Effects of topic progression in interactive video retrieval experimentation
Dan Albertson
School of Library and Information Studies, University of Alabama, Tuscaloosa, AL 35487, USA
Introduction
Interactive video retrieval research examines how users dynamically need, seek and/or perceive digital video while using interfaces of retrieval tools designed to accommodate users’ goals and tasks. One area of this research analyses users’ interactions with video retrieval systems, including how users search, browse and assess video information to meet their information needs in an interactive session. In addition, interactive (video retrieval) implies the importance of user-centred perspectives and/or approaches as applied throughout research and experimentation, such as garnering preferences, perceptions and judgments directly from users. Importantly, both the interactions and perceptions of users can be influenced by context, whether experimental or natural, which can comprise different factors related to users, needs, tasks and assessments.
Users and uses of video information have been assessed using a variety of approaches and through a range of different methods. Prior studies have disseminated findings about visual (image and video) information retrieval by examining query logs, contributing insight about users and interactions across different contexts, such as query characteristics, patterns and tactics (Huurnink, Hollink, van den Heuvel and de Rijke, 2010; Ozmutlu, Spink and Ozmutlu, 2003; Wildemuth, Oh and Marchionini, 2010; Wilkins et al., 2009). Methodologies in interactive information retrieval research are not limited to quantitative analyses. Qualitative methods contribute to a conceptual and holistic understanding, which can complement quantitative analyses by focusing on why certain occurrences were observed. Qualitative methods employed throughout interactive video retrieval research have included interviews, think-aloud protocols, group interviews (Christel, 2007) and also users’ self-assessments (or auto-observations) of video searching with application of grounded theory for analysis (Cunningham and Nichols, 2008).
Interactive search experiments have also been routinely employed to examine users and uses of video information. Such experiments can involve a host of different experimental design decisions, including assembling user pools, developing experimental tasks and search topics, designing and implementing user interfaces (features and functions), identifying appropriate assessments, and others. It is the variations or effects that stem from certain experimental considerations, and, more specifically, the progression of search topics, extending the durations of experimental sessions, which comprise the scope of the present study. Here, a search topic was developed and employed as a static, separate or individual information need statement requesting video information or content, not part of or corresponding to any personal or larger information tasks. This use of search topics in experimental studies is common; influences across topic structure, design and deployment will be further described in this article.
The overarching goal of the present study is to directly measure potential influences and effects for better understanding users in extended or prolonged search situations, as part of interactive experiments, which can inform designs of future research. The specific dependent variables deemed significant in the present study pertained to what users do in an experimental context, e.g., interactions with a system in order to satisfy a given information need, and how they perceive various aspects of their experience and the system. User learning and (system) exposure, even over the course of shorter experimental sessions, can have various effects on research findings, including those involving basic human-computer interaction metrics. Learning effects, for example, have been examined for the purposes of human-computer interaction research and shown significant for providing initial system training and exposure for collecting representative data from experimental contexts. The present study strives to further extend such research to examine some concrete influences, including use or inclination to use specific interface features and users’ perceptions, over the course of interactive experimental sessions (Lazar, Feng and Hochheiser, 2010, p. 52). Understanding specific relationships between such factors can inform the design of experiments for interactive video retrieval research, across different contexts and levels of evaluation, and, in turn, user interfaces that can potentially be employed to counterbalance effects.
Research questions
Previous studies have recognized the importance of topic ordering and potential effects thereof for conducting interactive information retrieval experiments in order to avoid (as much as possible) skewed research data. Researchers have commonly randomized search topics to be given to users in an interactive and experimental setting, particularly experimenter-developed or mock search topics, which have been created to test users and/or different components of a retrieval system. While topic randomization has been performed to control for potential effects of a learning curve, i.e., topics attempted later will inevitably involve users who have had more exposure to an experimental system, the specific effects on research outcomes, as a result of experimental design considerations, have not been directly examined.
Search topic progression has not been directly assessed within interactive video retrieval research specifically, despite the potential effects of certain experimental factors possibly becoming further emphasized in research involving video. Furthermore, interactive video retrieval systems typically comprise complex user interfaces with search and/or browse functions spanning both textual and visual features. Users, in an experimental context, must then contemplate, express and assess multiple channels or types of information for seeking information in a time-based format, all the while using a system in a context where both are unfamiliar. Therefore, it becomes important and warranted to formally and separately examine effects of search topics and their progression throughout interactive video retrieval experiments, which can involve considerations and factors that are distinct from other interactive retrieval contexts.
Investigations such as this are important, as interactive search experiments should be designed to collect research data that most accurately depicts actual users and their natural interactions and perceptions. Analysing our own methods and approaches can enhance understanding about interactive retrieval experimentation. Considering this research has yet to be thoroughly tested, this analysis is not only important for informing future experimental designs, but is significant for researchers needing further understanding and explanation about possible influences within interactive video retrieval situations, including both experimental and real-life contexts.
