (2006) had the practical goal of establishing the educational and supportive programmes for researchers in mind when she described different user classes according to their apparent skills and information needs. She pointed out that the effective use of the available bioinformatics resources is obstructed by being unaware of the resources and the lack of skills to use them. She divided the users of bioinformatics resources according to their awareness of resources, skills in searching and the critical analysis of data. Besides noticing the difference between academic degrees she also pointed to people who have some special work tasks, namely researchers working mainly in laboratories and those with scientific computing tasks (computational biologists) (Geer 2006).
Bioinformatics resources are an essential part of the scientific discourse and the work processes of researchers in molecular biology and related fields. As Bartlett and Toms (2005) argue, knowing this is not enough. To be able, for example, to develop intelligent systems to facilitate access to the resources, there is a need to have a more detailed picture of a) the high goals of the domain, work processes and tasks aimed at achieving them, b) the needs and skills of different user groups, and c) the information environment as an entity. In this study, our starting point is the information environment. We will also give some attention to the different user groups, proposing that it will give a good background to the forthcoming research.
Molecular medicine, mainly understood as one sub-discipline of biomedicine, is composed of biomedical and molecular biological research. Molecular biology again is a combination of biochemistry, cell biology, genetics and virology. Molecular medicine is an interdisciplinary, practice-oriented and applied science, which utilizes molecular and genetic techniques in the study of biological processes and mechanisms of diseases. Its final, practical task is to provide new and more efficient approaches to the diagnosis, prevention, and treatment of a wide spectrum of congenital and acquired disorders (Goossens 1999; MacMullen and Denn 2005; Miettinen et al. 2006). More information on the basic concepts can be found at the 2Can Web resource or in the resources of the National Center for Biotechnology Information.
The discipline of molecular medicine is evolving and growing exponentially. Research is often highly competitive and teams worldwide are working on similar projects (Wellcome Trust 2003). Growth has been explained by many simultaneous factors, like the substantial increase in government support, the continued development of the biotechnology industry, and the increasing adoption of molecular-based medicine (Buetow 2005). Together with this development and the overall technological development, especially Web-technology, the amount of data, databases, documents and different analysis and management tools have increased enormously.
The situation of the GenBank, a comprehensive public database of nucleotide sequences and supporting bibliographic and biological annotation, is a good example on the growth rate of data. This database doubles in size about every eighteen months. At the beginning of 2007, it contained over sixty-five billion nucleotide bases from more than sixty-one million individual sequences (Benton 1996).
It is characteristic of most of the research databases that they are cooperatively updated and globally shared. The types of data in the databases are diverse and change constantly. There also exist needs to integrate different kinds of data, e.g., to move between the biological and chemical processes, organelle, cell, organ, organ system, disease specific, individual, family, community and population (Buetow 2005). As Butler notices, some software already exists that allows data from different sources to be combined seamlessly. For example, a researcher can retrieve a gene sequence from the GenBank database, its homologues using the BLAST alignment service, and the resulting protein structures from the Swiss-Model site in one step (Butler 2006).
One actively maintained directory of bioinformatics links describes well the growing number of different tools needed for data retrieval, analysis and management. It lists almost 1200 Web resources, servers and other useful tools, databases and resources for bioinformatics and molecular biology research in 2007 (Fox et al. 2007).
The most important bibliographic reference database in biomedicine, PubMed, indexed about 5,200 journal titles in 2007 and consisted of seventeen million references. The growth rate of the database is about 12,000 references every week, which means over 600,000 new references annually. The majority of the indexed titles are available online and the references include a link to the full text. The number of online journals in science, technology and medicine in general is estimated to be over 93% of all titles (Ware 2006).
It could be concluded that some of the most typical features of the information environment in molecular medicine are: a large, and constantly growing, volume of data and published online material; diversity of data types; and a great number of retrieval, analysis and other tools. The environment is interdisciplinary, globally shared (open) and updated, and there is disintegration between databases, published material and tools. This information environment comprises a fertile ground for research work and for the creation of new knowledge and inventions. However, the great variety and the lack of integration is an increasing challenge to the development.
In line with the previous literature, it might be expected that in this study also the number of named resources will be large and the respondents might experience problems in relation to the variety of the resources and tools.
For our study, two Finnish research units were selected from high quality international Finnish research organizations in the field of molecular medicine. The researchers from these two Finnish research units were selected as participants.
