Vol. 11 No. 4, July 2006
| Vol. 11 No. 4, July 2006 | ||||
Introduction. In this research project, an empirical pilot study on the relationship between JavaScript™ usage and Website visibility was carried out. The main purpose was to establish whether JavaScript™-based hyperlinks attract or repel crawlers, resulting in an increase or decrease in Website visibility.
Method. A literature survey has established that there appears to be contradiction amongst claims by various authors as to whether or not crawlers can parse or interpret JavaScript™. The chosen methodology involved the creation of a Website that contains different kinds of links to other pages, where actual data files were stored. Search engine crawler visits to the page pointed to by the different kinds of links were monitored and recorded.
Analysis. This experiment took into account the fact that JavaScript™ can be embedded within the HTML of a Web page or referenced as an external '.js' file. It also considered different ways of specifying links within JavaScript™.
Results. The results obtained indicated that text links provide the highest level of opportunity for crawlers to discover and index non-homepages. In general, crawlers did not follow Javascript™-based links to Web pages blindly.
Conclusions. Most crawlers evade Javascript™ links, implying that Web pages using forms of this technology, for example in pop-up/pull-down menus, could be jeopardising their chances of achieving high search engine rankings. Certain Javascript™ links were not followed at all, which has serious implications for designers of e-Commerce Websites.
The purpose of this research project was to investigate the influence of JavaScript™ on the visibility of Web pages to search engines. Since JavaScript™ can be added to Web pages in different ways, it is necessary to consider all these different ways and investigate how they differ in their influence on the visibility (if at all). The authors will discuss the structure of JavaScript™ content, and also how the Website author can prevent search-engine crawlers (also called robots, bots or spiders) from evaluating JavaScript™ content.
The literature suggests that JavaScript™ can be implemented to abuse search engines - a claim that will be investigated in this research project. Abuse in information retrieval is not a new topic - much has been written about ethical issues surrounding content distribution to the digital consumer (e.g., Weideman 2004a). Most search engines have set policies specifying on what basis some Web pages might be excluded from being indexed, but some do not adhere to their own policies (Mbikiwa 2006:101). Although graphical content is intrinsically invisible to crawlers, many search engines (including the major players like Google, Lycos and AltaVista) are offering specific image searches (Hock 2002).
In a pilot study the authors attempted to determine to what extent search engine crawlers are able to read or interpret pages that contain JavaScript™. The results of this research can later be used as a starting point for further work on this subject.
A number of authors have discussed and performed research on the factors affecting Website visibility. One of them, Ngindana Ngindana 2006: 45, claims that link popularity, keyword density, keyword placement and keyword prominence are important. This author also warns against the use of frames, excessive graphics, Flash home pages and lengthy JavaScript™ routines (Ngindana 2006: 46). Chambers proposes a model which lists a number of elements with positive and negative effects respectively on Website visibility: meta-tags, anchor text, link popularity, domain names (positive effect) as opposed to Flash, link spamming, frames and banner advertising (negative effect) (Chambers 2006:128). In this literature survey, the focus will be on the use and omission of JavaScript™ only.
Netscape developed JavaScript™ in 1995 (Netscape 1998). Originally its purpose was to create a means of accessing Java Applets (which are more functionally complex than is possible in JavaScript™) and to communicate to Web servers. However, it quickly established itself as a means of enhancing the user experience on Web pages over and above achieving the original purpose.
The original intent was to swap images on a user-generated mouse event. Currently JavaScript™ usage varies from timers, through complex validation of forms, to communication to both Java Applets and Web servers. JavaScript™ has been established as a full-fledged scripting language (which in some ways is related to Java) with a large number of built-in functions and abilities (Champeon 2001).
There are two ways to include JavaScript™ on a Web page. First, a separate .js file that contains the script can be used, or the script can be embedded in the HTML code of the Web page (Baartse 2001). Both have definite advantages and disadvantages (see Table 1). The disadvantages of a separate file are the advantages of an embedded script and vice versa.
| Defining JavaScript™ as a separate file | |
|---|---|
| Advantages | Disadvantages |
| Ease of maintenance - script is isolated from unrelated HTML. | No back references - scripts have difficulty in referring back to HTML components. |
| Hidden from foreign browsers - the script is automatically hidden from browsers that do not support JavaScript™. | Additional processing - the interpreter loads all functions defined in the HTML header - including those in external files. It may mean that unnecessary functions are loaded. |
| Library support - general predefined functions can be put in external scripts and referenced later. | Additional server access - when the Web page is loading, it must also load the JavaScript™ file before it can be interpreted. |
Generally JavaScript™ will be programmed using a hybrid environment with both embedded and external scripts. More general functions will be placed in a separate JavaScript™ file while some of the script specifically for a page will be embedded in the HTML (Shiran & Shiran. 1998).
JavaScript™ can also be included in different places on a Web page; the only mandatory requirement is that the script must be declared before it is used. It can either be declared in the <head> tag of the HTML or it can be embedded in the <body> tag, at the point where it is needed. JavaScript™ is currently still under development. Developers who wish to provide scripts to the public must take this into account when developing Web pages and, therefore, a technique has been developed that allows developers to test the environment and execute different scripts for different environments (Shiran & Shiran 1998).
It is important to note that JavaScript™ can be added as the 'href' attributes of anchor tags. This implies that instead of using a normal 'http:' URL, a 'javascript:' URL is specified in the tag. This can have consequences for Website visibility through crawlers which investigate page content to find linked content (Shiran & Shiran 1998).
Three basic types of JavaScript™ links have been identified. This experiment will be testing all three kinds of links:
According to Goetsch (2003), search-engine crawlers cannot interpret JavaScript™ and, therefore, cannot interpret the content it refers to. However, use of the correct design can still make a Web page 'visible' to search-engine crawlers. Venkata (2003), Slocombe (2003a) and Brooks (2003) all agree that crawlers cannot access JavaScript™ and thus ignore it completely. They suggest that Website designers follow some rules to make their pages more visible to crawlers. Brooks (2003 & 2004) specifically states that Google will avoid parsing scripts in general and JavaScript™ in particular.
The design rules for making Web pages containing JavaScript™ visible to crawlers are:
However, some authors disagree with the claim that JavaScript™ is not being interpreted by search-engine crawlers. According to one forum contributor (Chris 2003), there is no reason why a crawler cannot search through JavaScript™ code for links to other pages. The crawler does a string search for certain patterns and does not try to interpret the HTML in any way. Assuming that this is true for all crawlers, they should have no trouble in extracting hyperlinks from JavaScript™ content. It is interesting to note that this specific author is not conclusive about this claim, but only suggests that it is possible.
Authors from Google (2004) support the idea that Web page designers should be careful when using JavaScript™. They are, however, not conclusive and warn that: 'then search engine spiders may have trouble crawling your site'. It is clear that there is not unanimous agreement on these issues - this fact was the major motivation for this research project.
According to Koster (2004) there are two ways to prevent search-engine crawlers from visiting Web pages. One is to use a 'robots.txt' file, placed in the root folder of the Website. This file contains exclusion rules specifically aimed at visiting crawlers. These programs will read this file, parse the rules and visit only those pages that are not excluded by any of the rules.
The second way to exclude content from being seen by crawlers is to use the 'robots' meta-tag in the header section. This tag has the general form:
<meta name="robots" content="noindex">
The 'content' parameter can have the following three values:
When the 'robots.txt' file and/or the <meta> tag is used for exclusion, the Website author effectively instructs the crawler that this part of the Web page must not be indexed for search results.
It appears as if it is not a feasible solution to limit the bandwidth used by crawlers when the page in question should still be listed on the search results. If bandwidth is a problem, the Website author should rather contact the search engine directly with information regarding the problem (Thurow 2003).
Crawler abuse refers to unscrupulous Web page authors attempting to convince crawlers that the content of a given Web page is different from what it really is. This can be done in a number of different ways.
The <noscript> tag can be used to include keywords that have no relevance to the content of the site. This could result in the crawler indexing the site on keywords that are never seen by any human user. Authors agree that this is an unacceptable way to promote a Website and that text in 'hidden' fields (such as the <noscript> tag), should not be adding anything but relevant information for users.
Sites with adult content are regular abusers of JavaScript™. These sites use JavaScript™ to open new windows with new content, which are sometimes hidden behind the main window, so the user does not even see them. This caused crawler developers to view the crawling of JavaScript™ links with care.
Secondly, the <noscript> tag can be populated with links to other pages on the same site.The acceptable way to use this would be to only include links to pages that are actually referenced by the JavaScript™ code. However, one can easily abuse this function by adding a number of unrelated links to the <noscript> tag.This will cause the crawler to browse though pages that are never really referenced by your page.
Another way that JavaScript™ can be used to abuse crawlers is the use of so-called 'doorway' domains. These domains are registered with content, but are seldom seen by the user, because it uses JavaScript™ to automatically forward the user to another domain. Doorway pages and a number of other practices (cloaking, spamming, etc.) are regarded as unethical (Weideman 2004a).
It has been claimed that over 80% of Web traffic is generated by information searches, initiated by users (Nielsen 2004). Web page visibility, if implemented correctly, will ensure that a given Web page is listed in the index of a search engine, and that it will rank well on the user screen when certain keywords are typed by a user. Weidman (2004c) established a set of relationships between Internet users, Websites and other elements, which could contribute to Website visibility. This study then proved that one of these elements, metadata, was underutilised by most Website authors. Another claim in this regard is that single-keyword searching on the Internet has a lower success rate than when a user employs more than one keyword (Weideman and Strumpfer 2004). The use of relevant keywords on a Website can make it more visible and affect the success of single- or multiple-word Internet searches.
From the discussion above, it can be determined that JavaScript™ has an influence on a Web page's visibility to search engines. In many cases search-engine crawlers will completely ignore JavaScript™ content. In other cases the crawlers may be selective about the JavaScript™ links they are willing to include while crawling. This is possible since it is easy to abuse crawlers while using JavaScript™ inclusions.
Futterman (2001) claims that the easiest way to ensure that JavaScript™ pages are search-engine friendly is to provide duplicate HTML code contained within the <noscript> tags. An added advantage is that this page will now also be accessible to older, non-JavaScript™ browsers. Slocombe (2003b) suggests that text alternatives be provided for the same purpose.
It appears as if there are many ways to solve the abuse problem and still achieve good search-engine ratings, even while using JavaScript™. The important thing is that the JavaScript™ must be used properly and that the alternative methods of achieving crawler visibility should be used in conjunction with JavaScript™. Alternatives should also be used properly and not in an abusive way.
Weideman and Kritzinger (2003) claim that meta tags as a Website visibility enhancer in general do not seem to be used much by Website authors. Few search engines seem to recognize them either. Thurow (2004) proposes that the proper use of JavaScript™ will not negatively affect a site's search-engine rating. Abusive use will also not only affect it negatively, but may even lead to complete banning from certain search engines.
The purpose of the pilot study has been identified during the literature survey as being the determination of the ability of the crawlers to find, interpret and follow links contained within JavaScript™ on a Web page. It is clear from the survey that there is some confusion about the ability of search-engine crawlers to interpret links contained in JavaScript™.
This experiment was justified, since the effect that JavaScript™ will have on a Web page's ranking within a search engine, will be directly influenced by the crawler's ability to interpret links contained within JavaScript™.
The study attempted to answer as many as possible of the following questions (Anonymous2 2004):
The experiment was executed by creating a test Website, registered with a number of search engines, and monitored regularly for crawler visits.
Both the Website logs (obtained from the Internet service provider) as well as the information from the different search engines would be collected.
Sullivan's lists of popular search engines and other engines were used to make the initial selection of search engines on which to register the site. From this list, all engines that require a paid registration were eliminated. This was done since payment for having Web pages listed (i.e., paid inclusion and Pay Per Click schemes) overrides natural harvesting of Web pages through crawlers. If these payment systems were included, it would have contaminated results. Closer investigation of the remaining engines showed that some search engines share a common database as their index, although the respective algorhitms would be different. From this investigation, it was clear that registration on one of these grouped engines would enable all the others in the group also to crawl the site.
Another list published by Weideman was used to extend the list of engines.The same criteria were used as for Sullivan's list, but only Weideman's 'standard' engines list was used.
The algorithm used to select the search engines was:
The last point above seems to imply that only crawlers from the selected search engines would visit the registered Web page. However, this was not an expectation during the early stages of the research, since it is certainly possible that a crawler could visit a Web page that has not explicitly been registered. A human user, for example, could visit the test Website (after having found it through one of the registered search engines), and link to it through his or her own Website. This would create the opportunity for any other crawler to visit and index the test Website.
The list of remaining search engines after this process was executed is:
| Aardvark | MSN |
| AESOP | Netscape |
| AllTheWeb | SearchHippo |
| AltaVista | SearchKing |
| AOL | TrueSearch |
| DMOZ | Yahoo! |
For the experiment to be successful, the five questions as well as the types of JavaScript™ needed to be incorporated. The questions could only be answered if different variations of the different link types could be tested. The following list describes all variations that needed to be tested (at least one unique document was used for each type of link identified):
For each of the above, three different ways of identifying the links were used:
For each of these three tests, two different types of scripts were created:
A further two options of each of the tests exists and links were created for them:
This resulted in a large number of tests and documents that were needed for the experiment. A different document was to be used for each kind of link, so the number of unique documents required were calculated as follows:
Number of combinations of link types: (a * b * c * d) + e = 37
where a = 3 (types of JavaScript™ links)
b = 3 (possible ways to build the links)
c = 2 (types of scripts: internal & external)
d = 2 (ways the links can be identified: absolute & relative)
e = 1 (text link = 1x method)
* = multiplication, + = additionFigure 1 shows the main (home) page of the experimental Website. Note that each category will test a different kind of link.
Figure 2 shows the page created for using JavaScript™ in the 'open window ()' method
The experimental home page was registered at all the selected search engines on 24 August 2004. On 14 September 2004, no results were observed in the logs, so the page was registered to the same search engines again. Shortly after this date some crawlers started visiting this site, and the log reflected in Table 2 was created.
The experimental site was created as a data-generating device, not a human friendly Web page.The site content was chosen to simulate an online library of documents. Each document would be accessed by means of a unique link as described above.
The categories in the site were chosen in a way to describe the type of links that are used to access those documents. From the main home page, there are four categories:
Each of these categories has its own page with the documents linked as described.
The Website was closely monitored up to and including 11 December 2005, yielding a total time span of 463 consecutive days. Every visit by a crawler to each one of the non-homepages was recorded in Table 2, where the following notations are used:
An "O" in a box in Table 2 indicates that the crawler followed this specific type of link.An "X" indecates that the crawler attempted to follow the specific type of link but was unsuccessful for some reason.
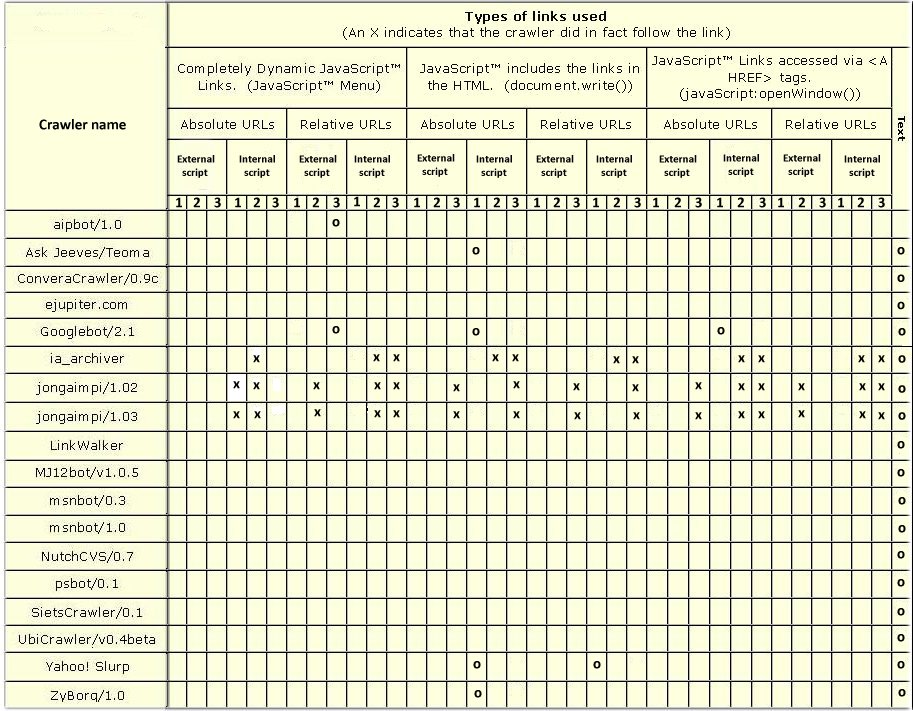
Sixty-five crawlers were noted as visiting the Website during the course of the experiment. Not all of them attempted to load any of the non-homepage pages. Some crawlers only attempted to load the robots.txt file and nothing more.
A detailed summary of the result, together with an interpretation of each point from Table 2 indicates the following:
JavaScript™ seems to have found an application in the modern world that differs from its original intention. The literature survey clearly indicated that Website designers should choose the inclusion method for JavaScript™ based on a variety of factors. The literature survey further indicates that confusion appears to exist about the ability of crawlers to index JavaScript™. This provides challenging material for future research. A number of methods exist to exclude crawlers from reading JavaScript™ on Web pages.
This study produced one conclusive result, namely that text links are the preferred road for crawlers to access sub-pages on a Website. This implies that human-friendly, pop-up menus on Web pages, for example, are one of the stumbling blocks (identified in this project) that prevent the development of search-engine-friendly Websites. It is possible that different crawler algorithms would produce different results, but that fact could not be included in this research, because algorithm details are closely guarded trade secrets and, as such, were not available to be used to enhance the research results.
However, not all the research questions were answered, and more research will have to be done in order to obtain answers to all these questions.
This paper did not set out to find conclusive answers to all results regarding the influence of JavaScript™ on the visibility of a Web page to search engines. In fact, it is clear that more work would need to be done in order to be conclusive.
Possible areas of research include the following:
The authors would like to acknowledge the following institutions for supporting this research project: the National Research Foundation (South Africa) for funding to register the URL; Exinet (employer of one author), for providing the Webspace required to host the test Website and the Cape Peninsula University of Technology for providing overheads to make this project possible.
| Find other papers on this subject. |
|||
© the authors, 2006. Last updated: 11 June, 2006 |
|