The problem, as just described, contributes to specific research questions that examine how search topic progression through interactive video retrieval experiments affects or impacts different outcomes related to users’ interaction, perceptions and performance. The present study employed a structured and uniform (not random) ordering of individual search topics, as part of a topic set (further described in the Method secrtion below) to explore the primary and overarching research question:
- What are the resulting effects of the progression of search topics on various outcomes in interactive video retrieval experimentation?
This primary research question can be further broken down to examine individual factors of interactive search experiments and pose more specific questions, such as:
- What are the effects on users’ interactions and search topic performance as topics progress or continue over the course of an interactive search experiment?
- What are the effects on user judgments, particularly satisfaction and perceptions of their own success, as video search topics progress in an experiment?
These questions explore multiple factors making up both users’ interactions and perceptions. The effects of experimental design decisions of researchers need to be directly assessed.
Review
Empirical interactive video retrieval experiments comprise the methodological context of the present study, and examining effects of certain dependent variables, within an interactive study, is the primary motivation. To review, interactive experiments generally entail:- The development of both independent variables, e.g., visual collections, items, or objects, user interface features and functions, user characteristics and others, and dependent variables (user interactions, satisfaction, efficiency and effectiveness) to be measured and used as a basis for comparison.
- User recruitment (ideally from a target or realistic audience) to participate in the experiments.
- Users being presented with a list of search topics that reflect or express visual information needs; the delivery or distribution of these experimental search topics and the effects thereof comprise the scope of the present study.
- Users being asked to complete the search topic by finding information to fulfil the visual information need using an experimental information retrieval system.
Many interactive search experiments have examined specific human-computer interaction and usability metrics such as effectiveness, efficiency and user satisfaction with existing or prototype systems (Christel, 2009). The importance of ecological validity in interactive retrieval research, i.e., striving to make experiments as realistic as possible, whether including the user pool, search topic set or any other experimental design factor, has also been documented (Christel, 2007). Researchers can account for other variations or effects, whether controlling for system knowledge or exposure and/or effects caused by experimental (or search) durations.
Insight into interactive video search experimentation is provided through years of prior research at TRECVid, a workshop held annually at the National Institute of Standards and Technology. TRECVid assembles common datasets and creates standardized task definitions to evaluate different types of video systems and video processing techniques. Of particular note to this study is that TRECVid previously conducted and evaluated the interactive search task, designed to allow for cross-comparison of retrieval system effectiveness from experiments that employ actual users, as opposed to machine operation. The interactive search task, as defined, required participating teams to systematically evaluate video shots retrieved from the common dataset by human users of an experimental system for common search topics across one or more interactive search runs. The successful completion of one full round of search topics, typically twenty-four to fifty topics, constituted a full interactive search run, and the completion of all search runs, the final number of which being up to each participating team, formed the search experiment (Smeaton and Over, 2009). Studies have used the TRECVid protocol to examine actual users and to test novel user interfaces enabling new interaction techniques for retrieving digital video.
A search run, as just described, is a practical generalization of user-centred experimentation (National Institute..., 2008). Experimental design recommendations of the TRECVid interactive search task, including ordering of search topics across the user pool and search runs, were adapted from the protocol of the interactive track of TREC (National Institute..., 2000). TRECVid provided a protocol for designing, organizing and conducting interactive video retrieval experiments, and provided baselines for user experiments and evaluation. The present study examines the effects of various factors of such experimental designs on actual users progressing through the set of search topics of a search experiment. Many aspects of the TRECVid interactive search tasks protocol were employed in the methodology of the present study (fully described below).
TRECVid also created both developmental and test search topic sets, based on the contents of the video collections, and distributed them to participants. Considering video retrieval systems are many times domain-centric, researchers will find it useful to examine research using search topics that are most applicable or representative of the given domain. Experimental search topics can derive from a variety of needs for different types of information. Video search topics in particular can include low-level visual needs (e.g., ‘red circles’), textual needs, i.e., a story being told, visual needs that are semantic in nature (e.g., ‘The Assembly Hall during a blizzard’), abstract visual needs (e.g., ‘clip with visuals that represent happiness’) and others. Information needs can also correspond to different granularities or segmentations of video, such as full movies, video documents, scenes, stories, segments, shots and/or even individual frames. While video needs have not been separately and thoroughly summarized in prior research, image needs and criteria thereof have been comprehensively examined throughout both quantitative and qualitative studies. Findings of such image studies are relevant to the discussion here considering video has visual components. Chen (2001) surveyed twenty-six undergraduate art history majors in two medieval art courses using a pre-test survey and post-test (drawing) exercises, and demonstrated that visual needs in this context most commonly corresponded to known people, places and objects. Choi and Rasmussen (2003) presented the common search types of American History scholars, which mostly included nameable needs. Jörgensen (1996) generalized image needs to include both perceptual, i.e., those comprising criteria directly recognizable by users, and interpretive, which require individualized deciphering by users.