Research Unit A consisted of ten research groups with ninety-one researchers. Among them there were fifty-seven PhD students, five undergraduate students and twenty-nine group leaders and other senior researchers. The unit declares that it produces top-level research into the molecular background of cardiovascular, immunological and neuropsychiatric diseases. Some of the research groups were concentrating on the genetic background of common diseases (complex diseases, for example, coronary heart disease), some mainly on molecular genetics of monogenic diseases, like the Meckel Syndrome. There was also one bioinformatics group and one which specialized mainly in systems biology, one in quantitative genetics and two groups focused mainly on the cell and molecular biology of specific diseases.
The second research unit, Unit B, harboured fourteen research groups with 103 researchers, fifty of whom were doctoral students, thirty-nine senior researchers and fourteen group leaders. The research programmes of the groups cover molecular genetics of human diseases, and molecular mechanisms of immune responses and disorders. The genetic programs focus on cytoskeletal and genetic aberrations in the pathogenesis of cancer, and on the role of mitochondrial mutations in human disorders. The topics of the immunology programmes include the basis of the autoimmune disorders APECED and cliac diseases, as well as HIV-1 pathogenicity factor Nef, and cytokine- and antigen-induced transcriptional regulation. There was also a bioinformatics group concentrating on the structural basis of inherited human immunodeficiency syndromes.
In this study mixed methods were used. Empirical data were gathered using two surveys and six semi-structured thematic interviews. The survey data were collected during winter (Unit A) and summer (Unit B) 2007 and the interviews were conducted during summer and autumn 2007.
The surveys were conducted to find out the components of the evolving information environment in molecular medicine. The interviews aimed at understanding more deeply how the researchers interacted in the information environment, i.e., how they used the services available, and why they used them. Observation and thinking aloud, when the interviewees were asked to demonstrate their information seeking procedure using their most recently accomplished seeking incident, were used. The case study was based on the interviews and is an interpretation of how a research case could look in a molecular medicine research unit.
Two Web questionnaires were distributed to the researchers at the two units. The purpose of the surveys was to get an extensive view of the information environment of the researchers in their current research projects and current work tasks. We intended to get at least a rough overview of the research process and an idea about the relationship between work tasks and different information objects connected to them.
At the beginning of the questionnaire we collected some background information about the researcher, concerning their main discipline, current research subjects, duration of their research work, and about their research group and supervisor (if applicable).
The categories of current work tasks were based on the common knowledge about the general stages of the research process (e.g., Blaxter 2001) and on some information sources where stages of experimental research were described more precisely (e.g., Denn and MacMullen 2002, Hyvä 2002). One senior scientist in Unit A was also consulted. Work tasks were asked about at a general level to find out what kind of tasks they were occupied with and whether they performed any information or data retrieval within their current tasks. For the type of current work tasks, there were nine alternatives. Researchers were also able to add new tasks if none of the given matched.
The information environment was explored through questions on the information resources and preferred information channels used in current research projects. The researchers were asked what services they used to search for literature, as well as which collections of bioinformatics data they were using. There were many open questions and the respondents were advised to describe the resources they were using whilst performing their work tasks. The researchers were also asked to comment on their future publication plans.
The questionnaires directed to Units A and B contained minor differences. At Unit A, the respondents were asked to choose one of the named channels as the most important source of information. At Unit B, the researchers were asked about the problems and hurdles they were facing while seeking information. However, as the research domains and the components of the information environments match, and the researchers have similar education, we believe that the results can be generalized to pertain to both research units.
At Unit A, the group leaders were informed about the survey in one of their normal weekly meetings and after that an email containing the link to the Web-questionnaire was sent to all researchers at the unit. One general reminder was sent via email to all and after that non-respondents were invited to participate via a personal email. 63 researchers responded at Unit A, which gave a response rate of 69.2%. 41 (65%) were students and 22 (35%) were senior researchers, post-doctoral researchers and group leaders. Altogether 66.1% of the juniors and 75.9% of the seniors responded.
At Unit B, a motivation letter was sent by email. The purpose of the study was explained in the letter and the researchers were asked to fill in the Web-questionnaire. There were problems getting the researchers motivated, so three reminder letters were sent. Researchers of the larger research groups, who had not responded, were sent a personal email. There were total of 53 respondents and the response rate was 51.5% at this unit. There were 25 junior researchers (doctoral students) (47%) and 28 senior researchers (53%). In Unit B, the response rates were 50% (juniors) and 52.8% (seniors).
