A coding system for qualitative studies of the information-seeking process in computer science research
Cristian Moral, Angelica de Antonio, Xavier Ferre and Graciela Lara
Escuela Técnica Superior de Ingenieros Informáticos, Universidad Politécnica de Madrid, Spain
Introduction
Seeking information is a key activity in research that consists of two main components: search and exploration. Search refers to the tasks performed in order to obtain a first corpus of results. Some activities related to this component are query construction or selection of the information source where the search is going to be performed. On the other hand, exploration refers to the tasks oriented to determine which of the preliminary results are actually interesting and useful to meet the information needs the researcher has at that time. It is also related to the habits and standards adopted by the researchers to organize and classify the selected information.
In every field of study, researchers are required at some point to look for information. However, information-seeking is still one of the most difficult and time-consuming activities in research. Even if there are many generic and specific search engines, the extremely large amount of information now available and the high range of possibilities for information use make it very difficult to standardise and generalise the process. The information-seeking process, especially the exploration component, requires from the user an effort to individually process the collected information. Individual characteristics of the user, like his/her professional profile, preferences, capabilities, or experience have a great influence on how the process develops. Additionally, many other external factors can affect the process, like the purpose of the search, the context of use - in space and time - or the available technology. Therefore, a one-size-fits-all approach is not the best solution, as all the differences, similarities and specificities are then inevitably ignored. Today there are a lot of tools – search engines, meta-search engines, scientific repositories, reference managers, impact metrics… - but most of them do not take into consideration and adapt to the singularities of the user and the context wherein the information is sought. The goal of our research is to demonstrate that the information-seeking process is not universal and consequently support tools need to be adaptive and adaptable, so that the system moulds itself to the user, rather than the user moulding to the system.
To achieve this goal, the information-seeking process had to be studied and analysed in order understand it more perfectly. We believed that a deeper understanding would allow us to develop a reference model of the information-seeking process performed by researchers in computer science that takes into account the differences, similarities, and singularities existing for different users in different conditions and situations.
We have run a set of qualitative studies in order to elaborate our theory based on real data from real researchers. The use of rigorous tools is needed to properly analyse qualitative data, which is essential to ensure the correctness of the model. In this paper we present one of these tools, a coding system, that has emerged from the analysis of the data. The coding system is presented as list of codes that have been hierarchically grouped and ordered according to the concepts they are related to. A complete definition of each code has been included, together with real examples of use in coding system individual interviews. In the future, the concepts that emerged will be the seed for the construction of a model of the information-seeking process performed by researchers in computer science. This model, in turn, should inform the design of adaptive and adaptable support tools.
In the remainder of the paper, we first review the general methodology we followed, while in sections 3 and 4 we detail how the two qualitative studies – the focus group and individual interviews, respectively – were carried out. The description of how the obtained data were analysed and how the coding system emerged from these data is provided in Section 5. Final results after the refinement and validation of the coding system are presented in section 6. Finally, some conclusions and descriptions of future work are given in Section 7.
Methodology
The information-seeking process is a very familiar activity for researchers, but it is difficult to formalise. Our first approach was to informally ask some of our colleagues how they seek for information during their research activity. Some of them were unable to explain how they look for, select, classify and archive papers for their research. Either they had interiorised and mechanised the process to such a degree that they did not remember how they usually perform it, or they considered the process un-quantifiable because it depends on many external factors. There were some of them who attempted to propose a definition of the process, but there was a high variability between them. In both cases, the results would have probably been wrong, incomplete or forced.
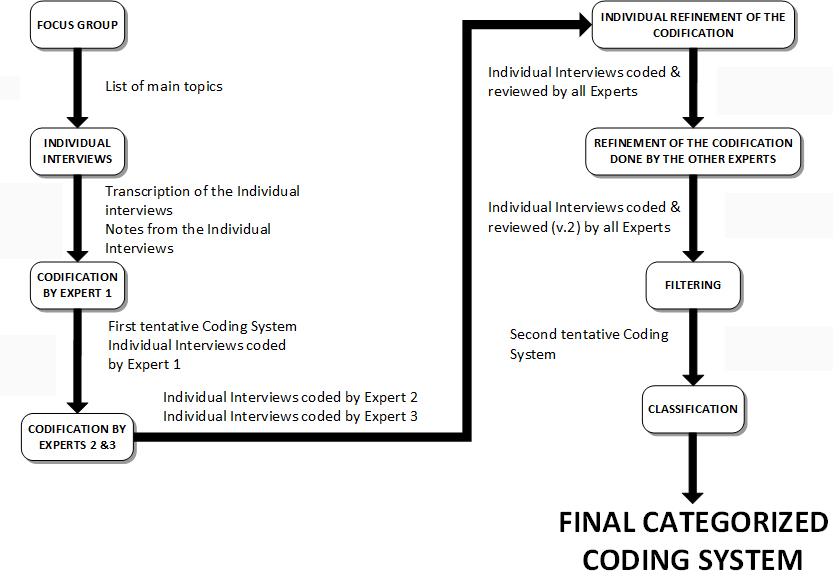
In order to overcome this lack of definition and the potential subjectivity, we ran a set of qualitative studies (see Figure 1) so as to increase our understanding of the process and objectivise the process as much as possible.