In terms of interactive experiments, search topics have been shown to be influential to other factors, such as topic difficulty, performance and how users subsequently interact with and retrieve digital visual information (Albertson, 2010; Albertson and Meadows, 2011; Albertson, 2013; McDonald and Tait, 2003; Yang, Wildemuth and Marchionini, 2004). Thus, different categories of search topics can be designed to vary from basic to more detailed information needs or can be based on any of a video’s structural components. Experimental (or mock) search topics need to be prearranged and assessed, as part of the developmental process, so it becomes possible to evaluate the exact factors warranting assessment (or what researchers strive to examine) and to collect valid experimental reflecting outcomes from realistic needs of users. It is the influences of the search topics within interactive video retrieval and, more specifically, how they progressed in prolonged experiments, which are examined here. An appropriate set of topics based on the different considerations and characteristics described in this review were developed and used for the present study.
Method
In this study interactive search experiments were conducted with actual users. Data collection methods and instruments were designed to evaluate the different factors potentially significant to the research questions of the present study, including user actions, topic performance, user preferences and other judgments across a set of video search topics systematically ordered to progress uniformly.
Experimental domain and users
Kindergarten through twelfth grade (primary and secondary) science education was the experimental domain. The target audience included both future science teachers and current or former practising teachers who, at one point, taught science as a subject. The end result was a user pool of twenty-eight unique users, consisting of twenty-three former or current science teachers and five upper-level science education majors.
| Subject | Topic | |||||||
|---|---|---|---|---|---|---|---|---|
| T1 | T2 | T3 | T4 | T5 | T6 | T7 | T8 | |
| S1 | 1 | 2 | 5 | 3 | 4 | 6 | ||
| S2 | 2 | 3 | 6 | 4 | 1 | 5 | ||
| S3 | 3 | 4 | 5 | 1 | 2 | 6 | ||
| S4 | 4 | 1 | 6 | 2 | 3 | 5 | ||
| S5 | 1 | 2 | 5 | 3 | 4 | 6 | ||
| S6 | 2 | 3 | 6 | 4 | 1 | 5 | ||
| S7 | 3 | 4 | 5 | 1 | 2 | 6 | ||
| S8 | 4 | 5 | 1 | 2 | 6 | 3 | ||
| S9 | 1 | 6 | 2 | 3 | 5 | 4 | ||
| S10 | 2 | 5 | 3 | 4 | 6 | 1 | ||
| S11 | 3 | 6 | 4 | 1 | 5 | 2 | ||
| S12 | 4 | 5 | 1 | 2 | 6 | 3 | ||
| S13 | 1 | 6 | 2 | 3 | 5 | 4 | ||
| S14 | 2 | 5 | 3 | 4 | 6 | 1 | ||
| S15 | 5 | 3 | 4 | 6 | 1 | 2 | ||
| S16 | 6 | 4 | 1 | 5 | 2 | 3 | ||
| S17 | 5 | 1 | 2 | 6 | 3 | 4 | ||
| S18 | 6 | 2 | 3 | 5 | 4 | 1 | ||
| S19 | 5 | 3 | 4 | 6 | 1 | 2 | ||
| S20 | 6 | 4 | 1 | 5 | 2 | 3 | ||
| S21 | 5 | 1 | 2 | 6 | 3 | 4 | ||
| S22 | 2 | 3 | 5 | 4 | 1 | 6 | ||
| S23 | 3 | 5 | 6 | 1 | 2 | 5 | ||
| S24 | 4 | 1 | 5 | 2 | 3 | 6 | ||
| S25 | 1 | 2 | 6 | 3 | 4 | 5 | ||
| S26 | 2 | 3 | 5 | 4 | q | 6 | ||
| S27 | 3 | 4 | 6 | 1 | 2 | 5 | ||
| S28 | 4 | 1 | 5 | 2 | 3 | 6 | ||
Experimental design
The TRECVid interactive search task previously recommended use of the experimental design and protocol from the TREC interactive track (National Institute..., 2008; National Institute, 2000). The experimental protocol of the interactive track of TREC was based on Latin square design, providing for equal distribution and testing of cases across different conditions, e.g., system interfaces, to control for potential effects from differences among topics and users. The overall experimental design of the present study was based primarily on such a design, with slight modification for distributing search topics across the user pool, which was necessary, given the final number of users, to ensure exact ordering and number of attempts. The final experimental design (Table 1) accounted for potential variations resulting from any individual topic, based on its content, representativeness, difficulty and/or user.
Equal distribution of topics across different spots (of an order) and individual users required that each user complete a total of six out of the eight final experimenter-developed search topics. Again, ordering or sequencing of the search topics was precise and systematic; each was given equally in every position, one to six. Further, every topic in the full set was performed in each position an equal number of times. Ordering the search topics in this manner resulted in each being performed a total of twenty-one times for a grand total of 168 topic attempts in the full interactive study. This approach, as opposed to random topic assignments, precisely controlled for potential variability caused by any characteristics of individual search topics, thus enabling the ability to accurately examine effects of topic progression in interactive video retrieval experimentation. For example, individual topics considered more or less difficult for users would be counterbalanced by equal and uniform ordering and distribution in all spots in the rotation. Therefore, the design of the present study facilitated the examination of the research questions of the present study, which correspond to search progression, not certain topic patterns, across an interactive experiment.