From both units together, there were a total of 116 responses. The combined response rate was 59.8%. There were 66 (56.9%) junior researchers and 50 (43.1%) senior researchers. The corresponding response rates were 58.9 % of the students and 61% of the senior researchers.
The information collected by the surveys does not allow the elicitation of the motives and the ways the researchers use the services in their information environment. Hence, six researchers were interviewed to collect information, which is presented in the analysis of results and in the narrative case descriptions in the results section.
The interviews were designed to gather information about how the data and information resources were actually used. The case interviews made it possible to describe and analyse the value of the services from the users' point of view. The data also allowed the capturing of events which occurred during the research work and which might influence a researcher's ability to go forward in the process.
There were six complementary case interviews. Firstly, the interviews were conducted to elucidate the use of the tools for information/literature and data retrieval. Secondly, the aim was to obtain a picture of the process or the task which they were actually doing in their research projects when searching, using or analysing information or data. Thirdly, researchers at different phases of their career were included to be able to acquire a comprehensive view of the research process.
The interviews were semi-structured. Each interview began with a question where the respondent was asked to recall a recent critical incident and to demonstrate it. The interviewees were then asked to describe their typical routines accessing bioinformatics databases and searching relevant literature. Six researchers were interviewed, four from Unit A and two from Unit B. The cases were selected to represent different research areas within molecular medicine, different phases of the research projects and researchers in different stages of their research career. Because of this, two doctoral students and their supervisors were interviewed at Unit A. During the interviews, the researchers were also asked to describe and to demonstrate their most recently accomplished data retrieval process and literature retrieval process. The interviews lasted on average forty-five minutes.
The interviewees belonged to three broad sub-disciplinary classes and they were at different stages in their career: bioinformatics (one PhD student), molecular and cellular biology (one PhD student and one group leader) and genetics (two doctoral students and one group leader).
The survey data from the two study units were merged before the analysis. The respondents were divided into groups by their background discipline, research career (junior and senior) and current research subject. The information resources and current work tasks were categorized. The aim was to make the actual information environment visible and articulated in these two research units.
The cases were analysed based on emergent themes and the themes were compared to the research questions. The case descriptions were written to explain why and how the services were used to acquire literature and bioinformatics data, and to find typical features of the interaction with the information environment. Similar features of the cases were explored. The detailed cases reveal the sequence of events of interactions within the information environment. Why and how they are using the systems or tools is explained.
Current work tasks were asked about at a general level. As the tasks may be overlapping, and the researchers were able to choose among several tasks, the total task percentage was over 100%. We nevertheless obtain a frequency distribution of tasks. The current work tasks of junior and senior researchers are illustrated in Figure 1.
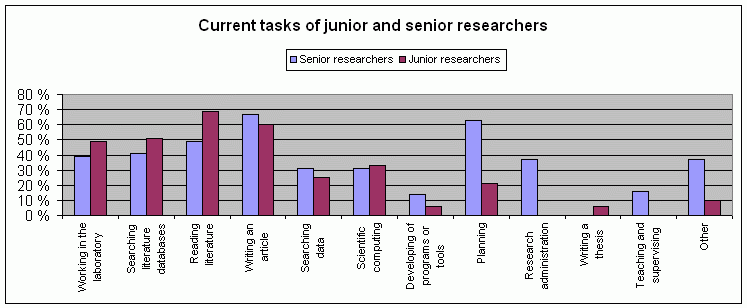
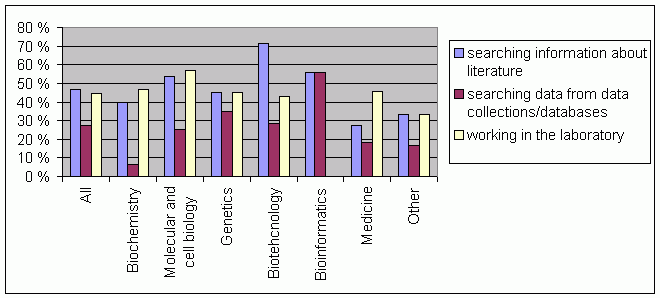
According to the responses to the questionnaire, the junior researchers were at the moment of the survey mostly writing articles, retrieving and reading literature and working in the laboratory. 50% of the senior researchers were also reading and an even larger part, almost 70%, were occupied with writing articles. The seniors were also, more than the juniors, doing planning work and research administration or other administrative duties. The senior researchers were retrieving bioinformatics data more often than the juniors. When asked about the information activities on which this study focuses the results showed that literature retrieval was a more common task than the retrieval of bioinformatics data. These information retrieval tasks and the laboratory work task are shown by discipline in Figure 2. An average of 46.6% of all researchers were retrieving information on literature and 27.6% were retrieving bioinformatics data. There were differences between the disciplines: in medicine and biochemistry the data were produced in laboratories, not retrieved from databases to the same extent as in bioinformatics, genetics or biotechnology. In bioinformatics, there were no laboratory work tasks at all. A considerably large share of their tasks consisted of information retrieval tasks, both of literature and of bioinformatics data.