First of all, we decided to run a focus group (Krueger and Casey, 2009) formed with researchers, in order to provide them with a relaxed environment where they could share and contrast their ideas and opinions. In this way, researchers who initially were unable to define the process could discover similarities with other researchers so that they could better realise how they seek for information. In turn, the discussion would help identifying the similarities and differences in the process between them.
At this point, the main aspects and ideas stemming from the focus group were the starting point to develop a questionnaire that served as a guide for running individual interviews to researchers. Basing the questionnaire on a previous group interview with researchers decreased the risk that important ideas might be omitted in the interview design. These interviews were the main source of data collection for the formalisation of the information-seeking process in the context of computer science research.
It is important to highlight that both the focus group and the individual interviews were conducted in Spanish, and then the data were also collected in Spanish. In order to facilitate and internationalise the results of our study, we have reliably and thoroughly translated both the tools, namely guides, questions, and keywords, used during the qualitative studies and the results obtained from the qualitative analysis, ensuring that both the content and the meaning were the same.
During the whole process we established as an essential and leading criterion the achievement of a high level of quality in both the design and the conduct of the qualitative studies, and in the obtained results. To reach this goal, we used as a guideline the criteria proposed by Tong, Sainsbury and Craig (2007) when reporting the results that emerged from focus groups or interviews. Explicit and detailed information has been provided in this paper about the personal characteristics of the members of the research team and their relationship with the participants; the selection of the participants; how and where the data were collected; how the data were analysed and how the results were reported. We also considered some issues that, according to Miles and Huberman (1994), should be addressed both during the design and conduct of qualitative studies, and when reporting the results, in order to ensure the quality of the obtained results. To be more specific, we took into consideration the confirmability of the results – e.g., the methods and procedures we followed are explained in detail –, the reliability of the results – e.g., the research question has been made clear, and the researchers' role and status have been explicitly described –, the internal validity of the results – e.g., results have been triangulated –, the external validity of the results – e.g., details of the sample have been provided and we have defined the boundaries and scope of the results for generalisation – and the application of the results – e.g., the results are available to potential future users and they potentially can help to answer the research question posed.
Focus group
Research team
As the number of participants in the focus group was relatively large, the study was led jointly by two members of the research team.
The second author of this article was the facilitator, whose role is to guide the discussion in order to ensure that participants do not deviate from the topic. To do this, the facilitator can pose some general questions to launch the conversation or to go deeper into an interesting thought or idea mentioned by one or more participants (Kitzinger, 1994). This does not mean that the facilitator poses questions and the participants just answer them, but rather the opposite. Participants have a high degree of freedom to redirect the discussion to any topic they consider interesting. The facilitator's role is to ensure that this deviation still keeps the discussion on track. The second essential aim of the facilitator is to manage the speaking time of the participants, so everybody can express his/her opinion. This is extremely important in order to avoid having answers only from dominant participants, to the detriment of shy or low confidence participants (Kitzinger, 1995). Additionally, results are richer if all the participants give their opinion and participate in the discussion. In our case, the role of facilitator was undertaken by a senior researcher, a full professor at the University, female and aged between 45 and 50. The facilitator has a large experience running qualitative studies, which was considered essential to ensure the proper development of the focus group.
To give support to the facilitator, the first author took the role of notetaker. The purpose of the notetaker is to annotate things that go beyond the speech itself, items of interest that can provide more details to the words of the interviewees (Powell and Single, 1996). Into this category falls the so-called non-verbal communication - the tone and volume of the voice, or the gestures and postures the speakers make during speech, among others. In this case, the role of notetaker was played by a Ph.D. student in computer science, male and with no previous experience running qualitative studies. The notetaker remained silent during the session in order not to break the group dynamics and to avoid interfering in the facilitator's work.
Research sample
The research sample was composed of 9 participants. The selection was performed under a set of strict restrictions in order to obtain not only relevant, but also significant results.
All participants were required to have a professional background in the same field under study. This meant that all participants, one way or another, were involved in some kind of research in the field of computer science. We tried to consider as many profiles as possible, and then selected both senior and junior researchers in the field. The first group was represented by five university professors, all of them with a Ph.D. in computer science, while the second one was formed by four Ph.D. students in computer science.
As computer science can be divided into many specific areas, we also tried to cover most of these areas in the focus group. Each of the professors represented a different department inside the computer science School (UPM): Computer Systems Architecture and Technology , Artificial Intelligence , Linguistics Applied to Science and Technology , Computer Languages and Systems and Software Engineering , and Applied Mathematics . In turn, the Ph.D. students were researching a variety of topics - Software Engineering, Virtual Environments, Data Mining and Intelligent Software Agents. In demographic terms, participants were aged from 28 to 50 years old, with three female and six male.
All participants were contacted via email. The message was standard for all the candidates and explained in general terms the purpose of the focus group and how it would take place. It also informed potential participants that there would not be any kind of compensation or incentive, apart from helping us in our research topic. At the end of the email, they were requested to indicate their interest in participating in the study. The ones that answered affirmatively were replied to with a message of gratitude and a request to choose the most suitable date for them to participate.
After selecting the most popular date, one of the participants had to cancel her participation because of incompatibility with the schedule, but she proposed another participant with a similar profile in terms of field of research, age and level of expertise as researcher.