Previous experimental designs in interactive video retrieval have also acknowledged that users may not be capable of attempting a large number or set of search topics in one session. While fatigue may be an expected outcome of the present study, considering the research objective is to examine effects of prolonged interactive search experiments, it was significant to limit effects of fatigue in order to show findings up until a certain point. Moreover, effects of fatigue have been previously examined, generally speaking, and shown to influence variations among users’ performances, including a decline in interest and increased frustration, leading to underachieving on the tasks at hand (Lazar et al., 2010, p. 59). Therefore, fatigue needed to be balanced with expected learning effects, generally speaking, which are correlated with one another, in order to facilitate opportune times and situations to garner data. Therefore, users were also given a short demonstration of the system interface prior to all individual experiments and individual topics were limited to five minutes, even considering prior studies describing how interactive search experiments can last considerably longer depending on topics or tasks. Table 1 presents equal and uniform topic ordering across the users in the experiment.
Experimental search topics
Search topics can be designed to enable targeted evaluation of different factors. The experimental search topics in the present study needed to accurately reflect realistic needs of science teachers. Eight video search topics were created. The interactive experiments utilized experimenter-developed search topics, a common approach employed by standardized interactive video retrieval forums, such as TRECVid. When developing the experimental search topics, it was ensured that relevant results were discoverable in the system’s collection, so it was possible for users to successfully complete all topics. These characteristics are consistent with prior human-computer interaction experimental protocols and models in that search topics have clear and achievable outcomes and strive to be representative to the context (Lazar et al., 2010, p. 269).
Individual topics themselves spanned textual, visual and hybrid (both textual and visual) features and included either singular (one) or multiple needs (more than one request). Data to support the validity of the experimental search topics were collected in an earlier pilot study asking users to rate how accurately the topics represented real information needs in science education. The averaged representation levels, or topic representation, for the individual pilot topics were shown to vary between 3.0 and 3.8, with an overall mean of 3.47 out of 5.0. Users’ familiarity with the search topics was also measured in the pilot study, which produced averages for individual topics between 3.2 and 3.4 out of 5.0, with a 3.28 mean overall. Such findings were considered appropriate and used to confirm or revise the final set of experimental search topics.
ViewFinder
A prototype Web-accessible video retrieval system named ViewFinder was employed for the present study. The ViewFinder prototype implemented for this study was designed to retrieve video clips from the NASA K–16 Science Education Programs. The NASA video collection used for the present study contained thirty-one hours of video with production dates ranging from 2000 to 2006 and comprised several NASA series including NASA Connect, NASA SciFiles, NASA Why?Files and Destination Tomorrow.
The search and browse features of ViewFinder included three basic functions: keyword search, clip (series, title and search results) browse and query by example. Dublin Core records for the NASA programmes enabled the title browse feature of the ViewFinder prototype, and video transcripts for all video clips were weighted with tf-idf in order to retrieve ranked keyword search results. ViewFinder also contained various visual search features, including searches by colour, shape, texture and the combination of each (a.k.a. all visuals), which were all implemented as a query by example feature, where a selected video clip, or its representative keyframe, was used to form the basis of the user query and return similar search results. A ‘details’ feature retrieved information from the transcript and bibliographic record for a particular search result (or video clip), upon request by users, which was displayed in a separate pop-up window.
Data collection and analysis
Search runs were monitored by the researcher and all actions performed by users were manually recorded, along with completion rates, for each search topic. The experimenter-assessed topic completion rate was the percentage of the search topic a user successfully completed. Errors, as performed by the users, were also recorded by the experimenter and coded as unmistakable incorrect queries or misuse of any interface feature or function of ViewFinder. System logs of all submitted requests and executed actions were also recorded, allowing the researcher to re-examine experimental data where needed.
After every attempted search topic, a post-search survey was given to the users, who then assessed a variety of factors, including satisfaction with the system’s functionality, user interface, primary interface features, the ease of searching a given topic and the extent to which they felt they completed the search topic (i.e., self-assessed topic completion). The post-search survey utilized a 5-point scale; 5 indicated maximum agreement and 1 represented disagreement.
Statistical methods were employed to analyse the experimental and post-search survey data. Descriptive statistics were computed and repeated measures ANOVA tests were run to examine significant differences between the groups of topic spots, i.e., topic placement within the order. Post-hoc tests with Bonferroni adjustments for multiple comparisons measured specific statistical differences within the significant repeated measures ANOVA tests, across the experimental factors and according to the topic spot of the order (e.g., where exactly the significant differences in users’ interactions, preferences and performances occurred in an interactive search experiment). Groups formed for the repeated measures ANOVA and post hoc analyses included the different spots in the order of the topics as performed by the users over the course of the interactive experiment or as the experiment progressed. The primary condition of the mean comparisons was (before/after) the specific spots in the order, with one sample (of users) performing a set of topics over different spots (1-6), throughout an interactive search experiment in order to measure variations among the experimental factors as a result.