The researchers from Unit A were asked to choose which channel they prefer as the first source of information in their current project. In all, 68% of the respondents named the Internet or intranet as their first source of information, while 27% preferred contacting colleagues. The more experienced the researchers were, the higher was the proportion preferring the Internet or intranet. Personal contacts were named as the first source of information by 37,5% of graduate students and 23% of senior researchers.
When the researchers were asked about the literature search services they use, most of them used PubMed, which was mentioned by 99% of the researchers. Google (19%) was used quite often; Web of Science (15%), Google Scholar (14%), and the Finnish University Libraries' search portal Nelli (10%) were also used. The Nelli portal was available at Unit B and to a small portion of the researchers at Unit A. When asked about which kind of published material the respondents had used, all of them named scientific articles and 39% mentioned that they also use scholarly books. Databases and Internet pages were named by 13.5% of the respondents. Some special material, like laboratory protocols or computer program manuals, was also mentioned.
The respondents were asked to name the journals which they follow on a regularly basis. The most popular titles were the general scientific journals Nature and Science. The number of followed journal titles named per respondent varied between 0 and 15. Interestingly, 10% of the respondents replied that they do not follow any particular journals, but rather follow topics using the PubMed alerting service.
Google is a very popular tool to search general information on the Internet among researchers in molecular medicine. It was named by 90% of the respondents when asked which tools they use when trying to find essential information concerning their current project on the Internet. Wikipedia was named by 47% (54/116) and Web pages in general, like pages of suppliers, or pages of other research groups were named by 10% (12/116). Only 5% (6/116) of respondents named collaborative news sites or forums as their sources of information.
The data were retrieved predominantly from different Web-based databases, which includegene and protein sequence, structure and function information and genome databases. Up to 91% of the respondents declared that they had used some database during their current project. Data were retrieved from databases and processed with various analysis tools either locally in the researchers' own computers, in other local computers or on a local server or with other tools over the Internet. Bioinformatics database portals, like National Center for Biotechnology Information's Entrez and EMBL-EBI, were popular. Many of these portals enable interlaced use of different databases. Below we show the databases, first by the main discipline of the researchers, and, secondly, by broad research subjects of the research groups. Table 1 shows the average popularity of database types in Nucleic Acid Research's Database Categories (see Galperin 2007). The participants are divided by discipline. The Nucleic Acid Research categories are used at a broad level. The numbers in Table 1 corroborate the findings above that the least database search tasks are performed in biochemistry and medicine, and the most of all in bioinformatics; here the smallest number of databases is mentioned in biochemistry and medicine, and a large number of databases were mentioned among the bioinformatics researchers.