All the participants - except one Ph.D. student - and the team members running the study knew each other to some extent, either as coworkers, from membership in the same research lab, or for having attended some course taught by another participant.
Study design
Introduction
The facilitator welcomed everybody and thanked them for their participation. In order to provide some context, she reviewed the origin and purpose of our research and explained, in general terms, the objectives and the procedure of a focus group.
As a gold standard for the whole session, the facilitator asked all the participants to be as sincere as possible. She made it clear that no answer would be considered as a bad answer but, on the contrary, all answers would be good, interesting and relevant for our research. Finally she stated very clearly that in any case, none of them or their methods would be questioned, and then asked them to feel comfortable, recognizing that there was no pressure.
Open-ended questions
The discussion started with the following question: ‘How do you seek for information while carrying out research?' During the nearly two hours of the session, the facilitator intervened very few times to help participants to remain focused, or to motivate some of them to participate.
The facilitator used a set of keywords previously defined by the research team as a guide. These keywords referred to general concepts that were considered potentially related to the topic. Some examples are phases, objectives, tasks, context, user profile, tools, workspace, search, filtering, classification, visualisation or interaction. With these keywords, we expected to obtain answers to questions like: Which are the steps of an information-seeking process? Which are the problems and deficiencies you usually have to face while looking for information? What else would you like a system to do to help you during the information-seeking process? However, no predefined questions were used, to allow the discussion to flow and to avoid prejudicing the participants' opinions.
Setting
The session took place in a meeting room of the computer science school, which is the common workplace of both the participants and the research team. Participants, facilitator and notetaker sat at a round table in order to facilitate the communication and provide a feeling of equality, so as to promote participation. As the focus group was expected to finish just before lunch time, some finger food and beverages were provided during the discussion to help participants feel comfortable and focused.
Data collection
In order to allow both the facilitator and the notetaker to be focused on the discussion, the session was audio-recorded using a smartphone. Before starting the session, all participants were informed of the recording and were asked for permission. The facilitator also informed the group that the recording would be only used to analyse the discussion and that, in no case would individual opinions would be identified in any published report or subsequent work.
No further interviews were made with the participants to corroborate their discussion and the final transcripts were not returned to the participants. We did not ask for feedback from the participants on the findings.
Data Analysis
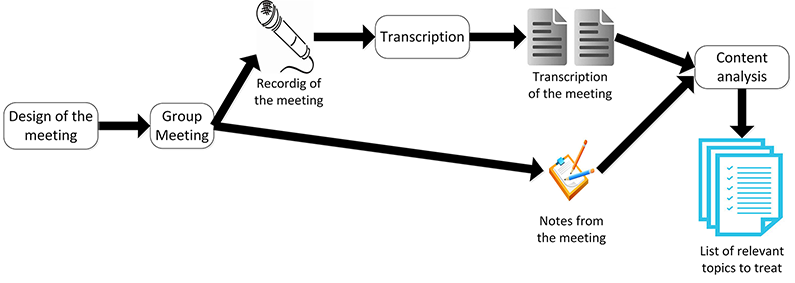
Once the session was transcribed, the research team analysed and discussed the content of the focus group (see Figure 2).
The intent was to identify which aspects are involved in the information-seeking process. As a result, the analysis consisted of grouping related ideas or comments so as to draw a preliminary conceptual map of the main themes that should be considered while studying the information-seeking process. At the end, 13 concepts related to the information-seeking process were identified:
- Archiving
Comments related to the activity of archiving of the articles during the information-seeking process. - Corpus
Comments related to the set of results obtained after a search process. - Search process
Comments related to the process of looking for results that may cover an information need. - Reading process
Comments related to the process of reading the articles selected after the information-seeking process. - Exploration process
Comments related to the process of exploration of the results obtained from the search process. - Wishes
Comments related to things the user would like to happen during the information-seeking process. - Difficulties
Comments related to difficulties found during the information-seeking process. - Collaborative work
Comments related to the information-seeking process performed collaboratively in a team. - Workspace
Comments related to the organization and use of the physical and digital space during the information-seeking process. - Tasks
Comments related to tasks undertaken during the information-seeking process. - Meta-information
Comments related to meta-information used during the information-seeking process. - User profile
Comments related to the profile of the user with respect to the information-seeking process. - Reference manager
Comments related to reference managers used during the information-seeking process.
Individual interview
In order to refine the initial set of concepts obtained from the focus group, we carried out a set of interviews with the aim of obtaining a set of adequate codes for tagging information-seeking activities in this computer science research. The results of the focus group served as a basis for the design of the questionnaire. The interviews were conducted individually in order to allow each participant to explain in detail how he/she seeks for information while researching.
Before running the interviews, we developed a semi-structured questionnaire to guide the sessions. Some of the questions were open-ended in order to allow wide and unbounded answers from interviewees, but also in order to avoid biasing the participants by unintentionally leading their answers. As an example, the first question ‘How do you seek for scientific papers while doing research?' was very general and open-ended, allowing the user to express almost anything related to the studied process. Some more specific questions were also posed when we wanted to obtain more details about more concrete aspects, but even in these cases the interviewees were able to express their ideas openly as they were asked to explain more in detail their answers: ‘Do you think the information-seeking process varies according to the context? Please explain your answer'. Additionally, the interviewer had the freedom to pose new questions to delve into interesting comments, or to clarify incomplete or unclear answers, thus making the interview more flexible, in order to obtain as much information from the interviewees as possible (Bernard, 1988; Crabtree and Miller, 1999).
