Use of news and patent mining to identify companies with growth potential
Keng-Pei Lin, Tzu-Lin Chang, Yi-Wei Chang, and Jia-Wun Cai
Introduction. Enterprise decision-makers can use news media to help guide investment decisions, and patents are publicly available documents describing research and development outputs. This work sought to leverage the information extracted from news articles and patent documents to identify companies holding patents about emerging technologies. This helped to pinpoint the companies with growth potential.
Method. We used text mining techniques to extract hot terms for novel technologies and products from news articles and patent documents to identify the supply chain companies holding patent portfolios in emerging technologies.
Analysis. We identified eighteen public companies in the supply chain of the automotive industry in Taiwan. The data envelopment analysis-based Malmquist productivity index was adopted to evaluate their relative performance growth over time.
Results. The experimental results show that most of the companies identified by the proposed method had promising growth potential.
Conclusions. The results of this research indicate that the supply chain companies identified by the hot terms in news articles and patent documents possessed development potential. This could assist decision-makers in planning investment strategies.
DOI: https://doi.org/10.47989/irpaper867
Introduction
The world has moved from traditional agricultural and industrial economies to a knowledge economy. Enhancing research and development has become one of the driving forces of economic development, and governments and enterprises are actively investing in innovative technologies. With the development of the Internet and accelerated global competition, globalisation is a major trend for today’s businesses. A single technology makes it difficult to meet business demands, and most innovations involve technological integration across different domains. The companies who possess the technological inventions, innovations or mainstream products have an advantage in capturing new trends in the industry.
The arrival of the knowledge-based economy also comes with information overload. The decision-makers are required to quickly acquire useful information from a large number of information sources to maintain the competitiveness of their enterprises. Due to the progress of information technology, investors and enterprise decision-makers are able to gather information from various sources to assist in their decision making. For example, Lau et al., (2012) proposed a framework for obtaining business relationships and sentiments from financial news and comments on Websites to provide decision support for companies’ mergers and acquisitions activities. Ong et al., (2005) developed an approach to extract business knowledge from Chinese news articles. Bernstein et al., (2003) analysed co-occurrence statistics in the financial news to identify associations between companies. The text mining of financial news has been used for stock price prediction (De Fortuny et al., 2014), and (Huang et al., 2014) indicated that the textual content of news can provide detailed information on various aspects of the company. The literature shows that the news media can deliver valuable information related to enterprises.
Patents are legally binding documents providing protection to the intellectual property of the patentee within a certain time period. Since patents are complete technical documents publicly available with descriptions of the results of research in clear technical details, patents are useful references to help plan investment strategies (Campbell, 1983; Jung, 2003).
In this paper, we propose a framework that uses text mining techniques to extract knowledge from news media and the patent database. The objective is to understand the collaboration across domains and the international supply chain relations to identify technological trends of industries. This will help emerging enterprises make strategic investments in the supply chain companies with growth potential.
Text mining techniques were employed to extract hot terms from the financial and technological news media to identify technological trends. A word embedding technique (Mikolov et al., 2013) was applied to extend the hot terms to include additional related terms to perform a more comprehensive search for current technological trends. The extended hot terms were used as keywords for searching the patent database to identify the supply chain companies developing hot technologies.
We focused on the Taiwanese companies in the automotive industry supply chain. In recent years there have been many innovations in the automotive industry including autonomous and electric cars, and Taiwanese supply chain companies play an important role in the industry. We used the extended terms of new technologies as key phrases to search the United States Patent and Trademark Office patent database to identify Taiwanese companies with a patent portfolio containing new technologies.
To evaluate the effectiveness of the proposed approach, the data envelopment analysis-based Malmquist productivity index (Färe et al., 1994) was adopted to observe the production growth of individual companies over time. Data envelopment analysis (Charnes et al., 1978) is a linear programming technique for measuring the relative efficiency of a set of decision-making units with multiple inputs and multiple outputs based on Farrell’s efficiency model (Farrell, 1957). Basic DEA models, such as CCR (named after Charnes, Cooper and Rhodes), (Charnes et al., 1978) and BCC (named after Banker, Charnes, and Cooper), (Banker et al., 1984), are able to measure the relative efficiency among the decision-making units but are unable to measure the relative efficiency fluctuating over time in the processing of panel data, which involves the comparison of efficiency across different time periods.
The Malmquist productivity index based on data envelopment analysis measures the total factor productivity change over time, which can be further broken down into the technical change and the technical efficiency change. The endogenous growth theory (Romer, 1994) argues that technical progress is a deterministic factor of economic growth. Technical progress can improve productivity and therefore increase revenue. The Malmquist productivity index uses the concept of output growth rate over input growth rate in total factor productivity, which is also the core question behind endogenous growth theory. We utilised the Malmquist productivity index to analyse the productivity performance and technical change over time to observe the growth in productivity of the identified companies. The experimental results indicate that the supply chain companies identified by the proposed approach have developmental potential and are manufacturing new technologies, which may be ideal conditions for them to become hidden champions (Simon, 1992), i.e., small and unknown companies that are highly specialised and in leading positions in their markets. Identifying the supply chain companies with growth potential can also assist decision-makers in their strategic investments, budgeting and resource management to support the growth of their companies.
Literature review
Text mining involves extracting information or knowledge from unstructured textual data by various techniques of machine learning, data mining, information retrieval and natural language processing (Feldman and Sanger, 2006; Feldman et al., 1998). Text mining techniques have been applied to news and social media for business applications (Lau et al., 2012; Bernstein et al., 2003; Bollen et al., 2011; Feldman et al., 2011; Schumaker and Chen, 2009; Lavrenko et al., 2000; Ruiz et al., 2012).
News is an important information source for investors and company decision-makers. Lau et al., (2012) proposed a business intelligence system to provide decision support for companies’ mergers and acquisitions. Financial news articles and comments on news Websites are collected to extract the hidden business relationships among corporations, and comments on news articles were analysed to observe the market responses to transactions.
Bernstein et al., (2003) introduced a relational vector-space model to identify the associations between companies. They assumed that there is a linked relationship between two companies if they simultaneously appear in the same financial news item, and the greater the number of links, the stronger the relationship between the two companies. Examples of simultaneously occurring terms include joint ventures, mergers and acquisitions, and other relationships.
Ma et al., (2011) attempted to infer competitor relationships between companies by them being referred to together in online news articles. Chang et al., (2018) derived the business relationships among companies by performing text mining on news media and annual reports, and utilised such business relationships, which might imply the transfer of knowledge or resources between companies, to build a machine learning-based prediction model to forecast corporations’ performance.
Text mining of news media has also been utilised in stock market prediction. Ruiz et al., (2012) studied the correlation between social media and stock market activities. Feldman et al., (2011) predicted stock prices by analysing the comments and attitudes on news items about companies Bollen et al., (2011) predicted changes in the Dow Jones Index based on evaluating the mood of Twitter posts.
Text mining techniques are widely used in patent analysis. Tseng et al., (2007) developed text mining approaches to assist patent engineers or decision-makers in performing patent analysis. Song et al., (2017) attempted to seek new opportunities for a target technology by performing patent analysis. Text mining techniques were performed on the descriptions of the patent classification criteria and attributes to identify features commonly used in relevant technologies but that are not used in the target technology. Kim et al., (2019) performed text mining in topics from patent documents to identify emerging technologies in the area of wireless power transfer.
Li et al., (in press) performed text mining on news and patent documents to identify the development trends of emerging technologies. They first analysed the evolution of topic models in patents, and then studied the public interest in these emerging technologies by applying the topic models to the news.
Text mining of news and patent analysis can help identify trends in the development of technologies, forecast corporate performance, and predict the stock market. In our research, we capitalised on text mining news articles and patent documents to locate the supply chain companies with growth potential.
Method
The news media can provide useful information concerning various aspects of companies, which can assist the enterprise decision-makers or investors to plan strategic investments in those companies which have developmental potential. In this paper, we focus on the automotive industry’s new technologies to find the supply chain companies with development potential in Taiwan.
The U.S. automotive corporations with substantial market value were first selected from the Compustat financial database, and relevant news was gathered from Yahoo Finance to form a corpus. The corporations with substantial market value appear in a larger number of news articles, are in leading positions in the industry and are able to instantly respond to the newest technological trends. Their news could help identify industry trends and relevant new technologies, and the companies in their supply chain will therefore be prepared for the newest industrial needs.
Text mining techniques were applied to extract hot terms for novel technologies or products, and the word embedding method Word2vec was used to extend these terms semantically to search the U.S. patent database. The patent documents containing these keywords were then collected to identify the Taiwanese supply chain companies holding patents of novel technologies in the database. Then, the Malmquist productivity indexes were calculated for the identified companies to evaluate their growth. The overall flow of the proposed approach is shown in Figure 1.
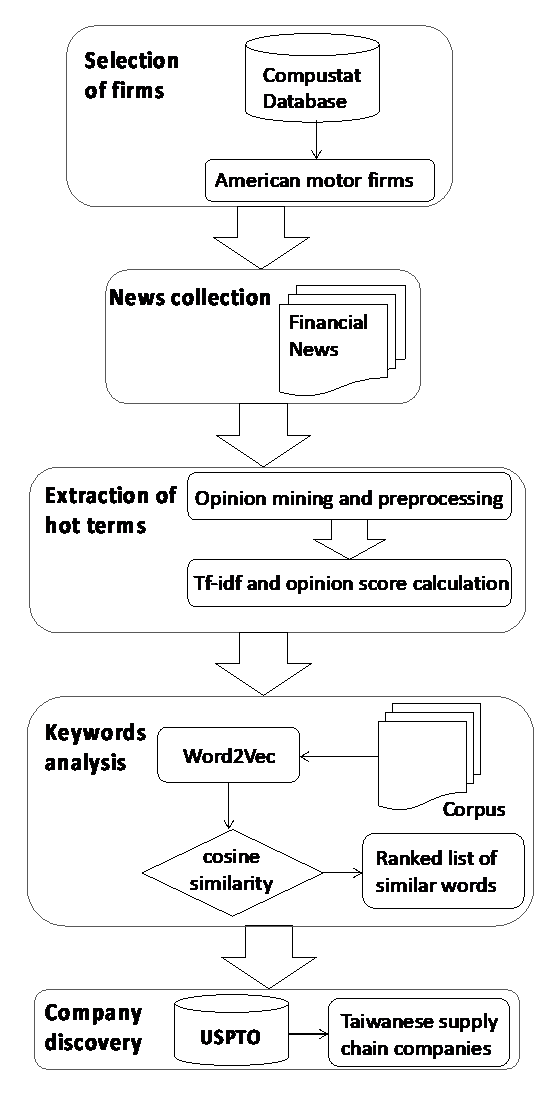
Data collection
We first selected ten U.S. automotive companies with substantial market size belonging to the Standard Industrial Classification code 3711, Motor Vehicles and Passenger Car Bodies, from the Compustat North America database. The relevant news concerning each of these companies was then gathered by inputting their ticker symbols (abbreviations identifying publicly listed companies) into the RSS feed of Yahoo Finance to collect the news articles.
Pre-processing
To conduct textual analysis of the news articles, the following pre-processing procedures were performed:
- Tokenise. Divide the text into discrete words called tokens. Since the news articles were in English, we split text into words using the spaces.
- Remove stop words. Remove common words such as the, a, and is.
- Remove non-letters. All the non-letters were removed such as punctuation, i.e., ?, /, ! and &.
- Perform stemming. Remove prefixes and suffixes to normalise words. For example, run, running and runs were all stemmed to run.
- Perform bigram representation. Natural language processing usually uses an n-gram model, which is a sequence of n adjacent words, with n=2 or 3 to preserve some word sequences. We adopt the bigram language model in this work.
Extracting hot terms from news
In the analysis of textual data, term frequency-inverse document frequency (tf-idf) is a commonly used numerical statistical technique for evaluating the importance of a term to a document in a collection (Salton and Buckley, 1988). This importance is proportional to the frequency of the term appearing in the document and is inversely proportional to how frequently it appears in the collection. Term frequency (tf) calculates the frequency of a term t appearing in a document d, expressed as follows:
where nt,d is the number of occurrences of the term t in the document d, and the denominator is the sum of the occurrence of all terms in d. Inverse document frequency (idf) measures the general importance of a term t in a collection of documents D, expressed by a logarithmically scaled function as follows:
where |D| is the total number of documents in the collection and nt,d is the number of documents containing the term t, where the plus 1 is an adjustment to avoid division by zero. The tf-idf of a term t to a document d in the collection D is then calculated as follows:
Then, we used sentiment scores to weight the hot terms extracted from the financial news. News articles may have positive or negative opinions, and those carrying negative feelings may indicate lower importance of the terms with high tf-idf values. Because we intended to identify hot technological terms from the news, we used opinion mining to estimate the positive and negative scores of the news to weight the importance of terms.
Opinion score of articles
Sentiment analysis is also called opinion mining and uses natural language processing techniques to categorise the contextual polarity of sentiments in articles (Wilson et al., 2005). We performed sentiment analysis to determine the polarity of each news article since the novel technologies or products discussed in the news are usually associated with positive or negative opinions. For example, the Galaxy Note 7 smartphone launched by Samsung in 2016 caused several explosions around the world. We hoped to filter out negative new products or technology similar to this and locate positive instances in the news.
We used OpinionFinder (Wilson et al., 2005), an open-source sentiment analysis tool, to help determine the positive or negative emotions of each news article. OpinionFinder identified subjective sentences and classified the words in the subjective sentences to one of the following five polarities: strong positive, weak positive, strong negative, weak negative and neutral. Note that OpinionFinder has its own pre-processing procedures and, therefore, does not use the pre-processing steps described above.
To determine the importance of a news article, we needed to design an aggregate opinion score for an article based on the polarities identified by OpinionFinder. The positive score of an article d is calculated as follows:
where Nsp, Nwp, and Nn denote the number of words with strong positive, weak positive and neutral polarity identified by OpinionFinder in an article, respectively, and M is the total number of words with any one of the five polarities in the article. Different weights are assigned to these polarities. The weight of the strong positive polarity is set to 1 and the weight of the weak positive polarity is set to 0.5. Because the words with neutral polarity in subjective sentences may contain information with certain influences, we set the weight of neutral polarity to 0.1.
The negative score of an article d is similarly calculated as follows:
where Nsn and Nwn denote the number of words with strong negative and weak negative polarity in an article, respectively.
The aggregate opinion score of an article is defined as the ratio of positive score to negative score in logarithmic scale as follows:
The adjustment of plus one in both the numerator and denominator is to avoid the logarithm of zero and division by zero, respectively. The articles with a larger negative score will result in lower opinion scores, which means lower importance of the hot terms extracted in the previous step.
By calculating the tf-idf of terms appearing in news articles with the weights of the opinion scores of each article, we obtained the term scores as follows:
where D is the corpus of financial news articles, tf(t,d) is the term frequency of the term t in an article d, idf(t,D) is the inverse document frequency of the term t in the corpus D, and OpinionScore(d) is the opinion score of news article d.
All the terms that appeared in news articles were then ranked by their term scores. We selected the terms in the top 20% of the term scores as the hot terms of novel technologies. To better capture the trends, we imposed a two-month time window for the hot terms, i.e., the hot terms must remain in the top 20% for at least two consecutive months.
Extending hot terms with word embedding
We extended the identified hot terms to their contextually related terms, which may represent the functions or components of novel technologies or new products. Specifically, we applied the word embedding technique (Bengio et al., 2006; Collobert and Weston, 2008; Mnih and Hinton, 2008) to capture semantic relationships of terms.
We adopted word2vec, a word-embedding technique, to extend the extracted hot terms. Word embedding is used to represent unstructured corpus words with low-dimensional vectors. These representations are fairly accurate and capable of solving a variety of language tasks (Baroni et al., 2014; Collobert et al., 2011; Turian et al., 2010). The word2vec technique was developed by Mikolov et al., (2013) and is a group of neural network models that produce word embeddings, which are unsupervised algorithms attempting to learn the connections between terms. The idea behind word2vec is grouping similar terms in clusters for effective use of the vector space. In particular, Mikolov et al., (2013) showed that word2vec can generate specific terms through simple mathematical operations such as vector(king) - vector(man) + vector(woman), which gives results closer to vector(queen) than any other terms in the corpus. The word2vec methods are generally unsupervised, do not require domain information and have broad applicability. The developer of word2vec has published a pretrained word2vec model trained on a portion of a Google news dataset that contains approximately 100 billion words, resulting in a model with three million words and phrases in 300-dimensional vectors.
We employed this pretrained word2vec model to extend the hot terms. The hot terms of novel technologies extracted from the news in the previous step were used as query words in the word2vec models. The word2vec models generate semantically related words, and the model will return the closest words and their cosine similarity measures with respect to the query word. We adopted the top ten words closest to the input hot term as keywords to search the patent databases to locate the supply chain companies with patent portfolios containing novel technologies.
High growth potential company discovery
Patent documents contain rich information about the technological development of companies. In this research, the patent documents of the USPTO database were used to locate the Taiwanese supply chain companies with development potential.
We used the hot terms and the word2vec-generated extended terms to search the USPTO database. We searched the full text of the patent documents from the USPTO database with each hot term and each hot term’s extended word to find the patents related to novel technologies or products. For those patents with applicants from Taiwan that featured one of the hot terms or extended hot terms, the companies owning the patents were identified as possessing developmental potential.
To evaluate the effectiveness of the proposed approach, we used the news articles from the previous three quarter-years to extract important hot terms to identify the supply chain companies with growth potential and evaluate the performance of the identified companies during one year. For example, in our experiment, the news articles we collected were between the third quarter of 2015 and the first quarter of 2016, and the performance growth was evaluated for the time period between the first and fourth quarters of 2016.
The Malmquist productivity index proposed by Caves et al., (1982) based on Malmquist’s theory (Malmquist, 1953) is used to measure productivity. Färe et al., (1994) adopted the index for total factor productivity growth defined by Caves et al., (1982a), and combined it with Farrell’s efficiency model (Farrell, 1957) to develop a developoment envelopment analysis-based Malmquist productivity index that can be employed to measure the change in productivity performance of a decision-making unit at different time periods.
The Malmquist productivity index has been used in business performance evaluation, including the performance of regional research and development investments (Zhong et al., 2011), the high-tech manufacturing industry (Tseng et al., 2009) and supply chain management (Wong and Wong, 2007). We used the Malmquist productivity index to evaluate the growth of the identified high potential companies.
The Malmquist productivity index that calculates the total factor productivity change is constructed as the geometric mean of two Malmquist productivity indexes, and the DEA is utilised to calculate the distance functions for measuring productivity changes. It is defined as follows:
where xt and yt and xt+1 and yt+1 are the inputs and outputs of a decision-making unit in time periods t and t+1, respectively. The distance functions and measure the decision-making unit’s efficiency by DEA in time periods t and t+1, respectively, i.e., the distance from the observed value to the frontier in the same period. The other two distance functions measure the intertemporal distances. The distance function measures the efficiency in time period t+1 using the production technology of time period t, which is also known as the growth index (Sueyoshi, 1998); the distance function measures the efficiency at time t using the production technology of time period t+1.
The first Malmquist productivity index measures the proportional change in efficiency from time period t to t+1 using the technology in time period t as the reference, and the second Malmquist productivity index measures the efficiency change using the technology in time period t+1 as the reference. Then, the geometric mean of the two indexes is calculated to avoid choosing an arbitrary benchmark.
The total factor productivity index with a value above one indicates that the decision-making unit makes progress in total factor productivity from time period t to time period t+1, and the index with a value below one indicates that the decision-making unit declines in total factor productivity.
The total factor productivity index can be decomposed into the multiplication of technical efficiency change and technical change by rewriting equation (1) as follows:
where the term outside the bracket measures the relative change in efficiency between time period t and t+1, i.e., the technical efficiency change = ; the term inside the bracket is the geometric mean of two ratios that captures the shift in technology from time period t to t+1, i.e., the technical change = . The technical efficiency change is also known as the catch-up effect and the technical change is also known as the frontier-shift or innovation effect.
Results
We conducted experiments to locate Taiwanese supply chain companies with developmental potential. To test the effectiveness of the proposed approach, we use the data envelopment analysis-based Malmquist productivity index to evaluate the relative performance of companies over time to observe their growth.
We focused on automotive industries in North America due to their leading positions and influence on the supply chain in Taiwan. Therefore, ten publicly listed U.S. motor companies with substantial market size were selected. Their names and ticker symbols are shown in Table 1. The relevant financial news about these ten companies was collected from Yahoo Finance, which pools news articles from the Wall Street Journal, Bloomberg, Business Wire, CNN Financial News, Dow Jones, Financial Times, Forbes, Reuters, and others. The news articles collected were published between July 1, 2015 and March 31, 2016; there were a total of 5,252 news articles.
| Company name | Ticker symbol |
|---|---|
| Daimler AG | DDAIF |
| Ford Motor Company | F |
| General Motors Company | GM |
| Tesla, Inc. | TSLA |
| PACCAR, Inc. | PCAR |
| Oshkosh Corporation | OSK |
| Navistar International Corporation | NAV |
| LCI Industries | LCII |
| Tower International, Inc. | TOWR |
| Spartan Motors, Inc. | SPAR |
We used the term score formula to extract the hot terms with a top 20% term score for at least two consecutive months. The results are shown in Table 2. From the results, we can see that the frequently discussed important terms between July 1, 2015 and March 31, 2016 include energy storage, autonomous vehicles, electric cars, lithium-ion batteries and others. These coincide with the well-known trends in the automotive industry in recent years.
| automatic emergency | autonomous vehicle | autopilot feature |
| backup assist | battery pack | charging station |
| electric car | electric vehicle | emergency braking |
| energy storage | environmental protection | fully electric |
| ion battery | lithium ion | media player |
| plugin hybrid | single charge | tactical vehicle |
| test drive | touch screen | trailer backup |
It can be seen that some of the extracted hot terms are quite general, such as electric car or autonomous vehicle. Therefore, we applied the word embedding technique to extend the hot terms to include semantically similar terms. This is because if only electric car or autonomous vehicle were used to search the patent documents in the USPTO database, the search may not have returned the supply chain companies manufacturing specific components of an electric car or autonomous vehicle.
Using the term electric car as an example, the ten most semantically similar words from applying word embedding to the term electric car are shown in Table 3. The results of word embedding of electric car include the automakers, component suppliers and vehicles with different electric modes. Electric vehicles (EVs) use electric motors for propulsion. Hybrid vehicles combine a conventional fuel engine with electric propulsion, and a plug-in hybrid vehicle (PHEV) has a battery that can be charged from external power sources. Some electric vehicles are equipped with a fuel cell to generate power to extend their range.
| Extended word | Cosine similarity measure |
|---|---|
| electric vehicle | 0.721 |
| hybrid electric | 0.582 |
| EVs | 0.581 |
| hybrid vehicles | 0.574 |
| PHEV | 0.553 |
| zero emission vehicles | 0.549 |
| fuel cell vehicles | 0.546 |
| Tanfield Group | 0.542 |
| Coulomb Technologies | 0.542 |
| Wheego 0.536 | 0.536 |
The hot terms and extended words related to them were used to search for the relevant patents in the USPTO database to locate the Taiwanese supply chain companies of the automotive industry. There were a total of thirty-three companies identified by the proposed approach; eighteen were listed companies. Since unlisted companies do not publish their financial reports, it is difficult to evaluate their growth. Therefore, we only evaluated the performance of the eighteen listed companies. The eighteen company names and their codes are listed in Table 4.
| Company name | Code |
|---|---|
| Sun Race Sturmey-Archer, Inc. | 1526 |
| Chi Hua Fitness Co., Ltd. | 1593 |
| Lite-On Technology Corporation | 2301 |
| Delta Electronics, Inc. | 2308 |
| Advanced Semiconductor Engineering, Inc. | 2311 |
| Kinpo Electronics, Inc. | 2312 |
| Hon Hai Precision Industry Co., Ltd. | 2317 |
| Via Technologies, Inc. | 2388 |
| AU Optronics Corporation | 2409 |
| Epistar Corporation | 2448 |
| K. S. Terminals, Inc. | 3003 |
| AVer Information, Inc. | 3669 |
| Mitac International Corp. | 3706 |
| Aleees Eco Ark Co., Ltd. | 5227 |
| Simplo Technology Co., Ltd. | 6121 |
| Amazing Microelectronic Corp. | 6411 |
| Taiwan Hopax Chemicals Mfg. Co., Ltd. | 6509 |
| Changs Ascending Enterprise Co., Ltd. | 8038 |
In the list, there are well-known electric car supply chain companies including Aleees Eco Ark Co., Ltd.; Simplo Technology Co., Ltd.; Changs Ascending Enterprise Co., Ltd.; Delta Electronics, Inc.; Taiwan Hopax Chemicals Mfg. Co., Ltd.; and K. S. Terminals, Inc. In addition to the traditional supply chain companies in the field of electric vehicles, players with more diverse operations appear, such as Hon Hai Precision Industry Co., Ltd.
Evaluation of the performance growth
Since the news articles we collected for extracting important hot terms were published between July 1, 2015 (third quarter of 2015) and March 31, 2016 (first quarter of 2016), we evaluated the performance growth of the selected supply chain companies between the first and fourth quarters of 2016 to test the effectiveness of the proposed approach. The Malmquist productivity index based on data envelopment analysis of the supply chain companies was calculated to compare the performance changes between different quarters.
Therefore, we used the total assets, total liabilities, operating costs and operating expenses of the companies as the input factors to discuss how they generate revenues through the interplay of these factors. Since the application of data envelopment analysis requires a positive correlation between the inputs and outputs, the Pearson correlation coefficient, which primarily evaluates the degree of linear correlation between two random variables, was chosen to be the analytical method for the determination of input and output variables. Table 5 shows the Pearson correlation coefficients of all the inputs to the output; they are all positively correlated.
| Total assets | Total liabilities | Operating costs | Operating expenses | |
|---|---|---|---|---|
| Operating revenue | 0.925** | 0.936** | 1.000** | 0.974** |
| ** Very significant | ||||
The Malmquist productivity index based on data envelopment analysis is calculated to analyse the trends in productivity changes to explore the quarterly changes of the companies. Table 6 shows the changes in total factor productivity of the eighteen supply chain companies between the first and fourth quarters of 2016, by quarter. A value greater than 1 indicates improvements in the productivity of the company during that quarter, compared to the previous quarter. Except for Changs Ascending Enterprise Co., Ltd. (8038), which shows a slight decline, the remaining seventeen companies increased in total factor productivity.
| Company code | 2016 Q1 ➝ 2016 Q2 | 2016 Q2 ➝ 2016 Q3 | 2016 Q3 ➝ 2016 Q4 | Average change (geometric mean) |
|---|---|---|---|---|
| 1526 | 1.074 | 1.018 | 0.988 | 1.026 |
| 1593 | 1.161 | 1.232 | 1.166 | 1.186 |
| 2301 | 1.101 | 1.048 | 1.033 | 1.060 |
| 2308 | 1.141 | 1.098 | 1.052 | 1.096 |
| 2311 | 1.020 | 1.025 | 1.013 | 1.019 |
| 2312 | 1.300 | 1.151 | 1.109 | 1.184 |
| 2317 | 1.353 | 1.196 | 1.169 | 1.237 |
| 2388 | 1.159 | 1.091 | 1.084 | 1.111 |
| 2409 | 1.050 | 1.041 | 1.035 | 1.042 |
| 2448 | 1.092 | 1.068 | 1.037 | 1.065 |
| 3003 | 1.092 | 1.050 | 1.024 | 1.055 |
| 3669 | 1.373 | 1.250 | 1.141 | 1.251 |
| 3706 | 1.306 | 1.086 | 1.212 | 1.198 |
| 5227 | 1.290 | 1.052 | 1.032 | 1.119 |
| 6121 | 1.260 | 1.093 | 1.062 | 1.135 |
| 6411 | 1.181 | 1.126 | 1.130 | 1.145 |
| 6509 | 1.017 | 1.014 | 1.016 | 1.016 |
| 8038 | 0.977 | 0.995 | 0.881 | 0.950 |
Then, we broke down the total factor productivity into technical efficiency change and technical change, also known as the catch-up effect and the innovation effect, respectively. Table 7 shows the technical efficiency changes and Table 8 shows the technical changes of the eighteen supply chain companies. Similarly, a value greater than one indicates improvements over the previous quarter.
The technical changes, which reflect the changes in the technical frontier-shift over time, improved for all companies. The technical efficiency changes showed the improvements in efficiency using the productivity technology over time. The results show that some companies slightly declined in technical efficiency. It is seen that Changs Ascending Enterprise Co., Ltd. (8038) declined more in technical efficiency than the other companies. This might be caused by the company’s change in strategy in 2016—in addition to manufacturing lithium-ion batteries for electric vehicles, the company decided to develop lithium-ion battery packs for uninterruptible power supplies to become a supply chain company for the semiconductor industry. The decline in technical efficiency of that company might have resulted from the development of new products.
From the calculations of the Malmquist productivity index, we can see that between the first and fourth quarters of 2016, the total factor productivity change of most of the identified eighteen supply chain companies in Taiwan was stable and grew progressively. This confirms that the proposed text mining-based method, where the financial news articles collected were published between the third quarter of 2015 and the first quarter of 2016, was able to identify supply chain companies with growth potential.
| Company code | 2016 Q1 ➝ 2016 Q2 | 2016 Q2 ➝ 2016 Q3 | 2016 Q3 ➝ 2016 Q4 | Average change (geometric mean) |
|---|---|---|---|---|
| 1526 | 1.006 | 1.000 | 0.976 | 0.994 |
| 1593 | 0.987 | 1.014 | 1.000 | 1.000 |
| 2301 | 0.992 | 1.011 | 1.008 | 1.004 |
| 2308 | 0.997 | 1.005 | 0.979 | 0.994 |
| 2311 | 0.978 | 1.015 | 1.005 | 0.999 |
| 2312 | 1.008 | 1.005 | 0.990 | 1.001 |
| 2317 | 1.000 | 1.000 | 1.000 | 1.000 |
| 2388 | 0.971 | 0.959 | 1.014 | 0.981 |
| 2409 | 1.028 | 1.039 | 1.036 | 1.034 |
| 2448 | 1.051 | 1.068 | 1.032 | 1.050 |
| 3003 | 1.000 | 1.000 | 1.000 | 1.000 |
| 3669 | 1.000 | 1.000 | 1.000 | 1.000 |
| 3706 | 1.015 | 0.975 | 1.042 | 1.010 |
| 5227 | 1.043 | 0.966 | 1.038 | 1.015 |
| 6121 | 1.000 | 1.000 | 1.000 | 1.000 |
| 6411 | 1.000 | 1.000 | 1.000 | 1.000 |
| 6509 | 0.947 | 0.988 | 0.993 | 0.976 |
| 8038 | 0.949 | 0.979 | 0.885 | 0.937 |
| Company code | 2016 Q1 ➝ 2016 Q2 | 2016 Q2 ➝ 2016 Q3 | 2016 Q3 ➝ 2016 Q4 | Average change (geometric mean) |
|---|---|---|---|---|
| 1526 | 1.067 | 1.018 | 1.012 | 1.032 |
| 1593 | 1.177 | 1.215 | 1.166 | 1.186 |
| 2301 | 1.110 | 1.037 | 1.025 | 1.057 |
| 2308 | 1.144 | 1.093 | 1.074 | 1.103 |
| 2311 | 1.043 | 1.009 | 1.008 | 1.020 |
| 2312 | 1.289 | 1.145 | 1.121 | 1.183 |
| 2317 | 1.353 | 1.196 | 1.169 | 1.237 |
| 2388 | 1.193 | 1.138 | 1.069 | 1.132 |
| 2409 | 1.022 | 1.002 | 0.999 | 1.008 |
| 2448 | 1.040 | 1.000 | 1.005 | 1.015 |
| 3003 | 1.092 | 1.050 | 1.024 | 1.055 |
| 3669 | 1.373 | 1.250 | 1.141 | 1.251 |
| 3706 | 1.287 | 1.113 | 1.163 | 1.185 |
| 5227 | 1.237 | 1.089 | 0.994 | 1.102 |
| 6121 | 1.260 | 1.093 | 1.062 | 1.135 |
| 6411 | 1.181 | 1.126 | 1.130 | 1.145 |
| 6509 | 1.074 | 1.027 | 1.023 | 1.041 |
| 8038 | 1.029 | 1.017 | 0.996 | 1.014 |
As a comparison, we found three publicly listed Taiwanese companies, HIWIN Technologies Corp. (2049), Chroma ATE, Inc. (2360), and SOE Co., Ltd. (6283), which are also automotive supply chain companies but were not identified by the proposed method. The total factor productivity changes, technical efficiency changes, and technical changes of those three companies are shown in Table 9.
Two of the non-selected companies, Chroma ATE, Inc. (2360) and SOE Co., Ltd. (6283), reveal a decline in total factor productivity, with a value of approximately 0.95 for both companies. The technical changes of both companies were also approximately 0.95, indicating a decline. HIWIN Technologies Corp. (2049) increased in total factor productivity but was not selected by the proposed method. This may be because the proposed method utilised the news of U.S. automotive companies to identify the supply chain companies, but HIWIN Technologies Corp. (2049), which is a supply chain company of Toyota Motor Corporation, is mainly focused on the Japanese rather than the U.S. automotive industry.
| Company code | 2016 Q1 ➝ 2016 Q2 | 2016 Q2 ➝ 2016 Q3 | 2016 Q3 ➝ 2016 Q4 | Average change (geometric mean) |
|---|---|---|---|---|
| Total factor productivity change | ||||
| 2049 | 0.993 | 1.084 | 1.107 | 1.060 |
| 2360 | 0.909 | 1.092 | 0.869 | 0.952 |
| 6283 | 0.866 | 0.981 | 1.011 | 0.951 |
| Technical efficiency change | ||||
| 2049 | 1.027 | 1.000 | 1.000 | 1.009 |
| 2360 | 1.000 | 1.000 | 1.000 | 1.000 |
| 6283 | 1.000 | 0.915 | 0.915 | 0.942 |
| Technical change | ||||
| 2049 | 0.967 | 1.084 | 1.107 | 1.051 |
| 2360 | 0.909 | 1.092 | 0.869 | 0.952 |
| 6283 | 0.866 | 1.072 | 0.925 | 0.950 |
Discussion
The patent portfolio of an enterprise not only protects its research and development results but also enhances its competitiveness. The patent portfolio is also a cost to an enterprise and will be reflected on its operating cost and expenses. Therefore, we used the concept of output growth rate over input growth rate in total factor productivity, the technical change, and technical efficiency change to evaluate the performance growth of enterprises. The experimental results show that the proposed method is able to identify supply chain companies with growth potential, indicating that the proposed method can be utilised to assist the corporate decision makers for strategic investments to support the growth of the supply chain companies.
Song et al., (2017) and Li et al., (2019) proposed capitalising on patent documents to seek new technological opportunities and identify trends in developing emerging technologies. A similar concept was adopted in our work to identify the companies with patent portfolios about emerging technologies. In addition to patent documents, we adopted news information to capture the latest trends in technologies. News articles can rapidly respond to recent technological trends, and the patent portfolio can reflect the long-term development trend of a company. We reviewed the short-term and long-term technological trend information to identify the companies with development potential. The proposed method may be able to complement with existing approaches with different perspectives such as the work of Chang et al., (2018) which derived business relationships from news articles and annual reports to forecast corporate performance, and the work of Li et al., (in press) which used topic modelling on patent documents and news articles to identify the development trends of emerging technologies.
Then we discuss the limitations of the proposed method. In our experimental results, parts of the identified companies are unlisted. We anticipate the proposed method being able to identify the companies with developmental potential to become hidden champions. However, since these unlisted companies do not publish their financial status, it is difficult to validate the results of these companies with low public awareness. Besides, as noted by Song, et al., (2017), the new technologies are typically developed across geographical boundaries. Therefore, the patent documents may cross over several patent databases in different languages which could further complicate searching the patent documents.
Conclusion
In this paper, we propose an information extraction method for identifying supply chain companies with growth potential by mining the financial news and patent database. The experimental results show that the trends in the U.S. automotive industry could be extracted, and by using the word embedding of extracted trends to search the USPTO patent database, supply chain companies in Taiwan with growth potential could be identified. The identified Taiwanese supply chain companies matched our own knowledge of the industry and were verified by calculating the DEA-based Malmquist productivity indexes, which evaluate the performance changes of companies over time. We anticipate that the proposed method could be implemented in other fields. Future directions for this research include applying the method to other industries and integrating with decision support systems to help enterprise decision-makers plan for resource allocation and investments.
Acknowledgements
This work was partially supported by the Metal Industries Research and Development Centre, Taiwan, from September 2016 to August 2017, and the Ministry of Science and Technology, Taiwan, under grant MOST 108-2410-H-110-060-MY2.
About the authors
Keng-Pei Lin (corresponding author) is an Associate Professor in the Department of Information Management, National Sun Yat-sen University, Kaohsiung, Taiwan. He received his Ph.D. degree in electrical engineering from National Taiwan University, Taipei, Taiwan, in 2011. His main research interests are in data mining, data management and machine learning. He can be contacted at kplin@mis.nsysu.edu.tw
Tzu-Lin Chang is a Ph.D. candidate in the Department of Accounting, National Taiwan University, Taipei, Taiwan. Her main research interests are in management accounting, corporate governance and accounting information systems. She can be contacted at d01722002@ntu.edu.tw
Yi-Wei Chang is a Ph.D. candidate in the Department of Information Management, National Sun Yat-sen University, Kaohsiung, Taiwan. His main research interests are in deep learning, data mining and text mining. He can be contacted at ywchang@g-mail.nsysu.edu.tw
Jia-Wun Cai completed her master degree in the Department of Information Management, National Sun Yat-sen University, Kaohsiung, Taiwan, in 2017. She can be contacted at s711052@gmail.com
References
Note: A link from the title is to an open access document. A link from the DOI is to the publisher's page for the document.
- Banker, R. D., Charnes, A. & Cooper, W. W. (1984). Some models for estimating technical and scale inefficiencies in data envelopment analysis. Management Science, 30(9), 1078-1092. https://doi.org/10.1287/mnsc.30.9.1078
- Baroni, M., Dinu, G., & Kruszewski, G. (2014). Don’t count, predict! A systematic comparison of context-counting vs. context-predicting semantic vectors. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (pp. 238-247). Association for Computational Linguistics. https://doi.org/10.3115/v1/P14-1023
- Bengio, Y., Schwenk, H., Senécal, J.-S., Morin, F., & Gauvain, J.-L. (2006). Neural probabilistic language models. In D. E. Holmes & L. C. Jain, (Eds.), Innovations in Machine Learning (pp. 137-186). Springer. https://doi.org/10.1007/3-540-33486-6_6
- Bernstein, A., Clearwater, S., & Provost, F. (2003). The relational vector-space model and industry classification. In Proceedings of the Learning Statistical Models from Relational Data Workshop at the Eighteenth International Joint Conference on Artificial Intelligence (pp. 8-18). https://scholarworks.umass.edu/cs_faculty_pubs/162 (Archived by the Internet Archive at https://bit.ly/2BLXdaB)
- Bollen, J., Mao, H., & Zeng, X. (2011). Twitter mood predicts the stock market. Journal of Computational Science, 2(1), 1-8. https://doi.org/10.1016/j.jocs.2010.12.007
- Campbell, R. S. (1983). Patent trends as a technological forecasting tool. World Patent Information, 5(3), 137-143. https://doi.org/10.1016/0172-2190(83)90134-5
- Caves, D.W., Christensen, L.R., & Diewert. W.E. (1982). The economic theory of index numbers and the measurement of input, output, and productivity. Econometrica, 50(6), 1393-1414. https://doi.org/10.2307/1913388
- Caves, D.W., Christensen, L.R., & Diewert. W.E. (1982a). Multilateral comparison of output, input and productivity using superlative index numbers. The Economic Journal, 92(365), 73-86. https://doi.org/10.2307/2232257
- Chang, T. M., Hsu, M. F., & Lin, S. J. (2018). Integrated news mining technique and AI-based mechanism for corporate performance forecasting. Information Sciences, 424, 273-286. https://doi.org/10.1016/j.ins.2017.10.004
- Charnes, A., Cooper, W. W., & Rhodes, E. (1978). Measuring the efficiency of decision making units. European Journal of Operational Research, 2(6), 429-444. https://doi.org/10.1016/0377-2217(78)90138-8
- Collobert, R. & Weston, J. (2008). A unified architecture for natural language processing: deep neural networks with multitask learning. In Proceedings of the 25th International Conference on Machine Learning, Helsinki Finland July, 2008 (pp. 160-167). Association for Computing Machinery. https://doi.org/10.1145/1390156.1390177
- Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., & Kuksa, P. (2011). Natural language processing (almost) from scratch. Journal of Machine Learning Research, 12, 2493-2537. https://dl.acm.org/doi/10.5555/1953048.2078186
- De Fortuny, E. J., Smedt, T. D., Martens, D., & Daelemans, W. (2014). Evaluating and understanding text-based stock price prediction models. Information Processing & Management, 50(2) 426-441. https://doi.org/10.1016/j.ipm.2013.12.002
- Färe, R., Grosskopf, S., Norris, M., & Zhang, Z. (1994). Productivity growth, technical progress, and efficiency changes in industrialized countries. The American Economic Review, 84(1), 66-83. https://www.jstor.org/stable/2117971
- Farrell, M. J. (1957). The measurement of productive efficiency. Journal of the Royal Statistical Society. Series A, 120(3), 253-290. https://doi.org/10.2307/2343100
- Feldman, R. & Sanger, J. (2006). The text mining handbook: advanced approaches in analyzing unstructured data. Cambridge University Press.
- Feldman, R., Fresko, M., Kinar, Y., Lindell, Y., Liphstat, O., Rajman, M., Schler, Y. & Zamir, O. (1998). Text mining at the term level. In J.M. Zytkow, and M. Quafafou, (Eds.). Proceedings of the 2nd European Symposium on Principles of Data Mining and Knowledge Discovery, Nantes, France, September 23-26, 1998 (pp. 65-73). Springer. https://doi.org/10.1007/BFb0094806
- Feldman, R., Rosenfeld, B., Bar-Haim, R. & Fresko, M. (2011). The stock sonar - sentiment analysis of stocks based on a hybrid approach. In Proceedings of the 23rd Innovative Applications of Artificial Intelligence Conference, an Francisco, California, USA, August 9-11. (pp. 1642-1647). AAAI. https://www.aaai.org/ocs/index.php/IAAI/IAAI-11/paper/view/3506
- Huang, A. H., Zang, A. Y. & Zheng, R. (2014). Evidence on the information content of text in analyst reports. The Accounting Review, 89(6), 2151-2180. https://doi.org/10.2308/accr-50833
- Kim, K. H., Han, Y. J., Lee, S., Cho, S. W. & Lee, C. (2019). Text mining for patent analysis to forecast emerging technologies in wireless power transfer. Sustainability, 11(22), 6240. https://doi.org/10.3390/su11226240
- Jung, S. (2003). Importance of using patent information. World International Patent Organization. https://www.wipo.int/edocs/mdocs/sme/en/wipo_ip_bis_ge_03/wipo_ip_bis_ge_03_13-main1.pdf
- Lavrenko, V., Schmill, M., Lawrie, D., Ogilvie, P., Jensen, D. & Allan, J. (2000). Mining of concurrent text and time series. Paper presented at the Workshop on Text Mining, Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, Massachusetts, USA, August, 2000. https://www.cs.cmu.edu/~dunja/KDDpapers/Lavrenko_TM.pdf (Archived by the Internet Archive at https://bit.ly/2Xg9HPo)
- Lau, R. Y. K., Liao, S. S. Y., Wong, K. F. & Chiu, D. K. W. (2012). Web 2.0 environmental scanning and adaptive decision support for business mergers and acquisitions. MIS Quarterly, 36(4), 1239-1268. https://doi.org/10.2307/41703506
- Li, X., Xie, Q., & Huang L. (in press). Identifying the development trends of emerging technologies using patent analysis and web news data mining: the case of perovskite solar cell technology. IEEE Transactions on Engineering Management. https://doi.org/10.1109/TEM.2019.2949124
- Ma, Z., Pant, G. & Sheng, O. R. L. (2011). Mining competitor relationships from online news: a network-based approach. Electronic Commerce Research and Applications, 10(4), 418-427. https://doi.org/10.1016/j.elerap.2010.11.006
- Malmquist, S. (1953). Index numbers and indifference surfaces. Trabajos de Estadistica Y de Investigacion Operativa, 4(2), 209-242. https://doi.org/10.1007/BF03006863
- Mikolov, T., Chen, K., Corrado, G. & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv , 1301.3781. https://arxiv.org/pdf/1301.3781.pdf?
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In C.J.C. Burges, L. Bottou, M. Welling, Z. Ghahramani & K. Q. Weinberger (Eds.), Proceedings of the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, Nevada, United States, December 5-8, 2013 (pp. 3111-3119). Curran Associates Inc. http://papers.nips.cc/paper/5021-distributed-representations-of-words-and-phrases-and-their-compositionality (Archived by the Internet Archive at https://bit.ly/3jRO7KC)
- Mnih, A. & Hinton, G. (2008). A scalable hierarchical distributed language model. In D. Koller, D. Schuurmans, Y. Bengio & L. Bottou, (Eds.), Proceedings of the 21st International Conference on Neural Information Processing Systems (pp. 1081-1088). Curran Associates Inc. https://papers.nips.cc/paper/3583-a-scalable-hierarchical-distributed-language-model (Archived by the Internet Archive at https://bit.ly/31EHiFe)
- Ong, T. H., Chen, H., Sung, W. K. & Zhu, B. (2005). Newsmap: a knowledge map for online news. Decision Support Systems, 39(4), 583-597. https://doi.org/10.1016/j.dss.2004.03.008
- Romer, P. M. (1994). The origins of endogenous growth. Journal of Economic Perspectives, 8(1), 3-22. https://doi.org/10.1257/jep.8.1.3
- Ruiz, E. J., Hristidis, V., Castillo, C., Gionis, A. & Jaimes, A. (2012). Correlating financial time series with micro-blogging activity. In Proceedings of the Fifth ACM International Conference on Web Search and Data Mining, Seattle Washington USA February, 2012 (pp. 513-522). Association for Computing Machinery. https://doi.org/10.1145/2124295.2124358
- Salton, G. & Buckley, C. (1988). Term-weighting approaches in automatic text retrieval. Information Processing & Management, 24(5), 513-523. https://doi.org/10.1016/0306-4573(88)90021-0
- Schumaker, R. P. & Chen, H. (2009). Textual analysis of stock market prediction using breaking financial news: the AZF in text system. ACM Transactions on Information Systems, 27(2), 12. https://doi.org/10.1145/1462198.1462204
- Simon, H. (1992). Lessons from Germany's midsize giants. Harvard Business Review, 70(March/April), 115-123. https://hbr.org/1992/03/lessons-from-germanys-midsize-giants
- Song, K., Kim, K. S., & Lee, S. (2017). Discovering new technology opportunities based on patents: text-mining and F-term analysis. Technovation, 60-61, 1-14. https://doi.org/10.1016/j.technovation.2017.03.001
- Sueyoshi, T. (1998). Privatization of Nippon Telegraph and Telephone: was it a good policy decision? European Journal of Operational Research, 107(1), 45-61. https://doi.org/10.1016/S0377-2217(96)00366-9
- Tseng, F.-M., Chiu, Y.-J., & Chen, J.-S. (2009). Measuring business performance in the high-tech manufacturing industry: a case study of Taiwan’s large-sized TFT-LCD panel companies. Omega, 37(3), 686-697. https://doi.org/10.1016/j.omega.2007.07.004
- Tseng, Y.-H., Lin, C.-J. & Lin, Y.-I. (2007). Text mining techniques for patent analysis. Information Processing & Management, 43(5), 1216-1247. https://doi.org/10.1016/j.ipm.2006.11.011
- Turian, J., Ratinov, L. & Bengio, Y. (2010). Word representations: a simple and general method for semi-supervised learning. In J. Hajič, S. Carberry, S. Clark, & J. Nivre, (Eds.). Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, Uppsala, Sweden, July 11-16, 2010 (pp. 384-394). Association for Computational Linguistics. https://www.aclweb.org/anthology/P10-1040 (Archived by the Internet Archive at https://bit.ly/39JAYP0)
- Wilson, T., Wiebe, J. & Hoffmann, P. (2005). Recognizing contextual polarity in phrase-level sentiment analysis. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, Vancouver, B.C., Canada, October 6-8, 2005 (pp. 347-354). Association for Computational Linguistics. https://www.aclweb.org/anthology/H05-1044.pdf
- Wong, W. P. & Wong, K. Y. (2007). Supply chain performance measurement system using DEA modeling. Industrial Management & Data Systems, 107(3), 361-381. https://doi.org/10.1108/02635570710734271
- Zhong, W., Yuan, W., Li, S. X. & Huang, Z. (2011). The performance evaluation of regional R&D investments in China: an application of DEA based on the first official China economic census data. Omega, 39(4), 447-455. https://doi.org/10.1016/j.omega.2010.09.004