| NAR category | Discipline | |||||||
|---|---|---|---|---|---|---|---|---|
| Bio- chemistry (N=15) | Molecular and cellular biology (N=28) | Genetics (N=40) | Bio- technology (N=7) | Bio- informatics (N=9) | Medicine (N=11) | Other (N=6) | All (N=116) | |
| Portals | 0.80 | 1.07 | 1.05 | 1.00 | 1.00 | 0.73 | 0.17 | 0.95 |
| Nucleotide sequence databases | 0.00 | 0.25 | 0.08 | 0.43 | 0.67 | 0.09 | 0.17 | 0.18 |
| RNA sequence databases | 0.00 | 0.00 | 0.08 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 |
| Protein sequence databases | 0.13 | 0.07 | 0.03 | 0.14 | 1.00 | 0.00 | 0.17 | 0.14 |
| Genomics databases (non-vertebrate) | 0.00 | 0.14 | 0.00 | 0.14 | 0.00 | 0.18 | 0.00 | 0.06 |
| Metabolic and signaling pathways | 0.07 | 0.11 | 0.00 | 0.00 | 0.00 | 0.09 | 0.00 | 0.04 |
| Human and other vertebrate genomes | 0.53 | 0.50 | 1.35 | 0.29 | 1.00 | 0.64 | 0.00 | 0.81 |
| Human genes and diseases | 0.07 | 0.11 | 0.58 | 0.00 | 0.11 | 0.09 | 0.00 | 0.25 |
| Microarray data and other gene expression databases | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 |
| Proteomics resources | 0.13 | 0.00 | 0.03 | 0.14 | 0.00 | 0.00 | 0.00 | 0.03 |
| Other | 0.07 | 0.11 | 0.03 | 0.00 | 0.22 | 0.00 | 0.17 | 0.07 |
| Sum | 1.80 | 2.50 | 3.20 | 2.14 | 4.11 | 1.82 | 0.67 | 2.59 |
| Note: The value 1 indicates that on average every researcher in each discipline group mentioned one database of that type. Categories are based on NAR categories ( Galperin 2007), the category Portals is additional. | ||||||||
The most frequently mentioned databases fell in to the additional category Portals. These include,for example, the Entrez database portal and the EMBL portal. These services include several integrated or separate databases that fall into different Nucleic Acid Research categories.
In Table 2, the respondents are divided differently according to the broad research subjects of their research groups. Some of the headings are similar to Table 1, but the headings stand for the generalized research subjects and thus the distribution is different.
| NAR category | Research subject of research groups | ||||
|---|---|---|---|---|---|
| Molecular and cellular biology (N=36) | Genetics (N=66) | Bio- informatics (N=8) | Systems biology (N=6) | All (N=116) | |
| Portals | 0.92 | 0.88 | 1.25 | 1.50 | 0.95 |
| Nucleotide sequence databases | 0.22 | 0.14 | 0.50 | 0.00 | 0.18 |
| RNA sequence databases | 0.00 | 0.05 | 0.00 | 0.00 | 0.03 |
| Protein sequence databases | 0.11 | 0.05 | 1.13 | 0.00 | 0.14 |
| Genomics databases (non-vertebrate) | 0.06 | 0.06 | 0.00 | 0.17 | 0.06 |
| Metabolic and signaling pathways | 0.08 | 0.03 | 0.00 | 0.00 | 0.04 |
| Human and other vertebrate genomes | 0.31 | 1.08 | 1.00 | 0.67 | 0.81 |
| Human genes and diseases | 0.06 | 0.39 | 0.13 | 0.00 | 0.25 |
| Microarray data and other gene expression databases | 0.00 | 0.03 | 0.00 | 0.33 | 0.03 |
| Proteomics resources | 0.11 | 0.00 | 0.00 | 0.00 | 0.03 |
| Other | 0.03 | 0.06 | 0.25 | 0.17 | 0.07 |
| Sum | 1.89 | 2.76 | 4.25 | 2.83 | 2.59 |
| Note: The value 1 indicates that on average every researcher in each group mentioned one database of that type. Categories are based on NAR categories ( Galperin 2007), the category Portals is additional.) | |||||
The research groups with research subjects related to molecular and cellular biology seem to use a less varied assortment of databases than on average. The bioinformatics research groups used more varied databases than the other groups, and specifically protein databases. The genetics research groups used more databases from the category Human genes and diseases than the other groups. When both tables are considered, the most commonly mentioned databases fell into the Portals category, and into the Human and other vertebrate genomes category.
Many research databases integrate or include tools for analysis. The category of tools is very broad and could be grouped in several ways (for example: data analysis tools, laboratory data analysis tools, literature analysis tools, programming tools, statistical tools, and taxonomies and ontologies). However, we will only mention here the most important ones regardless of their type and leave out the grouping possibility.
In total, ninety-seven different tools and software were named, most of which were open or free software, and twenty-five of them were named more than once. Primer3 (mentioned thirty-eight times) and BLAST (mentioned nineteen times) were the most popular tools. Primer3 is a tool for designing polymerases chain reactions primers which are used in amplifying specific regions in a DNA strand. BLAST is a tool for sequence alignment, searching similarities between sequences. Among the twenty-five most often named tools, there were at least three that were made at the research units in question and two were statistical tools (R and SPSS).
The researchers at Unit B were asked about problems and hurdles they experienced while seeking information (see the subsection on surveys under Data and methods). The majority of the researchers (71%) answered that they had experienced some difficulties.
The perceived problems while seeking information or data in general were classified in five categories: (a) information overflow, (b) lack of information about suitable sources, (c) difficulties in use (lack of skills/difficult interfaces/poor documentation), (d) technical problems (slow connections etc.), and (e) limited access/no access to desired sources. The categories were formed according to the answers: if the amount of information was emphasized, the category (a) was chosen and if difficulties, for example in search key selection or query phrase formulation, were mentioned, category (c) was chosen.
Most of the problems that were reported fell into category (c), difficulties in use. These kinds of problems were experienced by 43% of the respondents who reported problems. Some of the interfaces were too difficult to use and some of the data structures were not suitable for the required use. The subjects' searching skills were not satisfactory and the results of literature searches were inexact. Limited access or no access to desired sources, (e), was problematic to 22% due to lack of institutional subscriptions to some scientific sources. Lack of information on suitable sources, (b), was reported by 14% of the respondents. Information overflow, (a), was the issue in 8% of the reported problems.
The case interviews were recorded for the analysis. The cases were analysed based on the emergent themes and on the themes reflected in the interview and the research questions. The case descriptions were written after the interviews to explain why and how the services to acquire literature and data were used. The aim was to find typical features describing the interaction of the researchers (as users) with the information environment. The case descriptions were therefore analysed for similar features. The narrative case description below reveals the sequence of events of interactions within the information environment. Why and how the interviewed researchers are using the systems or tools is also explained.
The basic research problem in molecular and cellular biology and genetics is to find genes which cause a particular disease, and to understand their functional characteristics. Laboratory work is an essential part of the research work. Bioinformatics research is, on the other hand, pure "in silico" work, including database maintenance and development as well as designing Web services and tools to analyse the data. Two of the PhD students were, at the time of the study, working in the laboratory, the third one was searching information and the fourth writing an article. The seniors were mainly concentrating on research administration, planning and other administrative duties. It became evident that all of them were doing several tasks simultaneously.
Literature is used at different stages of the research work and it is accessed in several ways. In the beginning of a project it is typical to search by focal terms or even by the name of a known specialist through PubMed.
When the core literature is available, current awareness about the topic is arranged by setting up an automated update service in PubMed or using PubCrawler for this purpose. Seniors follow citations to their own, most important articles in Web of Science, a service provided by Thomson Scientific. Table of contents or alerting services for the most important journal titles were also used for current awareness. When the project proceeds, new interests and questions appear and thus a new process for information searching and retrieval starts. Researchers get tips from colleagues or supervisors and might start a chaining process from a new reference. Literature seeking may also start from a homepage of a research group or in some cases from a homepage of a journal. Using links from bioinformatics databases to references of literature services was typical in these cases.
According to the interviews, the number of relevant databases used was rather limited. Protein Data Bank (PDB) was used by the bioinformatics researcher because it was recognized as an authority in that field. The database was used to find structural information about proteins. Even though the needed data were downloaded to the local computer, PDB's Web service was used continuously to check out some details. Usually, the code of the structure was used as a search key to be able to directly get to the structure information. Links to Medline and literature are provided in the database and this feature was frequently used.
Genetics researchers used NCBI's databases frequently. From the Entrez portal, the databases Gene, OMIM, SNP and Protein were named as the most popular. When the gene is not known, SNP array data was used to find homozygote areas from DNA strands. Interesting homozygote areas were found through an analysis tool. These areas were then searched from general gene databases (e.g., Gene) to find out which genes are situated in these areas. There were several genome browsers, and dissimilar opinions existed about the reasons to choose one. Some of the interviewees said that it is mainly the force of habit; some others said that every browser has special functionality which means that they are chosen according to the specific purpose of use. The research group's preferences could affect the selection; if others in the group used some particular service, it was more likely other researchers would choose the same service. Usability (ease of use) and simplicity were also named as the reasons to choose between almost similar services. Genes were searched by the code or abbreviation and links were used to access published articles and other databases for deeper information. Google was used to locate different databases on the Internet.
It appeared that colleagues are an important source of information when tools, methods and laboratory protocols are chosen. This was especially apparent in the research areas where laboratory work is done. In the bioinformatics case, Google and Web-pages functioned as information sources.
Problems concerning information retrieval emerged from the case interviews. These corroborate the findings from the questionnaire. The researchers were using the databases to find evidence from previous research to support their laboratory findings and to interpret new information from the available data. It is hard work to plough through the vast amount of information to find out if the subject has already been investigated and what is known about it (category a). It seemed, however, that there might be differences in this respect between the research areas. The more complex the disease, the higher the amount of published material. There was also a lack of knowledge about the useful sources (category b), or how to use some resources (category c). The documentation of some available databases was found poor or lacking (category c). It was impossible to reuse data, if there existed no information about the format of the data. The limited access to sources, especially to published material was present in the case interviews (category e). The cases showed some query formulation problems (category a). The researchers were having problems with acronyms and short names or with popular names (e.g. Chinese personal names). Gene name synonymy was also a problem: e.g., literature had to be searched with several gene names appearing in PubMed.
The case story is an interpretation of the data collected for this study. The case focuses on the information resources used and the problems encountered in the retrieval and usage of information resources, it is not a complete report on the research process. The complete process is much more complicated and not within the focus of this study.
We present a case of a fictional doctoral student in the midstream of her dissertation project. Her research subject is the genetic background of a common, complex disease. There exists an animal model of the disease and a part of the project is to test it. She is working as a member of a research group which has collaborators outside the primary unit both nationally and internationally. This group is led by a distinguished senior, who has been working in the field for about ten to fifteen years.
A long process of hypothesis creation preceded the start of this new project. The supervisor of the interviewee had, among other things, had discussions about this new, interesting subject with some colleagues and made searches from PubMed using some focal terms as search keys. As a result the supervisor got a list of core articles about the subject which she gave to the interviewee. She started reading at the same time as some routine laboratory work was done.
The selection of the research method and laboratory protocol has, according to the doctoral student, been one of the most essential decisions during the research process. At their unit, many have the habit of making very practical decisions: the method will be selected from those that are already well known or utilized in some other group. The choice is made after discussions with colleagues. She knows that there are some researchers who use, for example, Google or some known research fellow's home pages for this or other general search purposes.
When she worked with the laboratory data she used an analysis tool which was created at the unit. She used one database, dbSNP from the NCBI's Entrez portal to find the positions of genetic markers and the surrounding sequence. Haploview, open access software available on the Internet, was used to view the dependencies between genetic markers.
After screening some interesting candidate genes, broader information about them was searched for from PubMed. If the genes were totally unknown to her, she started from OMIM (NCBI), which consists of the core literature of all human genes. She can also search by the acronym of the gene from Entrez Gene (NCBI), which contains links to many tools and related databases where she can proceed deeper. Sometimes she also uses UCSC Genome Browser, which she knows to be quite popular in many groups because of its simplicity. At the time of the interview she was using Ensembl because she needed clear pictures for her next article and, in her opinion, Ensembl is best in this respect. Her working habit is, like many others at the unit, to use many resources simultaneously and repeatedly even during the writing process.
She keeps up to date during the whole process by using the current awareness service of PubMed where she has a profile which consists of the name of the disease and the codes or acronyms of the possible candidate genes. Every week she gets an email from PubMed, via PubCrawler, which contains the most recent references. PubCrawler is a free update alerting service for PubMed and GenBank. The email contains links to PubMed, and from PubMed it is easy to continue to the full text, presuming that the unit has a license to the journal in question. Recently, she has also started to order table of contents from some journals in which they are planning to publish their research results.
Problems are mostly related to the amount of, and access to, information and lack of knowledge about how to use different tools and databases. She named filtering essential information from the unessential as one of the main problems.
The information environment in molecular medicine appeared to be as varied as was expected. It can be categorized broadly into data, tools, literature and interpersonal communication. Every category has at least some sub-groups. In this study, laboratory work was important to all but the groups in bioinformatics. There are some extensive portals, like NCBI's Entrez which integrate different databases and enable simultaneous searching from different resources. In addition, there are more resources that are connected via links to these databases.
The usage of portals and other integrated resources was substantial. The role of PubMed is central in searching scientific literature and facts, whereas Google is a search engine used to locate general Web pages, research groups, methods and tools. Interpersonal communication seemed to be an effective way to provide information about methods and tools among those groups which do laboratory work. One reason for the importance of interpersonal communication among these groups might be insufficient documentation of laboratory-related work processes.
It is noteworthy that even though scientific articles are a very important source of information to all of the respondents, the importance of journals as the basic object of interest is not equally self-evident. We are not able to explain in this study the causes of this result. A deeper process of change might be happening, this might be just a feature in certain sub-disciplines or it might depend on the career stage of researchers.
Most of the resources in molecular medicine are globally shared and updated, and changing constantly. Compared with other disciplines, database and tool development has been based more often on the common effort and open access/source, in contrast to commercial actors in other disciplines. Researchers are information users and, at the same time, also creators of data and information, and developers of tools. Even though the researchers use a considerable number of different databases, there is not enough time to learn the full potential of these services.
Emblematic features of the information and data seeking was the interlaced use of the resources available. Data and information are sought seamlessly through different databases and there appeared not to be a lucid border between information services. Some of the resources, e.g., Entrez databases, are well integrated and therefore the data found in bioinformatics databases was used to find literature within the same interface without the researcher ever constructing an explicit query and vice versa. It seems that in this respect database creators have succeeded well in understanding how the research process proceeds. Even though we were not able in this study to find out how research work actually proceeds in molecular medicine and at which point a certain type of information is typically needed, we assume that the workflow may involve iterative steps of querying, analysis and optimization (compare with Castro et al. 2005).
Research in information science has seldom concentrated on other than more or less traditional textual information objects (see e.g., Ingwersen and Järvelin 2005 or compare with Chaim 2007).
Our study suggests that the integration between documents and data is becoming more and more important in molecular medicine research work, and it might be profitable to information science in general to focus more on this aspect and to examine the whole information environment comprehensively.
There are some limitations in the present study. As in most Web surveys, there was some bias in terms of who responded; some of the research groups are under-represented. The research groups interested in the development of novel information systems were more likely to answer the questionnaire. Response was voluntary, so presumably the most active researchers did respond. The survey was, however, complemented by the case interviews.
The interviews and the surveys convey ex-post-facto accounts of performance and, therefore, may suffer from omissions, gaps and rationalizations that are not entirely faithful to the actual process. The interviews were valuable in augmenting the survey data. More generally, a study on task-based information access in molecular medicine should start with the information requirements triggered by the actual work situations.
Information access and use in molecular medicine needs more investigation. But as Barry (1995) noticed, at least some parts of the information practices and activities might be implicit and not realized by the respondents. It is possible that there are problems that were not expressed in this stage of the present study. If the problems are not expressed by the researchers, they should be observed in their work when accessing information.
Cognitive work analysis has been found to be an effective way to identify potentially desirable system features and useful bioinformatics tools, and to provide better understanding of some of the unmet needs of the researchers (Bartlett and Toms 2005). The starting point of the research into information practices in molecular medicine should be trying to understand the research processes of these domains, and the work tasks performed to achieve research goals, in more detail. It is presumable that the progress and other changes in the information environment affect research processes and this relationship also needs to be understood (cf. Ingwersen and Järvelin 2005: 78). The extensive collaboration may also have implications for the information environment. One approach to studying the possibilities for enhancing access to information in this field is to observe the researchers while they are conducting their daily work tasks. If the information activities and the work process can be described, it contributes to the design of novel systems.
This paper addressed the information environment in molecular medicine. The information environment consists of several types of databases, information retrieval systems and analysis tools. These are used seamlessly so that data located (or constructed) in one are used to access the other. The most used resources are firstly, for data retrieval, different portals and genome databases. Bioinformatics researchers use more databases than others, both when the distribution is dissected by discipline or research subjects. For acquiring literature, the bibliographic information database PubMed is the most used. The service provides links to the full text documents. In molecular medicine researchers use several data analysis tools , either for the data produced by themselves in laboratories or for the data retrieved from the open databases over the Internet. A typical feature of the domain is the vast number of open source databases, which offer research data for reuse.
The researchers in molecular medicine described lots of problems they experience while they access and use the information resources and tools. Some of the information systems were too difficult to use and some of the data structures were not suitable for any use. The researchers did not have time to learn how to use the services properly. Even when the open source databases and journals are quite typical to the domain, the limited access to the information sources is a big problem. Up-to-date research literature is extremely important to the researchers.
Information related tasks took much of the researchers' time. If the information problems could be relieved, it would release more time for other research work. The database and tool interfaces should be easier to use. There is consequently a need for more research in order to be able to build systems that enhance access to information.
The authors gratefully acknowledge partial funding from the Academy of Finland grants (#120996, #1124131, #204978 and #205993) and the helpful comments of the anonymous referees.
| Find other papers on this subject | ||
© the authors, 2008. Last updated: 18 October, 2007 |
|