Research team
In order to maintain the consistency in the interviewing process, all the interviews were performed by the same member of the research team. In this case, the notetaker of the focus group was considered the best member to carry out the interviews, as he had been present during the group interview.
Research sample
The criteria followed to recruit participants were exactly the same as in the focus group: senior and junior researchers from different areas of the computer science field, covering a range of ages - in this case from 27 to 55 years old. In order to avoid interviewing biased participants, all the researchers that participated in the focus group were considered ineligible for this second qualitative study. Again, potential participants were contacted via email using a standard message, explaining to them the purpose of the interview and how it would take place, and informing them that participation was unpaid. Among those who answered the email indicating they were interested in participating, 5 females and 3 males were selected.
Once again, the interviewer and the interviewees knew each other to some extent, either because the interviewer had previously attended some course taught by the interviewee, or because both worked in the same research lab.
Study design
Introduction
The interviewee was first welcomed and thanked for his/her participation, and then the interviewer introduced him/her to the purpose of our research. Details were provided as to how the interview would proceed.
The interviewer also asked the participants to be as sincere as possible, stating clearly that we were not evaluating neither him/her nor his/her methods, but only trying to figure out how the information-seeking process is carried out from different perspectives.
Open-ended questions
Even if predefined questions were used to guide the interview, the interviewee was allowed and encouraged to explore topics, reflect, and generally express everything he/she considered relevant for the question or for any other topic he/she considered related and/or interesting. Our main goal was to bring to the surface all the concepts, problems, suggestions, difficulties, tasks, and so on, related to his/her information-seeking processes. As a result, we let the interviewee develop his/her ideas and thoughts as much as he/she wanted.
To reinforce this goal, the interviewer was allowed to pose unplanned questions not present in the script when needed in order to dig deeper into an idea, to clarify an ambiguous answer, or to nail down an interesting comment.
Setting
The location and schedule for the interviews was agreed individually with each of the participants according to their availability and preferences. Five weeks were needed to perform all the interviews, and seven of the eight interviews took place in the interviewee's workplace, while one of them was carried out in the interviewer's workplace.
Only the interviewer and the interviewee were present during the interview to avoid external influences that could disturb the participant.
Data collection
As the interview was expected to be quite long, the session was audio-recorded using a smartphone, while the interviewer was focused on obtaining as much information as possible from the interviewee. Recording the interview also allowed the interviewer to take notes regarding non-verbal communication that could complete some answers. As in the focus group, all participants were informed of the recording at the beginning of the session and were asked for permission. The interviewee was also informed about the planned use of the recording, which would only be analysing his/her answers. Finally, they were informed their name would not appear in any report or subsequent work without their explicit permission.
In this case, the interview was pilot-tested. In fact, two pilots were run. The first one was a controlled pilot where the interviewee was a fellow researcher, who was then ineligible for the study. The aim of this pilot was to set up all the materials and try out the whole procedure, to ensure that we had considered every relevant aspect and nothing was left to improvisation.
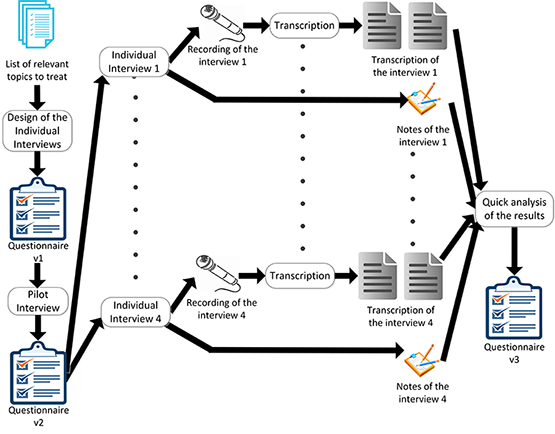
Once the procedure was verified and refined according to the first pilot, we started running the interviews with real participants. After conducting four interviews, the interviewer transcribed them in order to perform a first analysis evaluating how rich and complete the answers were, and if the questions were clear enough and covered the topic broadly. The analysis was made only by skimming the transcriptions of the interviews. This analysis, together with the experience of the interviewer, gave rise to reformulation and reordering for some of the questions of the questionnaire that were ambiguous or hard to understand for the interviewees. Nonetheless, no questions were added or deleted, keeping exactly the same content and semantic (see Figure 3).
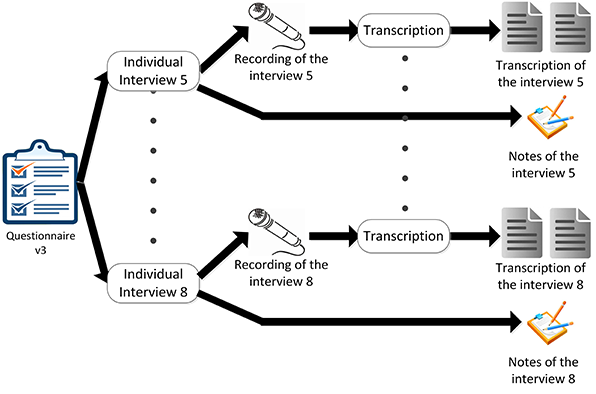
After this, four more researchers were interviewed with the updated questionnaire (see Figure 4). In both cases, each interview lasted around one hour, even if they were not time-limited and each interviewee had as much time as desired to express his/her ideas.