Results
Results of the present study provide understanding of how both experimental data, collected by logging users’ actions when attempting a set of search topics, and users’ perceptions (e.g., satisfaction), as garnered through post-search surveys, varied according to a topic’s spot or placement in an experimental topic order. Results from the quantitative data analysis will be presented in this section and discussion of the implications of the findings will follow in the next section. The results of this analysis provide evidence that can help better understand users in an interactive video retrieval research context and thus inform the design of future experiments and user interfaces. Results that correspond to the experimental data and the post-search survey are presented separately and in turn in this section. Topic number(s) shown in the figures and tables correspond to the position in the topic order of the interactive search experiments, not any of the specific search topics, i.e., information needs, themselves. As fully described in the methodology, all individual search topics were equally distributed across all topic spots to account for any individual differences among topics or users.
User interaction and topic performance
There were significant variations across the spots in the topic order, among the different types of user actions, or interactions, with the ViewFinder interface and experimenter-measured topic performance. Figures in this section demonstrate the overall trends of such variations in the mean scores for each variable.
Figure 1 shows that as search topics progressed through an interactive experiment, the mean number of actions by users increased up until topic spot four, where actions peaked, then decreased again for topics five and six. These variations in the number of users’ actions occurred despite there not being any statistically significant time differences (i.e., durations) across the topic spots in the order, which ranged from a low mean of 2.4 minutes to a high mean of 3.25 minutes.
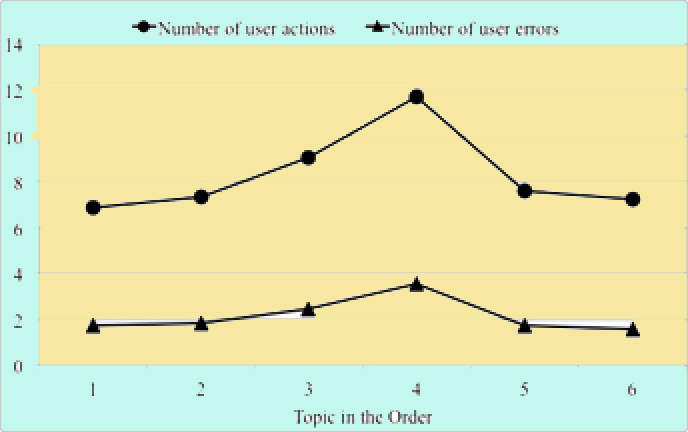
Figure 1: Mean number of user actions and errors (overall) across different topic spots in the order.
The number of actions was significantly different between the groups (i.e., different topic spots in the order), as shown by a repeated measures ANOVA [F(5, 135) = 2.657, p < 0.05]. Post hoc analyses with Bonferroni adjustments for multiple comparisons assessed individual differences among the number of users’ actions between the topic spots. Results demonstrated that only the fourth topic in the order (M=11.7, SD=8.63) produced statistically significant differences with other topic spots. Further, the number of users’ actions at spot four was significantly higher than the means for the first (M=6.86, SD=5.30), second (M=7.36, SD=4.93), fifth (M=7.61, SD=5.00) and sixth (M=7.21, SD=4.69) topics in the rotation. All differences were significant at the p < 0.01 level, except for the comparison between topic spots four and five, significant at p < 0.05. The mean number of actions performed by users at topic spot three (M=9.04, SD=6.97) was not significantly different than those for topic spot four.
The mean number of errors performed by users, presented alongside the overall actions in Figure 1, demonstrated similar relationships between the topic spots in the order, producing a statistically significant repeated measures ANOVA score of [F(5, 135) = 3.02, p < 0.05]. Topic spot four (M=3.54, SD=2.95), again, produced statistically higher means of user errors than for the topics at positions one (M=1.71, SD=0.70), two (M=1.82, SD=1.07), five (M=1.71, SD=0.68) and six (M=1.57, SD=0.55), respectively, and no other significant differences occurred across any other combination of topic spots, including between topic three (M=2.46, SD=1.77) and four. Once again, all comparisons between topic spot four and others were significant at the p < 0.01 level with the exception of the difference between topic spots four and five, significant at p < 0.05. This finding of error rates and their similarities with users’ actions is reasonable, as the number of actions and errors would be correlated; i.e., more executed actions ultimately would be more prone to further mistakes or errors of the users.
Considering significant differences were produced among users’ actions (overall) and rate of errors across the topic spots in the order, it would also be reasonable to detect similar patterns among specific (interface) feature use (or interactions with). Of the different interface features employed and analysed for the present study, statistically significant variations occurred for the use of two particular features, both of which were a type of browsing, including the programme series or title browse feature and the search results (page) browse. The general variations among the use of these different browse features were similar to the trend of the overall number of user actions; that is, there was a general increase leading up to topic four, then a decrease during the fifth and sixth topics in the rotation (Figure 2). A repeated measures ANOVA produced a significant result for both the title browse [F(5, 106) = 10.451, p < 0.01] and search results browse [F(5, 135) = 3.91, p < 0.01] between the different topic spots in the order.
Results from the use of the title browse feature demonstrated that the number of times used at the third (M=3.14, SD=1.60) and fourth (M=3.40, SD=3.00) spots were both statistically different at a level of p < 0.01 than several others in the topic order (but not with one another). Further, the title browse feature was used significantly more at these points in the experiment than the latter two topics, including at spot five (M=0.62, SD=0.23) and six (M=0.64, SD=0.78), yet not statistically different than use at the first (M=2.21, SD=1.76) and second (M=1.67, SD=1.49) topic spot. After the level of use at topic spot four, use of the title browse feature dropped off significantly. Search results browsing, or the number of pages browsed per topic, demonstrated that all of the statistically significant differences occurred between topic spot four (M=3.61, SD=3.28) and all others in the order at a significance level of p < 0.01, excluding topic spot three (M=2.32, SD=2.74), which was statistically insignificant with topic four. Results showed significantly higher levels of browsing search results at topic spot four in the order than performed during spots one (M=0.71, SD=0.23), two (M=1.25, SD=0.47), five (M=1.57, SD=1.28) and six (M=1.43, SD=0.65).
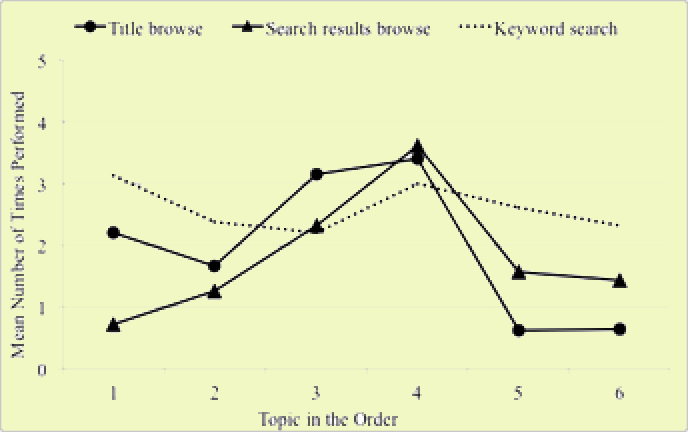
Figure 2: Mean number of user interactions with specific interface features, including title browse, search results browse and keyword search, across different topic spots in the order.
Variations among the levels of keyword searching, i.e., number of executed free-text queries, were not statistically significant across the different topic spots in the order. These results are still presented in Figure 2 to visually depict the trends among its use compared against that of users’ browse actions. Results showed how keyword searching was more consistent or unvarying in an interaction, regardless of situational factors and as overall numbers of users’ actions fluctuated, which has also been observed in other interactive video retrieval studies examining variations influenced by certain contextual factors, such as topic difficulty and prior knowledge of the users (Albertson, 2010; Albertson and Meadows, 2011).
Experimenter-assessed topic completion (Figure 3), i.e., the percentage of a topic successfully accomplished by a user as rated by the experimenter, also demonstrated statistically significant differences between certain topic spots in the experimental order, as produced by the results of a repeated measures ANOVA [F(5, 135) = 3.53, p < 0.01]. The mean completion rates, presented in Figure 3, are based on a scale of 0.0 to 1.0, with 1.0 being full successful completion and 0.0 representing incomplete. The statistically significant differences affirmed the trends apparent in Figure 3; the earlier topics, or those attempted in position one to four (1) M=0.68, SD=0.43; 2) M=0.70, SD=0.42; 3) M=0.70, SD=0.42; 4) M=0.66, SD=0.41), were significantly lower than completion rates achieved for both the fifth (M=0.88, SD=0.29) and sixth (M=0.91, SD=0.20) topic spots. Further, users’ rates of topic completion increased significantly as a search experiment progressed or continued. All significant differences occurring between topics one to four with those in spots five and six were significant at the p < 0.01 level.
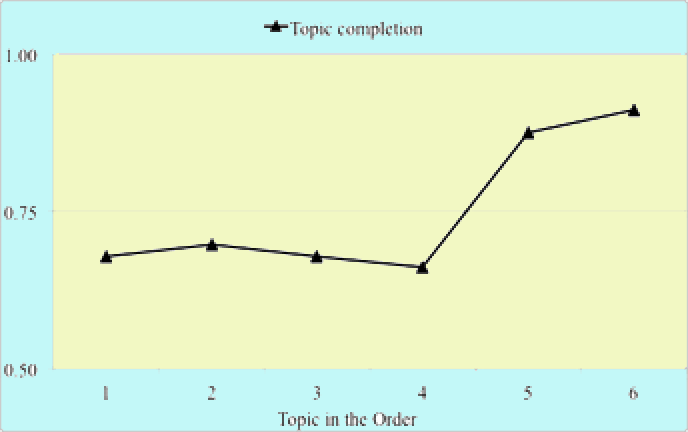
Figure 3: Mean topic completion ratios on scale of 0.0 to 1.0 across different topic spots in the order.
User satisfaction and other judgments
Figure 4 shows how a variety of users’ perceptions (e.g., satisfaction measures) of certain factors fluctuated as the interactive search experiments progressed from topic spots one to six. Users’ perceptions, as presented here, were taken from the post-search survey administered after every attempted search topic, whether successfully completed or not. This survey included asking users their perceptions for: 1) the supportiveness of the ViewFinder interface for facilitating topic completion, 2) the effectiveness of the search system in terms of generating useful results, 3) the ease (or, conversely, difficulty) of searching the given topic, 4) the usefulness of specific interface features, and 5) the level of self-assessed topic completion (to what extent they felt they completed the topic).
As visually apparent in Figure 4, variations across all of these measures for the different topic spots were similar. The general trend in the results was that users were more satisfied or had higher perceptions of the system, search effectiveness, user interface, keyword search, relative ease to search and overall level of self-assessed topic completion for the final two topics (Figure 4). Furthermore, users were more likely to rate higher levels for these factors in topics five and six than one to four (Figure 4). Table 2 presents specific mean scores and standard deviations for each of these measures across all the topic spots (one to six) in the order.
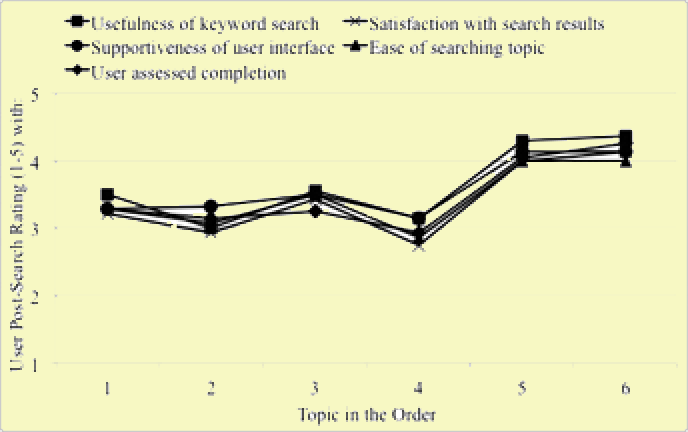
Figure 4: Mean scores of users’ perception ratings across different topic spots in the order.
| Measure | Topic 1 | Topic 2 | Topic 3 | Topic 4 | Topic 5 | Topic 6 |
|---|---|---|---|---|---|---|
| Supportiveness of the user interface | M=3.29, SD=1.27 | M=3.32, SD=1.44 | M=3.50, SD=1.26 | M=3.14, SD=1.18 | M=4.14, SD=0.93 | M=4.14, SD=0.93 |
| Satisfaction with returned search results | M=3.21, SD=1.50 | M=2.93, SD=1.61 | M=3.43, SD=1.57 | M=2.75, SD=1.51 | M=4.00, SD=1.33 | M=4.14, SD=1.01 |
| Ease to search | M=3.29, SD=1.36 | M=3.07, SD=1.49 | M=3.50, SD=1.43 | M=2.86, SD=1.38 | M=4.00, SD=1.22 | M=4.00, SD=0.94 |
| Usefulness of the keyword search | M=3.50, SD=1.53 | M=3.00, SD=1.73 | M=3.56, SD=1.70 | M=3.15, SD=1.64 | M=4.29, SD=0.94 | M=4.36, SD=1.03 |
| Users’ self-assessed topic completion | M=3.29, SD=1.63 | M=3.14, SD=1.72 | M=3.25, SD=1.60 | M=2.93, SD=1.59 | M=4.04, SD=1.32 | M=4.25, SD=1.01 |
A repeated measures ANOVA test detected significant variations for all of these perceptions across different topic spots (results of which are presented in Table 3). Each significant ANOVA was followed up with a Bonferroni post hoc test to examine specific individual differences between different topic spots in the order for each of these different perspectives of the users. The significance of such associations across all of these measures essentially demonstrated that earlier topics, or spots one to four, were statistically different than the latter topics, five and six, with a few exceptions. These notable exceptions included: no significant difference occurred between topic spots one and five with regard to the levels of user assessed topic completion, and topic spot three did not demonstrate any significant difference in users’ satisfaction with the search results and the relative ease to search the given topic with any other group (topic spot). Despite this, significant differences were mostly observed between earlier and later topics across all other measures. Statistically significant (and insignificant) associations across all comparisons and their level of significance between different topic spots are presented in Table 4.
| Satisfaction with search results | Ease to search | Interface support | Keyword usefulness | Self assessed topic completion | |
|---|---|---|---|---|---|
| Topic spots in the order | F(5, 135) = 4.90, p<0.01 | F(5, 135) = 6.32, p<0.01 | F(5, 135) = 4.75, p<0.01 | F(5, 120) = 3.42, p<0.01 | F(5, 135) = 5.13, p<0.01 |
| Topic 5 | Topic 6 | ||
|---|---|---|---|
| Topic 1 | Supportiveness of the user interface | p <0.01 | p <0.01 |
| Satisfaction with returned search results | p <0.05 | p <0.05 | |
| Ease to search | p <0.05 | p <0.05 | |
| Usefulness of the keyword search | p <0.05 | p <0.05 | |
| Users’ self-assessed topic completion | Not significant | p <0.05 | |
| Topic 2 | Supportiveness of the user interface | p <0.01 | p <0.01 |
| Satisfaction with returned search results | p <0.01 | p <0.01 | |
| Ease to search | p <0.01 | p <0.01 | |
| Usefulness of the keyword search | p <0.01 | p <0.01 | |
| Users’ self-assessed topic completion | p <0.05 | p <0.01 | |
| Topic 3 | Supportiveness of the user interface | p <0.05 | p <0.05 |
| Satisfaction with returned search results | Not significant | Not significant | |
| Ease to search | Not significant | Not significant | |
| Usefulness of the keyword search | Not significant | p <0.05 | |
| Users’ self-assessed topic completion | p <0.05. | p <0.01 | |
| Topic 4 | Supportiveness of the user interface | p <0.01 | p <0.01 |
| Satisfaction with returned search results | p <0.01 | p <0.01 | |
| Ease to search | p <0.01 | p <0.01 | |
| Usefulness of the keyword search | p <0.01 | p <0.01 | |
| Users’ self-assessed topic completion | p <0.01 | p <0.01 | |
Discussion
The results, as just presented, provide valuable insights into the research questions posed in the present study. Furthermore, the analyses as performed here lead to findings that can have a number of benefits on future video retrieval studies, particularly those that deploy interactive search experiments to further understand users and uses of visual information. Discussion about the more specific research questions, and findings thereof, are presented, followed by discussion of the contribution toward the broader research question. The first (more-specific) question raised in this study examined the potential effects of search topic progression on user actions and interactions. One finding from the results was that a learning curve appeared to have been influential to users’ actions overall and also to their interactions with browse features specifically. In the earlier topics, users were taking similar amounts of time (statistically speaking), yet executing fewer actions with the user interface, perhaps becoming acquainted with the system, the information need (search topic), experimental context and/or collection’s contents. Topic spots three and especially four showed that users began performing significantly more actions, particularly navigating the collection and browsing search results at greater depths. On the other hand, results of users’ use of the keyword search did not produce any statistically significant differences between the spots in the topic order. Offering a keyword search feature, shown to be universal across situational factors in interactive video retrieval contexts (Albertson, 2010; Albertson and Meadows, 2011), resulted in users employing it regularly, regardless of a topic’s spot, thus not producing significant variations in this particular analysis.
The primary practical insight or application for researchers stemming from this first set of results is that two search topics can be viewed as a possibility for system training and/or exposure, prior to conducting a formal search, to help offset effects or skew caused by a learning curve. This point is particularly applicable if research goals include evaluating natural or realistic use of video retrieval features that are more unique, warrant further user training or exposure, or require more knowledge about the context, domain or collection, such as a title browse of a domain-centric series, as in the case of this study. A keyword search feature, as demonstrated here, would not require as much exposure or contemplation even for interactive video retrieval experiments, due to almost universal familiarity, leading to consistent use, again, as observed here.
Another application for future research is that the topic spots beyond number four also appear to be affected by experimental factors, where actions dropped significantly, despite increasing levels of use and activity up through topics three and four. Therefore, researchers need to consider effects of prolonged search experiments, including both system learning and potential experimental fatigue, resulting in decreased interest over the course of an interactive experiment. This finding may be particularly applicable for experiments using unfamiliar system prototypes and/or experimenter-developed or mock search topics, as deployed in this study, i.e., not involving personal interests or job-related information tasks, thus resulting in variations in expended energy for learning and/or user interests in topic completion. In this study, at topic spot five, users started demonstrating changes in their interactions as reflected in the variations in the experimental results. However, it is also important to point out that search topic completion significantly increased for the final two topics of an interactive experiment, with fewer actions being performed overall by the users. This finding suggests the presence and benefit for system (and potentially) collection familiarity with users more effectively using the interface to discover relevant videos later in the experimental sessions.
In summary, findings from this analysis give researchers ideas to consider for collecting different levels or varying types of experimental data about users’ interactions as part of search experiments. Some topic spots showed that users were motivated and/or interested in learning the system enough to execute more actions overall and navigate collection boundaries more thoroughly and browse larger sets of search results. From this analysis, findings indicate that researchers can garner representative data, or those which may be more indicative of realistic interactions from users who are both interested and experienced, at certain points within an experimental context.
The next research question of the study examined influences on user perceptions, mostly levels of user satisfaction. Findings from this analysis are further useful and applicable if researchers assess usability and, more specifically, its basic metric of user satisfaction with a user interface. Results showed that users were more satisfied (with a brand new system) after a few experimental search topics. This outcome is significant as researchers may strive to evaluate satisfaction among users who are more familiar with a system, or those with expectations about its use and/or contents of a digital video collection. Conversely, earlier topics may be helpful for garnering findings or opinions from inexperienced users for potentially identifying surface issues or concerns of a video retrieval system. Furthermore, as evident here, researchers can design interactive studies with complex or multi-component user interfaces and still be capable of assessing satisfaction among users with adequate levels of system experience in short experimental sessions.
Trends across all user-assessed measures, i.e., their perceptions, depict almost identical variations, suggesting that the basic metric of satisfaction, generally speaking, was more of an individual variable demonstrating significance for interactive search experiments. