Classification and information management for patent collections: a literature review and some research questions
Magali Rezende Gouvêa Meireles, Gabriela Ferraro and Shlomo Geva
Introduction
Detailed information about technology’s advance is required for decision-making processes concerning the amount of resources devoted to innovation, the selection of fields where innovation promises economic returns and the management of innovative strategies (Archibugi and Pianta, 1996). Camus and Brancaleon (2003) highlighted the importance of the information which decision-makers can find in patents analysis, revealing risks and opportunities and getting insight into the value of the companies’ innovation assets. Business and patents analysts, research and development planners, patent offices, economic organizations and industries with high scientific and technological activity have increased their interest in exploiting information embedded in patent databases. Indeed, it is precisely this opportunity to exploit knowledge that is embedded and revealed in patents that motivated the creation of all patent-awarding systems in the first place.
As a result of the discussion about the information embedded in patents, Lee, Yoon and Park (2009) stated that patents are comprehensive sources of technical and commercial knowledge. Because of this, the analysis of their technical and market attributes has been considered as a useful tool for research and development management. Some studies (Markellos et al., 2002; Leydesdorff, 2004) explore patent databases with a focus on how the knowledge base of the patents can be revealed, showing how the socially organized production of scientific knowledge is interfaced with the economy.
Great efforts have been made to make many patent collections available to users and to encourage research related to patents processing. Many proposals have been presented in the literature, discussing different approaches to the classification of patents based on content features, citation information and metadata. There are some issues in the patent management field, which are still open problems and can suggest possible research opportunities to solve some of the problems found by users. The objective of this paper is to present and investigate four patent classification problems in information management. In each one of these problems, we present some of the important related concepts and main points of discussion, giving an overview of the research related to the field. From these problems, we present four research questions, which can be used for future research, and suggest ways to deal with them.
This paper is intended for patent office professionals and researchers commencing projects in the general domain of patent document management, and specifically in information retrieval and applied machine learning. It also has an important audience in all technological industries that use patent registration systems. Exploring contemporary discussions about patent classification processes available in the literature of journals, workshops and conferences, this paper aims to identify some of the main issues of the field and some of the open research areas for information retrieval communities, and finally to suggest ways to solve some of the problems discussed.
The remainder of this paper is organized as follows. The first four sections present and discuss the identified problems:
- Problem I: Patents are complex documents, which have the language and formatting regulated by the laws of the patenting authority in which the patent application is filed.
- Problem II: There is not a common classification system used by patent offices.
- Problem III: It is difficult to evaluate the proposed automatic classification systems found in the literature because of scalability issues.
- Problem IV: There is no agreement about the best attribute to use in the patent classification process.
The discussion and conclusions are presented in the final sections.
Problem I: Patents are complex documents, which have the language and formatting regulated by the laws of the patenting authority where the patent application is filed
A patent is a contract between an inventor and a government, whereby in return for full public disclosure of an invention, the government grants the inventor the right to exclude others for a limited time from making, using or selling the invention (Hufker and Alpert, 1994).
Patents are complex legal documents, which contain more details and more exhaustive descriptions than scientific papers (Alberts et al. 2011). Laws and regulations of the country or patenting authority in which a patent application is filed control the language and formatting of the patent text. A patent document consists of several sections, including bibliographic data (author, inventor, country, applicant, owner, patent classification codes, publication date), title, abstract, claims and a main body or description of the invention. While some of the sections are fully structured, for example, the bibliographic data, others, such as the description and claims sections, are unstructured items that contain mainly free text (Tseng, Lin and Lin, 2007).
To be eligible for patent protection a product must meet three criteria: novelty, non-obviousness and utility. To meet the novelty criterion, the invention must be new and different from the prior art (past inventions) and to be considered non-obvious, the invention cannot have been anticipated by the prior art. The utility criterion is met if the invention is useful to society (Hufker and Alpert, 1994). In order to accomplish these criteria, a patentability search is usually conducted before writing a patent application. The relevant prior art coverage should include not only patent publications, but also books, refereed journal articles, press releases, brochures, white papers, Websites, conference materials, theses and dissertations, technical disclosures and defensive filings.
It is also known that patents are difficult to read and comprehend, not only because they usually contain highly specialized technical descriptions, but also because legal terms are used to define the scope of the invention. Hence, writing a patent application, reading an existing patent or mining a patent collection is a big challenge. Barriers such as complexity, the slow pace and the high cost involved are aspects that justify researchers’ choice to publish, rather than directly realize, patent applications. Shelton and Leydesdorff (2012) developed statistical regression models to relate funding and spending components, as inputs, to two indicators of scientific research, papers and patents, as outputs. In their analysis, they presented input indicators that seemed to most encourage papers and patents and they assumed that those relations are ‘nationally integrated into systems with a strong historical component’. They concluded that government funding and higher education spending are more effective in encouraging publication than patent application. In the industrial funding sector, there is an incentive to patent for proprietary reasons or to produce prototypes or products. These conclusions are not surprising, but the model provides quantitative support to issues related to funding strategies. Despite efforts to disseminate the process of patenting in research centres and universities, there is a great lack of knowledge among researchers regarding the issue of intellectual property. Here there is evidence that the justification may be associated with financing strategies.
Even considering that knowledge encoded in patent documents and patent collections is complex and challenging, patents are understood as technological advance indicators taking into account advantages and disadvantages of having them as a variable to model this process. As advantages, Archibugi and Pianta (1996) state that patents are public documents and it is expected that the applications provide benefits that outweigh the cost and the time-consuming effort of obtaining patent protection. They capture the proprietary and competitive dimension of technological change because they are a direct outcome of the inventive process and it is possible to obtain information not only on the rate of inventive activity, but also on its direction. As disadvantages, it is important to state that not all inventions are technically patentable and not all researchers want to patent their inventions. It depends on the interest in exploiting their inventions commercially in the domestic market and in foreign countries. Each national patent office has its own institutional characteristics, which affect the costs, length and effectiveness of the protection accorded. As a variable of the model that analyses the technological advance of a specific knowledge area, it is important to understand the four different measures that have been used to evaluate the individual value and the impact generated by a patent (Archibugi and Pianta, 1996):
- Patent citations: the count of citations of a patent in subsequent patent literature is an indicator of the technological impact of the invention;
- Renewal fees: the total cost and the number of years for which the patentee pays renewal fees to maintain the legal protection value of the patent give information on the economic value attributed to the invention. According to Pakes and Simpson (1989), assuming that renewal decisions are based on economic criteria, agents will renew their patents only if the value of holding them an additional year exceeds the cost of renewal;
- Patent families: the number of countries to which a patent application has been extended shows the areas of exploitation of an invention;
- Patent claims: the number of claims in each patent gives information on the range of novelties in the patent document. According to Tong and Frame (1994), the units of inventiveness are measured by patent claims. Each claim represents a distinct inventive contribution, so patents are, in effect, bundles of inventions.
Figure 1 summarizes patenting as part of an innovative activity. Researchers and firms in different sectors and countries realize the patenting process to register their inventions. From these activities, it is possible to infer new sources of innovation, the structures of innovative processes and the impact of innovation on society, by analysing the four indicators, above discussed, found in the patenting process.
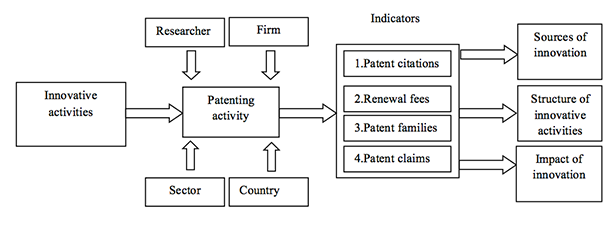
Therefore, patents contain research outcomes that are valuable to the industry, business trends and novel industry solutions (Tseng, Lin and Lin, 2007). This leads us to postulate research question I:
Research question I: Is the knowledge embedded in patents accessible to inventors and other patent users, making it possible to identify technological advance of specific domains of knowledge?
Problem II: There is no common classification system used by patent offices
The lack of a common classification system is a major problem because it is difficult to standardize and to improve access across patent offices around the world. The purpose of a patent classification system is to organize patent collections according to their technical application, structural features, intended use or the resulting product produced by a process (Alberts et al., 2011). According Benzineb and Guyot (2011), patent classifications, as taxonomies, generally come in the form of a hierarchy of categories. The top level includes broad categories of inventions, as general and open as possible, since they have to describe the world and must be able to include all objects and ideas. The second level includes more narrow categories. As the taxonomy levels go deeper, the number of categories grows and they are described with more details.
The goal of the patent classification codes is to assist the patent applicants and patent offices to classify and further retrieve their patents. Users of patent classification systems are not only patent practitioners, such as inventors or lawyers, but also organizations working in technology monitoring, economic intelligence and business intelligence, among others. In what follows, we present the most relevant patent classification systems currently available.
The International patent classification is built and maintained by the World Intellectual Property organization and divides all areas of technology into eight sections (A-H), subdivided by notations for class, subclass, group and over 60,000 subgroups. The classification system was originally updated at five-year intervals and with the eighth edition all patents in the database were reclassified (Alberts et al., 2011). Over 100 patent-issuing bodies use the International patent classification, making it the most widely used patent classification system (Harris, Arens and Srinivasan, 2010).
The United States patent classification, established by the United States Patent and Trademark Office, consists of a three-digit class definition, arranged numerically and new classes are created as new technologies emerge. Each class code is followed by a hierarchy of numerical subclasses (Alberts et al., 2011). This system classifies patents into at least one of approximately 470 classes and 163,000 subclasses (Harris, Arens and Srinivasan, 2010). In January 2013, the United States Patent and Trademark Office replaced the United States patent classificationsystem with the Cooperative Patent Classification (CPC). According to Hufker and Alpert (1994), the United States patent system differentiates between three general classifications of patents: utility patents, design patents and plant patents. There are five classes of subject matter eligible for a utility patent: a process, a machine, a manufacturing item, a composition of matter and an improvement of any of the above classes that produces a useful result. This kind of patent is granted for a term of seventeen years. The design patent offers protection for any new, original and ornamental design for a manufacturing item. The shape is the main factor for a manufacturing item to be considered patentable. Attributes such as mechanical utility, functionality, or manner and size in which the item is made are less relevant for this kind of patent. Design patents are issued for a term of three and a half, seven or fourteen years. Plant patents protect the invention of distinct plants developed through biotechnology that are not found in nature.
According to Leydesdorff (2004), the United States Patent and Trademark Office database is often used in scientometric research for comparative purposes, because it standardizes the presence of other nations in a single representation. This database includes information about all United States patents from the first patent issued in 1790 to the most recent issue week. The display of each patent's full-text includes a hyperlink to obtain full-page images of each page of the patent. Patents from 1790 to December 1975 offer only the patent number, issue date and current United States patent classificationin the text display, and can be searched only within those fields. However, this limited text display also includes a hyperlink to obtain full-page images of all pages of the patent. The information contained in the patents is arranged in a number of data fields that can be accessed in the freely available portals provided by patent authorities or by commercially available search engines (Alberts et al., 2011). The fields are generally represented in an XML structure.
The European patent classification is built and maintained by the European Patent Office. This system is a more precise variant of the International patent classification and has about 129,000 categories. According to Benzineb and Guyot (2011), while the International patent classification seems to be more oriented toward the publication of patents, the European patent classification is more focused on supporting patent information search in the context of a patent application.
The Japan Patent Office uses the File index classification in parallel with the International patent classification system to classify all Japanese patents. The File index classification is an extension of the International patent classification, having 170,000 classes (Schellner, 2002). The Japan Patent Office uses supplementary indexing terms, called F-terms (file forming terms) classification, which is an independent classification, with more than 2,500 themes. The F-term classification works from different viewpoints, e.g., material, operation, product and purpose. According to Schellner (2002), experts assign a patent to F-terms following two steps. The first is to determine themes and the second one is F-term assignment for each theme.
The Cooperative patent classification is a joint partnership between the United States Patent and Trademark Office and the European Patent Office, with the goal of harmonizing their existing classification schemes (United States patent classification and European patent classification and finding a common classification scheme. It is largely based on the European patent classification formerly used at the European Patent Office. The Cooperative patent classification includes approximately 250,000 classification symbols based on the International patent classification.
According to the United States Patent and Trademark Office Website, the Korean Intellectual Property Office will classify some of its patent documents using the Cooperative patent classification. For the pilot, the Korean Intellectual Property Office will apply the Cooperative patent classification codes to patent documents in particular technologies.
The State Intellectual Property Office of the People’s Republic of China, also known as the Chinese Patent Office, started to classify new patent applications in the Cooperative patent classification for some technical fields. It is expected that these initiatives will improve access to the Chinese patent documentation, improve the search efficiency and overcome language barriers. In 2016 all patents applications from the State Intellectual Property Office of the People’s Republic of China should be classified by the Cooperative patent classification.
According to the European Patent Office, the Cooperative patent classification is already used by more than forty-five patent offices worldwide as a means to perform efficient prior art searching during the patent granting process.
Each of the classification systems described was developed with a different underlying philosophy, which is reflected in the classification system design. With more than double the number of unique classification codes, the United States patent classification has a far tighter focus compared with the International patent classification. In terms of depth of classification, the United States patent classificationusually gives more precise information on the invention’s true purpose. The International patent classification classifies an invention according to its function whereas the United States patent classification not only classifies based on the function but also on the industry, anticipated use, intended effect, outcome and structure. Therefore, the categorisation of United States patent classificationis more elaborate than the International patent classification and, because of this, can be more challenging to search (Harris, Arens and Srinivasan, 2010).
According to Harris, Arens and Srinivasan (2011), the European patent classification system is often used for searching patents issued by European patent-issuing offices. More than twenty-eight million documents can be searched using European patent classification symbols, sometimes dating back to 1836, making it more versatile than the International patent classification. The International patent classification system does not cover documents published prior to 1968. On the other hand, more than thirty-seven million documents are classified with International patent classification symbols, making the International patent classification documentation the largest available classified collection of patent documents.
Additionally, since the European patent classification contains nearly 133,000 entries, nearly twice as many entries as in the International patent classification, a higher relative precision in the scope definition for a specific entry can be expected using European patent classification symbols than with International patent classificationsymbols. The European patent classification is updated monthly and the International patent classification is updated annually, allowing European patent classificationcodes to follow the evolution of technology more effectively.
Since hundreds of patent applications reach patent offices around the world every day, manually assigned classification codes are very costly, not only because of the number of patent applications, but also because experts are required. Thus, automatic or semi-automatic patent classification codes assignments have been proposed. The automatic classification code assignment is the process by which a computer program suggests or assigns one or several classification codes to a patent on the basis of the patent’s content. Automatic classification code assignment systems have the advantage of being faster and more systematic than the human based process and they are applied, mainly, to the following tasks (Benzineb and Guyot, 2011):
- Pre-classification: the task of automating the distribution of incoming patent applications among various possible groups of examiners. As pointed out by Benzineb and Guyot (2011), this task is simpler since the number of groups of experts is generally less than 100 (much less than the number of the patent classification categories). These systems usually compute a confidence score for each code assignment.
- Interactive classification: intended to help patent applicant and examiners to classify a patent application.
- Re-classification: the process by which patent categories are grouped together into larger ones, or broken down into smaller ones, as well as the subsequent process of re-tagging the patents classified under the modified categories.
- Prior art search: particularly useful for assisting patent examiners in their prior art search and does not depend on classification codes.
The second research question is:
Research question II: What is missed by the current patent classification and search used by patent offices?
Problem III: It is difficult to evaluate the existing automatic patent classification systems found in the literature because of scalability issues
In the last decade, several shared tasks and workshops have been organized with the aim of encouraging research related to patents processing and with the aim of establishing benchmark activities for this field. The tasks organized by these initiatives are mainly focused on patent retrieval challenges and present data sets that have been released to the scientific community. Those collections, available for experimental purposes, could be used as corpora by the academic community and private sector. In what follows, we present the available patent collections for automatic patent classification, as well as the tasks which they are used for.
Since 2002, the NII Test Collection for Information Retrieval Systems Workshops have encouraged research related to patent retrieval and mining by providing big collections of patent documents. In the fifth iteration of the workshop (Fujii, Iwayama and Kando, 2005), they launched two tasks related to patent classification into the F-term classification system, which were:
- Theme categorisation: participants were asked to return a ranked list of 100 themes for each patent;
- F-term categorisation: participants were asked to return a ranked list of 200 F-terms from a set of patents whose themes were given.
The seventh and eighth iterations of the workshop included a patent mining task (Nanba, Iwayama, Fujii and Hashimoto,2008), which aimed to classify scientific papers into the International patent classification system. According to Nanba et al., classifying research papers into patent classification systems enables an exhaustive and effective invalidity search, prior art search and technical trend analysis. This task, which can be considered as a cross-genre text classification problem, was further subdivided into the following subtasks:
- Japanese task: classification of Japanese research papers using patent data written in Japanese;
- English task: classification of English research papers using patent data written in English;
- Cross-lingual task: classification of Japanese research papers using patent data written in English;
- Cross-lingual task: classification of English research papers using patent data written in Japanese.
In late 2002, the World Intellectual Property organization released the first version of two collections of patents manually classified using the International patent classificationsystem (Fall, Törcsvári, Benzineb and Karetka, 2003). Table 1 presents the WIPO-alpha and WIPO-de collections. The idea behind this initiative is to promote research into automatic patent categorisation in the International patent classificationsystem, within the academic community as well as in the private sector. These data sets are part of the Classification Automated Information System (CLAIMS) project, which also provides categorisation assistance and enhances the search ability of patent information. Another initiative to encourage research on patent material was the Workshop on Patent Information Retrieval (PAIR), which was held yearly from 2008 to 2011. The aim of this workshop was to encourage collaboration between the intellectual property and information retrieval communities.
In 2009, the Cross-Language Evaluation Intelllectual Property (CLEF-IP) Forum (Roda, Tait, Piroi and Zenz, 2009) track was launched to investigate information retrieval techniques for patent retrieval. Table 1 presents the released data sets. In 2010, the CLEF-IP (Piroi and Tait, 2010) included a sub-track about patent classification into the International patent classification system at the section, class and subclass levels. In 2011 (Piroi, Lupu, Hanbury and Zenz, 2011), a more difficult task was included about classifying a patent of a given subclass level into group and subgroup classification levels. Also in 2009, the Text Retrieval Conference (TREC) launched TREC-CHEM (Lupu, Huang, Zhu and Tait, 2009), a shared task with the aim of investigating domain specific information retrieval methods. The goal of the chemistry track was to develop and evaluate information retrieval technologies that deal with academic papers and patents about chemistry. The tasks were:
- Prior art search, which searched for patent documents that were likely to constitute prior art to a given patent application;
- Technical survey, which searched for all the relevant documents given in a topic.
Table 1 presents a summary of patent collections available for experimental purposes in workshops. These databases are used as corpora to develop tasks related to automatic patent classification. For each collection, the table shows the number of patents available, the language used in the documents, the patent offices where the patents were published and the period of publication. This is important to show the existing diversity and lack of standardisation in the field around the world.
| Collections | Number of patents | Document language | Patent offices | Publication period |
|---|---|---|---|---|
| TREC-CHEM 2007 | 2,600,000 | English | EPO, USPTO and WIPO | Until 2007 |
| WIPO alpha | 75,000 | English | WIPO | 2003 |
| WIPO-de | 110,000 | German | WIPO | 2003 |
| CLEF-IP 2010, 2011 | 2,600,000 | English, German and French | EPO | Until 2002 |
| NTCIR 5th, 7th and 8th iterations | 3,500,000 | Japanese patent applications | JPO | 1993-2002 |
| 990,000 | English | USPTO | 1993-2000 | |
| 3,500,000 | English (Patent abstracts from Japan translated into English) | JPO | 1993-2002 | |
| 260,000 | Abstracts of research papers in Japanese and English | JPO | 1988-1999 |
According to Sebastiani (2002), the evaluation of document classifiers is typically conducted experimentally, rather than analytically. Evaluation campaigns such as the ones mentioned in this section allow researchers to test the effectiveness of their methods, that is, their ability to take the right classification decisions, and thus, to know how well they are able to perform the task. Furthermore, the method efficiency can also be evaluated, for example, verifying how reliable, fast and costly it is to apply a method to solve a particular task.
The following sections review scientific papers related to automatic patent classification. Some of them use the datasets presented in this section.
The third research question is:
Research question III: How is it possible to classify documents as patents, minimizing the influence of scalability issues?
Problem IV: There is no agreement about the best attributes to use in patent classification processes
There is no agreement in the literature about the best attributes to use in patent classification. According to Liu and Shih (2011), a considerable number of patent-classification schemes have been proposed in recent years and they can be divided according to the patent documents’ features used for classification purposes. These three groups are content features, citation information and metadata. The following subsections discuss these groups.
Automatic patent classification using content features
Before proceeding further, two pre-classification tools must be introduced which are currently used in production systems. The World Intellectual Property organization offers the 'categorisation assistant' in the International patent classification), which is a computer-assisted patent classification system. The aim of the 'assistant' is to facilitate the attribution of International patent classificationcodes to patent applications written in English. The aim is, especially, to assist small patent offices and to promote the use of the International patent classification. The OWAKE tool is a pre-classification assistance tool, in production at the Japanese Intellectual Property Cooperation Centre (IPCC), an institution affiliated with the Japan Patent Office. The tool is able to assign Japanese F-Term symbols and International patent classification codes to a given patent application It makes use of the full text of the patent and extracts keywords from the document based on an extensive customized Japanese dictionary (Fall et al., 2003).
When dealing with patent classification according to the F-term system, the best results were obtained by applying machine learning classifiers such as Support Vector Machines (SVM) (Li, Bontcheva and Cunningham, 2007), Naïve Bayes (NB) (Tashiro, Rikitoku and Nakagawa, 2005), K-nearest neighbours (KNN) (Kim, Huang, Jung and Choi, 2005); and logistic regression models (Fujino and Isozaki, 2008), among others. Support Vector Machines are based on geometric principles and Naïve Bayes is based purely on probabilistic principles. In the k-nearest neighbours clustering algorithm, a cluster is formed around every input instance. For input instance x, the k points that are nearest to x according to some distance metric and x itself form a cluster (Croft, Metzler and Strohman, 2010). Logistic regression model is a type of probabilistic statistical classification classifier.
The best scores reported are from Li, Chen, Zhang and Li (2007), who proposed a Support Vector Machine classifier that used features from full patents as well as features from F-term descriptions. Others, such as Hashimoto and Yukawa (2007), used the Chi-squared statistic weighting as a term weighting classification method to solve the F-term classification tasks from the sixth iteration of the NII Test Collection for Information Retrieval Systems Workshop. Chi-squared weighting is applied to each bi-gram of each F-term. For each test document, the Chi-squared weights of F-terms that appear in the abstract and/or claims are summed and, finally, documents are sorted in descending order. These systems achieve reasonable performance, are fast and do not require training, but the results are not quite as good as those from systems that used machine learning approaches.
When dealing with classifying patents in the International patent classification system, several classification algorithms have been used. Fall et al. (2003) tested the effectiveness of three classifiers (Naïve Bayes, K-nearest neighbours and Support Vector Machines) for classification of the alpha collection. They achieved the best performance using features from the first 300 words from the title, inventors, applicants, abstract and description sections in comparison with using only the title or the claims. They concluded that Support Vector Machines outperformed Naïve Bayes and K-nearest neighbours for the classification at class and subclass levels.
Mathiassen and Ortiz-Arroyo (2006) proposed an ensemble classifier, which combines neural networks and linear least square fit classifiers, and a voting approach to classify patents in a reduced version of the WIPO-alpha collection. The best performance was obtained when documents were indexed using the title, the first 200 words from the abstract and claims and the first 400 words from the description, and weighted using normalized term frequency. The title was further weighted five times more than the other sections. Then the authors applied a feature reduction step where only 500 features per main class were selected.
According to Benzineb and Guyot (2011), only a part of the patent content should be used to feed an automated classifier. Some data have a higher classifying power. The inventor’s name is one of them because inventors tend to concentrate their inventions in a specific field. The classifier often has a higher accuracy when trained on the abstract than on the claims section. The words in the claims section tend to be ambiguous to cover the widest possible application area. Bibliography, inventor and applicant names, title and abstract are the preferable fields as training material for the classification process.
Koster and Beney (2009) investigated the impact of using syntactic phrases in contrast to the bag of words model for patent classification. Using the abstracts from a small subset of the CLEF-IP 2010 data sets, they demonstrated that better results were obtained when a combination of syntactic phrases and bag of words are used as document representation. They used 73,869 documents in thirteen International patent classification R subclasses, in English and French. Their approach has been tested with Winnow (Littlestone, 1988) and Support Vector Machines classifiers.
The classification of research papers into a patent classification system is useful for invalidity search, prior art search and technical trend analysis, among others uses. The main challenges in these tasks are to cope with the differences between two different genres (research papers and patents) and/or two languages (English and Japanese). So far, the best results were obtained by using a K-nearest neighbour-based method from Xiao et al (2008). This method operates in two stages. In the first stage, a K-nearest neighbour classifier assigns to each patent a ranked list of International patent classification codes by calculating the similarity between an input document (a research paper) and a document in the training set (a patent document). In the second stage, another K-nearest neighbour classifier is used to sort the ranked list.
The most effective ranking method was the one that combines BM25+listweak (Robertson and Jones, 1988). When dealing with the 2008 NII Test Collection for Information Retrieval Systems Workshop cross-lingual task (classification of Japanese research papers using patent data written in English and vice-versa), Bian and Teng (2008) achieved similar performance results as in monolingual classification. In Bian and Teng’s (2008) system, the queries were translated to English or Japanese, using three possible online Web translation systems (Excite, Google, Yahoo!).
Another interesting approach was proposed by Nanba and Takezawa (2009), which deals with the cross-lingual and cross-genre tasks. In order to overcome the differences between the terms used in research papers and patents, they proposed using two translation models. They translated document i in language L2 using a translation model for genre G1 and a translation model for genre G2, and then, classified document i into a classification system. They demonstrated that the method that combines two translation models from different genres outperforms the methods that use only one translation model.
Automatic patent classification using citation information
Citation analysis is the most popular approach in the field of bibliometrics. It can be used to identify relationships between documents regardless of the presence of equal terms in the evaluated documents (Borgman and Furner, 2002). In bibliometrics, bibliographic coupling and co-citation are examples of ways to assess document similarities, as shown by Figure 2. For bibliographic coupling, citing documents are the subject for analysis. The degree of bibliographic coupling for documents A and B is reflected in the number of documents that are cited by both A and B. The focus of co-citation analysis is on the cited documents, by calculating the number of documents that cite both C and D (Lai and Wu, 2005).
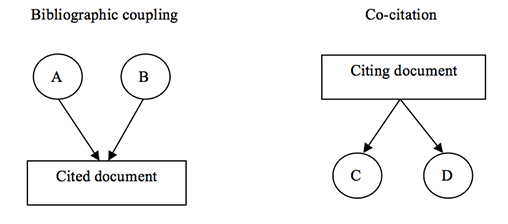
According to Hjorland (2008), bibliographic coupling was introduced by Kessler in 1963, and co-citation analysis was suggested independently by Marshakova and Small in 1973. Kessler (1963), in his experiments, found a high degree of logical correlation between the papers grouped using bibliographic coupling criteria. Marshakova (1973) conceived of co-citation as the logical opposite of bibliographic coupling. Small (1973) concluded that through the study of the structures created, co-citation provides a tool for monitoring the development of scientific fields and for assessing the degree of interrelationships among specialties.
The habit of citing gives conformity and consistency to the act of intellectual production, often governed by tacit and internalized norms (Cronin, 1984). Statements cited in the text gain credibility when this text informs sources that support it, connecting the reader to other sources of information on that subject. Citations denote a special relationship between the citing and the cited papers and it is possible to identify, by the author’s considerations, his previous experience in that subject and his network of knowledge.
At least one specific type of relationship among patents can be determined by citation analysis. If a patent is cited by a large number of other patents then this cited patent is possibly a foundation for those citing patents (Fujii, Iwayama and Kando,2007). Patent citations have been considered from different perspectives, from the mapping of their market value, legal status and the knowledge base (Leydesdorff, 2008). Figure 3 shows how the knowledge embedded in patents can flow between organizations, the civilian sector and industry, in both directions. By analysing the cited and citing patents related to a given patent, it is possible to identify the flow of knowledge between companies and their environment (Chakrabarti, Dror and Eakabuse, 1993).
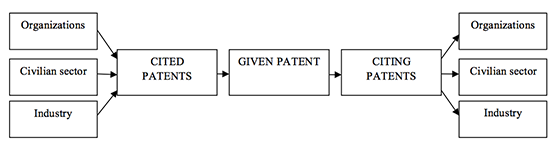
The papers presented in the following section discuss the application of citation analysis to organize patent databases, highlighting how patents can be grouped in the same category using patent citations as connections between patents. A patent database, such as the United States Patent and Trademark Office database, allows for retrieval of citation patterns in terms of both the previous patents cited and the scientific literature cited (Leydesdorff,2004).
Lai and Wu (2005) proposed an approach to create a patent classification system to replace the International patent classification or United States patent classificationsystem to assist patent managers in understanding the basic patents for a specific industry and the evolution of the related technology field. The approach is based on co-citation analysis. The process is divided into three phases. Phase I selects the appropriate database. Phase II uses the frequency of co-citations of the basic patent pairs to assess their similarity. Phase III uses factor analysis to establish a classification system. The basic purpose of citing prior art in patent files is to inform that such patents and publications exist and should be considered when evaluating the validity of the patent claims. The authors suggest that the problems with the use of citation analysis are less for patents than for academic papers, because patent applicants and examiners are more cautious with citations, which have an important role in patent definitions and directly influence a patent’s economic value. To validate their proposal, the authors used patents from four companies, TSMC, UMC, IBM and Chartered, which were expected to be related to semiconductor technologies. They selected 8,967 patents to be classified, which had cited 36,795 other patents. The authors developed a patent classification system to assist patent managers in understanding the basic patents for a specific industry, the relationships among categories of technologies and their evolution.
They adopted a kernel-based approach to capture content information and citation-related information in patents, and the results showed that their proposal outperformed the kernels that did not use citation network structures. They evaluated 4,358 patents in the test dataset and 227,833 in citation network patents from the United States Patent and Trademark Office related to nanotechnology.
Liu and Shih (2011) combined content-based, citation-based and metadata-based classification methods to develop a hybrid-classification approach using a modified K-nearest neighbours algorithm. The authors evaluated the performance of the method on a dataset containing 1,231 patent documents from five United States patent classification classes (metal working, active solid-state devices, electricity, semiconductor device manufacturing process, and electrical computers and digital processing systems) obtained from the United States Patent and Trademark Office and compared its performance with those of three conventional methods. The results demonstrated that their proposal yielded more accurate class predictions than the patent network-based approach.
Some authors have used patent citation analysis for other purposes. Patent citations have been recognized as a source of data for the study of innovation and technical change (Trajtenberg, 1990; Chakrabarti, Dror and Eakabuse, 1993; Engelsman and Van Raan, 1994; Hall, Jaffe and Trajtenberg, 2002) and for measuring their economic value (Sapsalis, Van Pottelsberghe de la Potterie and Navon, 2006).
Automatic patent classification using metadata
Richter and MacFarlane (2005) described the investigation of the usefulness of metadata for automatic classification of patents. In the case of textual data, common types of metadata would be the author, the publication date, author affiliation and keywords. According to these authors, considering the linguistic level, an important difference between textual data and metadata is the fact that ‘’. They state that even patents that are not very rich in metadata can be used as indicators to define the content of a patent. They believe that because companies, as well as specific inventor teams, tend to file series of applications for inventions closely related to each other, inventor names and applicant names carry a lot of meaning about the content of the documents. In their experiments, they considered three attributes: International patent classificationcodes, inventors and applicants names, these last two used as a single attribute. The automatic classification was performed with the K-nearest neighbours classifier and the algorithm was implemented in a relational database that contained more than 40,000 manually classified patent records, including the Patent Cooperation Treaty applications published in the years 2001 and 2002 in the subjects of pharmaceuticals and biotechnology.
Kim, Suh and Park (2008) collected keywords from patent documents of a target technology field and clustered them using the k-means algorithm. They used the clustering results to form a semantic network of keywords to establish a patent map that considers structured and unstructured items of a patent document. The goal of their approach is to understand, by analysing the patent map, advances of emerging technologies and to forecast future trends.
Lee, Yoon and Park (2009) used keyword-based patent maps for use in new technology creation activity. First, they used text mining to transform patent documents into structured data to identify keyword vectors. Second, principal component analysis was employed to reduce the numbers of keyword vectors, to make it suitable for use on a two-dimensional map. Third, they identified large areas in the map that are sparse in patent density, which could be potential fields for new technology creation. They used 141 patents related to personal digital assistant technologies from the United States Patent and Trademark Office database covering the period 1996 to 2003.
Patent search using existing classifications
This section focuses on the use of patent classification codes for patent retrieval and how this helps in the search process. In the context of patent search, classification systems have been used mainly for retrieval filtering (Lopez and Romary, 2009; Magdy, 2012) and for ranking in prior art search (Verma and Varma, 2011; Harris, Foster, Arens and Srinivasan, 2009; Harris, Arens and Srinivasan, 2010), where only documents which shared the top classification levels (usually the top three levels) are retained as candidates for prior art and the others are discarded.
Harris, Arens and Srinivasan (2011) measured the impact of using International patent classificationcodes to re-rank patents retrieved using a keyword search. Using the TREC-Chem'09 dataset, the authors demonstrated that the use of classification had a positive impact in assessing relevant patents. Based on the hypothesis that more specific parts of the International patent classificationsystem are more relevant for patent retrieval, they used different weights for class and group parts of the codes. They concluded that there is no significant improvement when using the weighting method. Furthermore, they examined the impact of using only primary classification code versus all codes and observed that although there is an improvement over the baseline, the improvement is larger when all classification codes are used.
Mahdabi, Gerani, Huang and Crestani (2013) proposed a query expansion method using definitions of the International patent classification system for prior art search. They expanded the queries by selecting terms from the definitions that are closer to the query terms, since they are more likely to be related to the query topic. Using CLEF-IP 2010 and CLEF-IP 2011 datasets, they concluded that their expansion method is more effective than standard pseudo relevance feedback.
For patent retrieval, Fujii (2007) combined text-based and citation-based retrieval methods to search patents, using the United States Patent and Trademark Office database to validate his proposal. Fujii used 981,948 patent claims published from 1993 to 2000 to perform word-based indexing and 2,221 patents published between 2000 and 2001 as search topics.
Tian, Zhiping and Zhengyin (2013) developed a patent search system based on domain knowledge organization systems, which can be applied to a patent retrieval system to assist product managers and designers to acquire technology information from patents. The main process includes patent preparation, technical feature extraction and building the knowledge system. They proposed to use the patent’s abstract and claim sections to automatically extract technology terms to be used in the construction of a domain knowledge organization system, which is corrected by an expert.
The fourth research question is:
Research question IV: Are the current patent processing technologies discussed in the literature exploring and exploiting the richness of a patent document?
Discussion
Problem I: Patents are seen as complex documents and the research question here formulated focuses on the accessibility of the knowledge embedded in patents and whether it is possible for inventors and users to identify technological advances in specific domains of knowledge.
Patents documents can provide valuable research results to industry, business, law and policy-making communities. Using indicators such as patent citations, renewal fees, patent families and patent claims, it is possible to evaluate the individual value and impact generated by a patent in a specific domain of knowledge. But unless the information is readily available, this system does not work for the benefit of society. Patents are complex legal documents with technical details and exhaustive descriptions. Beside this, the language and formatting of patent texts are controlled by laws and regulations of the country or the patenting authority in which the patent application is filed. It is often difficult to understand a patent without the context of technological and scientific advances that it is extending. Patent documents, other than by some references, do not assist in gaining access to such information. An alternative would be to incorporate cutting-edge technologies from information retrieval research, linking individual patent documents to related patent documents (inter-linking) and to external collections such as Wikipedia and PubMed, and in general to the scholarly literature in the relevant respective domain.
Gnoli (2008) highlighted that a lot of information is available in searchable online databases, but this does not guarantee that knowledge is well organized and exploitable. Often, knowledge organization experts develop and improve sophisticated systems and the bulk of actual information sources do not use them, showing that the first need is for greater integration and communication between indexers, computer scientists and information architects.
Problem II: There is no common classification system used by patent offices.
Here, it was asked what is missing from the current automatic patent classification and search used by patent offices.
Patent classification follows complex rules that are described by each classification system and by particular documents from a patent office. The complexity starts with the documents, which have specialized technical descriptions and legal terms used to define the invention. Each office has its own methodology for choosing the most important features by which to classify the documents.
The main difference between automatic and human patent classification is that, usually, humans rely on legal knowledge and on the examiners’ interpretation of a patent; whereas automatic classification is based on shallow text processing techniques such as word usage statistics and similarity. This difference can lead to a disagreement in the codes suggested for a patent application. A possibility for improving automatic systems would be to specialize them according to the patent technology field. Then, a supervisor could choose appropriate technologies for each subject. Machine learning algorithms are the preferred approach to solve the patent classification task. There are several algorithms that automatically classify documents, such as Naïve Bays, which is based purely on probabilistic principles, and Support Vector Machines, based on geometric principles. Even though several algorithms and document representation approaches have been tested, there is still disagreement about which is the best document representation for patent classification. Most classification tasks are evaluated using standard information retrieval metrics, such as accuracy, precision, recall, the F measure and ROC curve analysis. Nevertheless, fair comparisons are not always feasible, since there is no agreement on the evaluation metrics, which make the comparison difficult and not straightforward.
Problem III: It is hard to evaluate the existing automatic classification systems found in the literature because of scalability issues.
We asked how it would be possible to minimize the influence of scalability.
Many unsupervised approaches are found in the literature, proposing automatic classification systems. The samples used to validate those approaches are smaller than databases found in patent offices such as the United States Patent and Trademark Office. A comprehensive approach to automatically classifying the entire set of patents available in patent offices has not been reported so far. It is difficult to evaluate if such an approach could really work well because of scalability issues. This presents an opportunity for future research, perhaps in one of the evaluation forums. It will require significant assistance from patent offices, because the evaluation of automatically generated classifications requires expert validation. This makes such validation more difficult and more expensive to carry out. Furthermore, it would be very interesting to evaluate the result of re-classification of historically classified patents. Such an evaluation may shed light on the quality/accuracy of existing classification codes of patents, and on the impact of technological change and evolution on the patent taxonomy. It stands to reason that, over time, class boundaries may considerably shift. If that were the case, then it would mean that historical classification examples might not be suitable for learning or for evaluating new classification systems.
Most patent classification approaches deal with classifying patent applications at the upper levels of classification hierarchies (class and subclass levels) and only a few have tracked the problem on a more fine-grained classification (group and subgroup levels). This problem may be related to scalability difficulties of clustering and classification systems that tend to struggle with full collection scale (with tens to hundreds of millions of documents) and with fine granularity clustering (into hundreds of thousands of classes). This offers another avenue of research. It has been shown, especially after CLEF-IP 2009, that classification codes in queries are useful for improving recalls of a retrieval system. It would be interesting to see the impact of using codes below the subclass level, not only for improving retrieval but also to allow for precision and/or ranking improvements.
Problem IV: There is no agreement about the best attribute to use in the patent classification process.
We ask if the current patents processing technologies discussed in the literature explore and exploit the richness of a patent document.
The automatic patent classification systems discussed here were divided according to patent documents’ features used for classification purposes. These features are based on content, citation information and metadata. The first group of papers discussed systems based on content features. There are several classification algorithms available. The second group of papers discussed systems based on citation analysis. The authors used different subjects, amounts and algorithms to present their approach. They all proposed techniques based on co-citation or citation networks, using data from patents databases, such as the United States Patent and Trademark Office database. Those databases allow the retrieval of previous patents and cited scientific literature. This is a strong approach that can be explored to find related patents, as an alternative to methods that use common words to evaluate similarity between documents. The third group of papers used metadata to classify patents. Although some authors (Richter and MacFarlane, 2005) have argued that much of the metadata is not expressive, there are a lot of researchable fields that can be explored here.
Citation analysis relies on the existence of bibliographic coupling and co-citation and does not use words as units of knowledge representation. It seeks other layers of knowledge to establish relationships between documents. However, this is limited by several practical constraints. Often the authors of documents are not aware of potentially relevant coupling and may even deliberately omit bibliographic coupling. Furthermore, citations appear chronologically and older patents cannot possibly contain citations of newer patents. Patents documents are not updated once published. This presents another opportunity for future research, namely, the task of forward linking the patent collection. A patent should be explicitly linked not only to prior art patents, but also to patents for which the patent itself is prior art. We suggest that patent collection curators should view patent documents as live objects (as far as metadata is concerned) and allow for enriching the collection with new links amongst patents as the collection grows. This would present a mammoth task if it were to be performed manually, but with automated approaches it is achievable.
Some studies have discussed the importance of having, in a document, a wide variety of publication types available through Web links (Smith, 2004). A Web link might be regarded as being equivalent to a citation if the target page was a research source, such as technical papers, software sources, e-journals and conference papers. Using automated link discovery, it is possible to discover more likely bibliographic coupling and more likely co-citation occurrences. Beyond that, it is possible to link patent collections, in principle at least, to the vast repositories of open scientific and technological literature. So to improve systems that classify using bibliometric data by enhancing the citation graph through automated link discovery is an inviting open field of research that could be explored more often and more thoroughly by researchers. An added benefit from automated link discovery over patent collections is that it makes the patent documents more accessible. To the domain expert a patent may be easily comprehensible, but to others who may wish to understand a patent without expert knowledge in the domain, such a link to related literature can be invaluable in closing knowledge gaps in an efficient manner. Automated classification systems can be an invaluable tool for automated link discovery systems. There is an opportunity to research how the imposition of a patent classification taxonomy over scientific and technological literature collections can be applied, in a scalable manner, and how such a classification may assist in patent search and invalidation processes.
One important issue in automatic distribution of patents across the categories is related to the distribution of words within a patent. The inconsistencies found in that distribution are related to the Pareto principle and Zipf’s law (Benzineb and Guyot, 2011). When groups of objects are separated according to external criteria, they tend to show a Pareto-like distribution across the categories. In others words, over a large volume of categories and documents, about 80% of all the documents are classified into about 20% of the categories. It also happens, according to the Pareto principle, with patents because they are grouped by topics defined externally by human experts. This statement creates a structural issue for any artificial intelligence system based on example-based learning. Inevitably, many of those categories contained in that 80%, which share only 20% of the total training set, may be under-emphasized in the training process. Zipf’s law states that the most frequent word occurs approximately twice as often as the second most frequent word, which occurs twice as often as the fourth most frequent word and so on. That means that most of the words encountered by an automatic classification system will not occur very frequently. The combination of the Pareto principle and Zipf’s law suggests that it is important to keep words which occur a small number of times in the index because they could be representative of a poorly documented category. Automatic classification, without using the topics defined by human experts, can offer a solution to this problem. Another solution to this problem would be to go beyond the use of contextual features to classify documents, thus incorporating other features such as citation networks and author networks, among other features that can be distilled from the metadata associated with patent documents.
Conclusions
In this article we have attempted to identify problems, to analyse them conceptually, and to suggest research questions for future research. These four research questions were proposed:
- Is the knowledge embedded in patents accessible to inventors and users, making it possible for them to identify technological advances in specific domains of knowledge?
- What is missed by the current automatic patent classification and search used by patent offices?
- How is it possible to classify documents as patents minimizing the influence of scalability issues?
- Are the current patent processing technologies discussed in the literature exploring and exploiting the richness of a patent document?
Of the research questions, the most likely for immediate study and solution is the first one, which discusses the accessibility of the knowledge embedded in patents. Even after all the efforts in developing and improving these systems, there is a gap between indexers, computer scientists and information architects, showing that an initial need is greater integration and communication between them. The results of research that were discussed in this article need to be accessed by all involved and a feedback loop can improve each of the analysed systems.
Patent offices continue their effort trying to find a common classification system, discussed in problems two and three, as lately reported by the Korean and Chinese offices, with the Korean Intellectual Property Office and the State Intellectual Property Office of the People`s Republic of China introducing the Cooperative patent classification as their internal classification scheme. Those efforts will allow for better standardisation and, thus, for improving access across patent offices around the world.
Even in the light of all the problems discussed in this paper, the big taxonomy used by existing patent classification systems represents a rich source of practical terms. This fact opens the possibility of automatically classifying research papers into a patent classification system. This could make it possible, for example, to conduct an effective prior art search in research papers and to retrieve sets of documents directly related to existing patent classes. Patent collections represent an enormous body of human creativity with focus on applied practical knowledge. Ideas for innovation emerge from accumulated knowledge over a long period of time. Intellectual property embedded in inventions and with explicit and detailed explanation and interpretation is crucial in the decision-making process and knowledge-based economies. To take advantage of the existing knowledge that is embedded in patents documents, easy access to patent knowledge is essential for incubation of new ideas.
Acknowledgements
The authors would like to thank Charles Cole, Associate Editor of Information Research, for the rich discussions about the organization of this paper, Osmat Jefferson, Principal Scientist from CAMBIA, Australia, and Prof. Paulo E. M. Almeida, from CEFET-MG, Brazil, for the support and for the valuable suggestions. This research was supported by grants from Coordenação de Aperfeiçoamento de Pessoal de Nível Superior (CAPES - Process BEX 18208-12-6) and by Queensland University of Technology (QUT).
About the authors
Magali Rezende Gouvêa Meireles is an Associate Professor in the Pontifcal Catholic University of Minas Gerais, Institute of Exact Sciences and Informatics, São Gabriel, 31980-110, Belo Horizonte, Minas Gerais, Brazil. She received her Bachelor’s degree in Electrical Engineering from Federal University of Minas Gerais, M.Sc from Federal Centre for Technological Education of Minas Gerais and Dr.Sc. in Information Science from Federal University of Minas Gerais, Brazil. She can be contacted at magali@pucminas.br ORCID No: orcid.org/0000-0001-6928-7132
Gabriela Ferraro is a Researcher at the Machine Learning Group, National ICT Australia, 70-72 Bowen Street, Spring Hill, Brisbane, Queensland, Australia and an Adjunct Research Fellow at the College of Engineering and Computer Science at the Australian National University. She received her Bachelor's degree in Information Science from the Champagnat University, Argentina, her Master in Applied Linguistics from the Institut Universitari de Lingüística Aplicada and PhD in the Department of Information and Communication Technologies, both from the Universitat Pompeu Fabra, Spain. She can be contacted at gabriela.ferraro@nicta.com.au
Shlomo Geva is an Associate Professor in the Science and Engineering Faculty, Queensland University of Technology, 2 George St, Brisbane, Queensland 4000, Australia. He received his Bachelor’s degree from Hebrew University of Jerusalem and his Master and PhD from Queensland University of Technology. He can be contacted at s.geva@qut.edu.au