Apart from this, no further feedback was obtained from the participants –neither from further interviews, revision of the interviews' transcriptions, nor comments regarding the findings.
Data analysis
Our aim in this research is to provide a framework allowing the formalisation of the information-seeking process performed while researching in the computer science field. Amongst the available tools used to analyse qualitative studies, grounded theory (Glaser and Strauss, 2009) was used as it allowed us to start the analysis from scratch. Grounded theory is an inductive approach allowing concepts to emerge from freely, without a starting point of pre-defined concepts or hypothesis. With grounded theory a theory may emerge from the data, but it will not be proved (Corbin and Strauss, 2008).
The analysis was performed through a systematic and iterative approach based on the assignment of tags to parts of free text (Saldaña, 2012). These labels, named codes, are grouped according to the concept they deal with, which supports the formation of a theory. This codification and categorisation is performed iteratively in order to refine the analysis, typically following these four stages:
- Open or emerging coding system
Text is coded from scratch, without using any kind of theoretical framework or published code list. One code is assigned to each unique phenomenon. - Development of concepts
Similar codes are grouped under concepts. - Grouping concepts into categories
Similar concepts are grouped into categories. Each category has a detailed description. - Formation of a theory
Identification of connections or co-relations between concepts and categories in order to infer or predict a theory.
During recent decades, many researchers have proposed models of the information-seeking process. While some of them are rather general (Kuhlthau, 1991; Wilson, 1981; 1997; 1999), many of them only consider the information-seeking process in specific fields like social sciences (Ellis, 1989; Meho and Tibbo, 2003), physics (Cox, 1991), chemistry (Hall, 1991), engineering (Hertzum, 2000) or advocacy (Makri, Blandford, and Cox, 2008). Even if many of them also use grounded theory as the qualitative tool to formalise a theory (Ellis, 1993), none of them specifies which coding system they have used. In addition, to the best of the authors' knowledge, no models have been proposed for the information-seeking process in computer science, and there is no published coding system that could be useful as a base upon which to create an adapted one. Therefore we needed to develop our own coding system in order to formalise a model for the information-seeking process in computer science, and we consider that the resulting coding system could be of value for researchers who would like to perform a qualitative study related to this topic.
As of the writing of this article, we have completed the first three stages in the grounded theory method, and as a result a hierarchical list of codes grouped into categories of concepts has been generated. In the near future our intention is to further formulate a theory for the information-seeking process performed by researchers in computer science.
Codification process
Coders
Qualitative studies are inherently subjective because of their nature. There is no scientific and straightforward method to analyse text or speech, and then results, inevitably, depend to a greater or lesser extent on the researcher who carries out the codification.
Being aware of this limitation, we intended to provide results as objective as possible by minimizing individual subjectivity while coding as much as possible. To do this, we decided to code the interviews' transcript in parallel with three different coders. One of the coders was the same one who carried out the interviews and transcribed them, and may have had a higher risk for bias. To compensate for this, the other two coders did not participate in the qualitative study until all the interviews had been conducted and transcribed.
The two coders in charge of the validation of the coding system were recruited because of their closeness to the topic and because of their experience in conducting qualitative studies. Both coders have a similar profile: senior university professors and researchers in a computer science school, whose field of research is human-computer interaction, both around 40 years old. To avoid possible differences in interpretation of the interviews because of the gender, one of the coders was male and the other one was female.
Iterative process
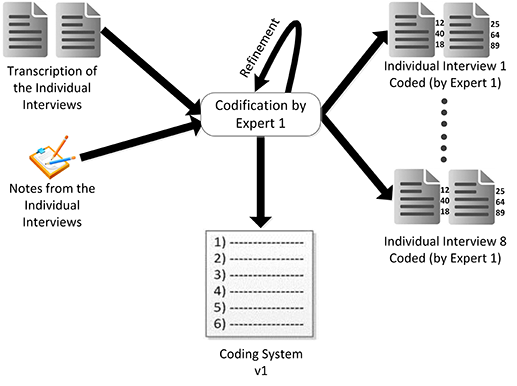
The codification process consisted of several phases. To begin with, the first coder developed a preliminary version of the coding system tagging the interviews' transcriptions totally from scratch (see Figure 5). The assignment of labels was performed using ATLAS.ti, a software tool for analysing data from qualitative studies. As we chose an interpretive approach to analyse the qualitative data, we needed codes to emerge from the text. Therefore, the coder labelled each sentence – or group of closely related sentences – with keywords that reflected the concepts or ideas emanating from the text. Initially, many of the codes that emerged were ad-hoc, redundant or hard to understand. An example is the code ‘DIFFICULTIES – Find interesting articles or authors that do not have too much impact or are not known experts in the field' that was used to label the portion of text ‘It is difficult to find somebody who is not very well known in the field or does not have published any article with a high impact, but is working in the same topic as I am'. It seemed obvious that both the code and the text were almost the same, and then the code would be hardly reusable in other cases, offering little scope for re-use.
As the coder encoded the interviews, he acquired some perspective that allowed him to refine the initial codes and where they were used. Each iteration resulted in a new refinement to the coding system, where new codes were added and former codes were deleted or reformulated. As a result, when the coder concluded his work, the coding system contained 189 codes.
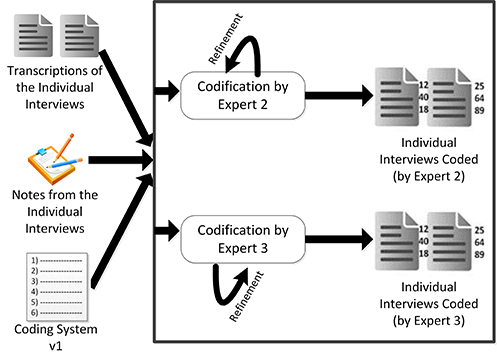
In the second phase, the other two coders were given the transcriptions of the interviews alongside with the coding system, and were asked to code them individually, that is without contact between them (see Figure 6). No guidelines or rules were given to these coders to avoid influencing them. The only direction they were given was to identify bad codes – ambiguous, incomprehensible, misspelled – or relevant parts of text where no code was suitable to express the underlying idea. Furthermore, in order to avoid any external influence or preconceived ideas, transcriptions were anonymised. Coders were asked to revise and refine their codification until they thought it was acceptably accurate and comprehensive.
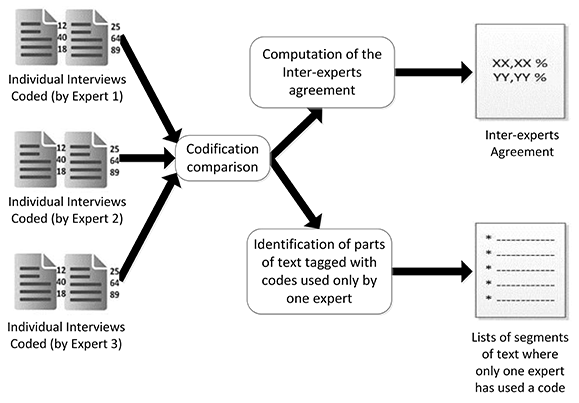
Once all the interviews were coded by all the coders, the rate of agreement was computed to determine the validity of the coding system (see Figure 7). The computation was made taking into account how many codes had been used to tag the same portion of text. In this phase, the mean agreement rate of the three coders was 18.88%. In general terms, this rate may seem very low, but considering that the codification is made for text without any kind of structure nor delimitation, that three different researchers have coded individually this text, that the codification was subjected to a high degree of subjectivity, and that a non-verified preliminary version of the coding system was used, the yardstick changes. For those reasons, we decided to adopt as the agreement rate the proportion of times that at least two of three coders have used the same codes to tag the same chunk of text. We considered that, if at least two coders decided individually to use the same code, this meant that the code was sufficiently descriptive and meaningful, and then had to be included in the coding system. Therefore in this second iteration the mean rate of agreement of at least two of the three coders was 40.87%, which is significantly higher than in the first iteration.
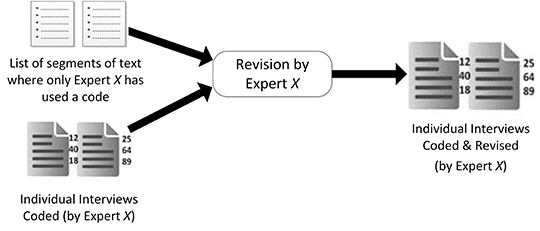
A third iteration was planned from the beginning, as we expected that, this being their first approach to the codes, the two coders validating the coding system would need some time and practice to become familiar with them. Thus, in this iteration, the starting point was the three sets of coded interviews, each one coded by each of the coders. The main objective in this phase was to identify if differences in codification were due to errors while coding, misunderstandings, or because of differences in interpretation. Each coder received his/her set of coded interviews together with the list of codes that had been used only by him/her to tag a specific portion of text. Each coder then had to evaluate, again individually, why they were the only ones using these codes. As a result, coders could reconsider their decision and use another code they consider more appropriate, or on the contrary they could reaffirm their decision and maintain the original code (see Figure 8). After this revision, the mean agreement rate was 28.53% for all three coders when all the codifications were considered, while 57.53% of the codification was the same for at least two of the three coders.
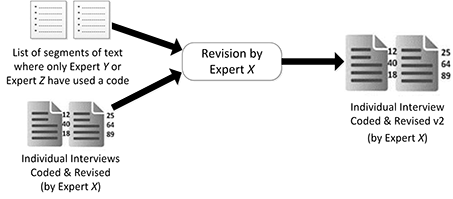
The next step consisted of identifying which codes were still used by only one coder in a specific chunk of text, but in this case we sent the codes and the text where they were used to the other two coders (see Figure 9). At this point, if at least one of these two coders agreed with the use of the code, it was validated and added to the coding system. Conversely, if both coders were against using the code in that portion of text, the code was discarded. This validation phase resulted in a 31.18% of agreement between all the coders, and 66.43% between at least two of the three coders.
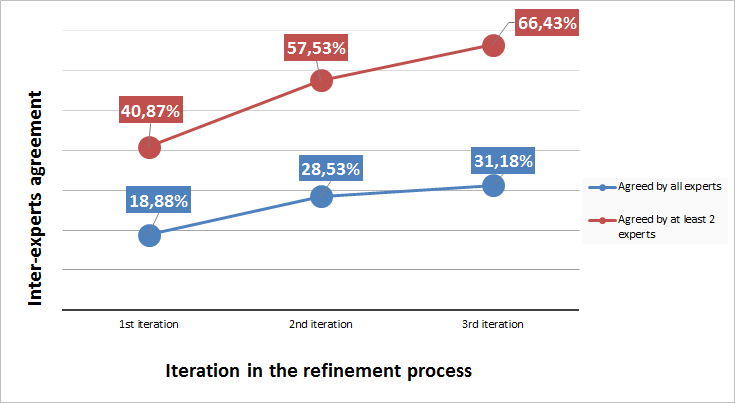
Figure 10 shows the evolution of both inter-coders agreement rates – rate of codes agreed by all the coders, and rate of codes agreed by at least two of the three coders – during the refinement process.
| Action Performed | Initial Code(s) | Resuting Code(s) |
|---|---|---|
| DELETING CODES NEVER USED | WISHES: Integrate all the available information. | - |
| MERGING REDUNDANT CODES | WORKSPACE: Relevant articles are clearly differentiated. | WORKSPACE: Relevant articles for the current task are kept at hand. |
| WORKSPACE: Relevant articles are kept at hand. | ||
| ADDING NEW CODES | - | SEARCH - SOURCES OF INFORMATION: Local Repository. |
| DIVIDING TOO GENERAL CODES | WISHES: Suggestions should be displayed only on demand and in a non-intrusive way. | USER WISHES - VISUALIZATION: To display suggestions only on demand. |
| USER WISHES - VISUALIZATION: To have a non-intrusive visualisation of the suggestions. | ||
| DELETING USELESS CODES USED ONCE | INFORMATION-SEEKING PROCESS: It is the starting point to write an article. | - |
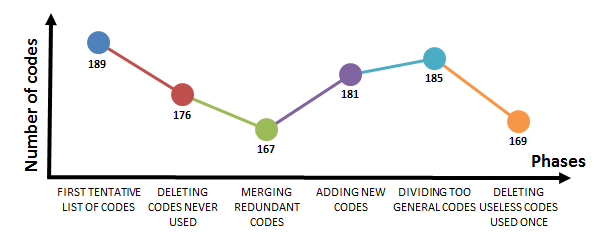
Finally, a last iteration was performed to filter the codes that had little or no use by the coders. Additionally, new codes had to be added to the first version of the coding system in order to label the portion of text, identified by the two coders in charge of the validation of the coding system, where no previous code was good enough to label the underlying idea. This phase was carried out over several group meetings, where decisions were discussed and agreed to by all three coders. The codes that had not been used at all in the final codification of the interviews were considered redundant, erroneous or unneeded, so they were deleted from the coding system. Altogether, 13 codes were deleted, with a total of 176 codes left in the coding system. After this step, 17 codes, which had been used at least one time, were considered redundant and merged into 8 new codes. This merge decreased the number of codes to 167. After this, all three coders discussed proposed new codes not present in the first coding system. The result was that 14 codes were added to the coding system, increasing the total number of codes to 181. Some codes were identified as being too abstract, and we decided to divide them into more specific codes: two of the former codes were divided each into two new codes, while a third former code gave way to three new codes. From the remaining 185 codes, 31 of them had been used to code only one text segment among all the interviews. Between these codes, the research team determined that 16 of them were unnecessarily used – for example because they were too specific, or because they did not express a relevant idea, and then had to be deleted, while others were representative of very specific and quirky, but also relevant concepts that had to be represented in the coding system. The evolution of the coding system in this last iteration has been depicted in the Figure 11, and Table 1 provides some examples of the actions performed over the codes.
Results
At the end, we had a coding system that included 169 codes. In order to facilitate the understanding and further use of these codes, for each of them we have written a short description that clarifies its meaning. Additionally, we provide an example of use, extracted from the interviews, for each of the proposed codes, so as to foster application, indicating from which interviewee and at which line of the transcription the text comes from. The full list of codes with their description and examples of use are detailed in Appendix A.
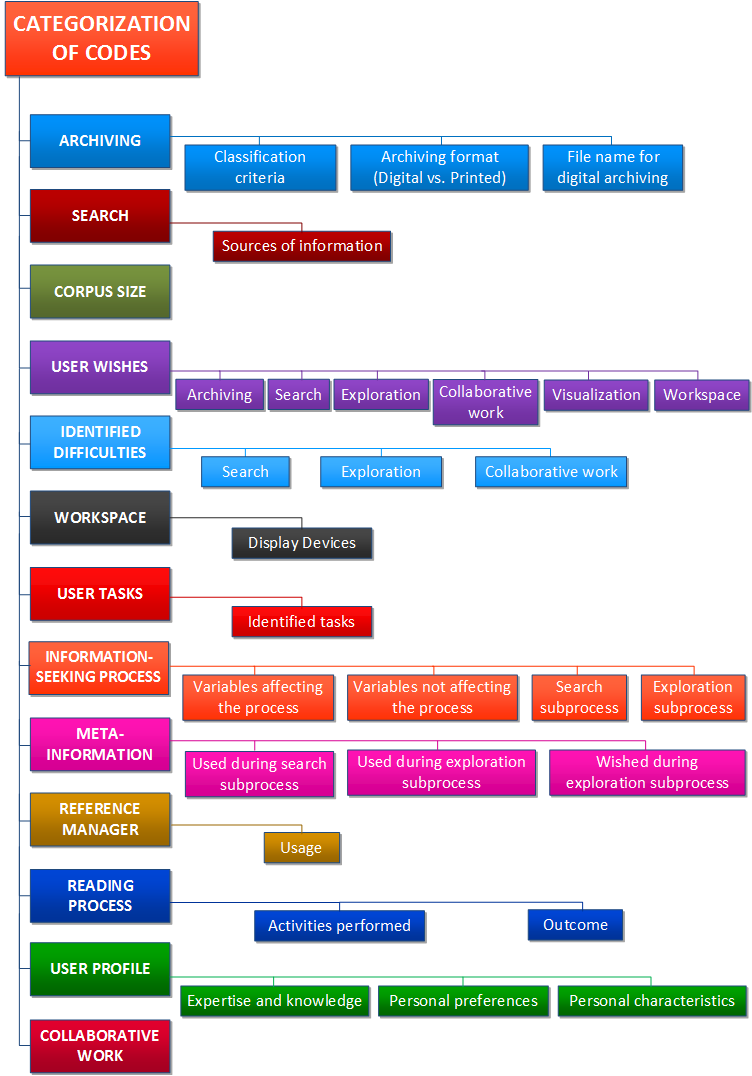
Additionally, we have hierarchically categorised all the codes to allow potential users of the coding system to locate the desired code(s) more easily (see Figure 12). To elaborate these categories, we have taken into consideration the initial aspects identified in the focus group, but also the codes themselves and their use while coding the interviews. Some of these categories were in turn divided into more specific subcategories, which allowed better grouping of the codes based on the specific aspect they dealt with. As an example, the category Archiving contains three subcategories: Classification criteria, Archiving format (Digital vs. Printed) and File name for digital archiving.
Conclusions and future works
Information-seeking is a complex process to define because it consists of a variety of tasks, as well as the large amount of information that is available and accessible. Designing a system to support such process is a challenge mainly because it needs to provide a high degree of interaction with the users. These users have different mental models, different skills, different habits and different goals. In brief, users introduce into the process a high degree of variability. A system that does not consider this variability will oblige the user to adapt his/her methods, goals and personal preferences to the system, instead supporting the user by customizing the system to the user's needs.
Our purpose is to identify the commonalities and specificities, both at the process level and at the user level, to design a system that can adapt its functionality, visualisation and interaction based on the task at hand, the user and the context of use. With this aim, we have run a set of qualitative studies to obtain real information from real users.
In this paper we present the first result obtained after analysing the data, which is a coding or text tagging system for researchers who qualitatively study information seeking processes in computer science.
In the immediate future, we will continue to work on the generation of a set of conceptual models, including those of the information seeking process and the researcher, among others.
As every qualitative study has its own characteristics, restrictions and purposes, it would be impossible to cover every single situation, so we will not claim our coding system is universally applicable. Nevertheless, it can be useful as a reference tool to conduct similar or related qualitative studies. Indeed we plan to evaluate the degree of flexibility of the proposed coding system when applied to new qualitative studies of the information-seeking process in other fields of research.
Acknowledgements
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
We would like to acknowledge all the participants of both the focus group and the individual interviews for their generous collaboration in our research.
We also would like to thank to reviewers and copy-editors of the journal for their assistance in enabling us to improve the quality of the paper and to satisfy the style requirements of the journal.
About the authors
Cristian Moral is a Ph.D. Candidate and Associate Professor in the Escuela Técnica Superior de Ingenieros Informáticos (ETSIINF) at Universidad Politécnica de Madrid (UPM), Spain. He received his Master of Science in Computer Science both from Universidad Politécnica de Madrid and from Politecnico di Torino (Italy). His current research interests are information retrieval, visualisation and manipulation through adaptive yirtual environments, and human-computer interaction. He can be contacted at: cmoral@fi.upm.es.
Angelica de Antonio has been faculty member in the Escuela Técnica Superior de Ingenieros Informáticos (ETSIINF) at the Universidad Politécnica de Madrid (UPM) since 1990. She received her PhD in Computer Science in 1994. Her current research interests focus on virtual and augmented reality, adaptive systems and human-computer interaction. She can be contacted at: angelica@fi.upm.es.
Xavier Ferre has been faculty member in the Escuela Técnica Superior de Ingenieros Informáticos (ETSIINF) at the Universidad Politécnica de Madrid (UPM) since 1999. He received his PhD in Computer Science in 2005. His primary research interests are interaction design and user experience evaluation in mobile applications, user experience in e-health mobile applications, and integration of human-computer interaction practices into software engineering. He can be contacted at: xavier.ferre@upm.es.
Graciela Lara is a Ph.D. Candidate in the Escuela Técnica Superior de Ingenieros Informáticos (ETSIINF) at Universidad Politécnica de Madrid (UPM), Spain. She received a PhD in Teaching Methodology in 2012 and is an associate professor at the Computer Science Department at the CUCEI of the Universidad de Guadalajara, Mexico. Her current research interests are virtual reality, mainly on its application for training, 3D object modelling, and spatial mental models. She can be contacted at: graciela.lara@red.cucei.udg.mx.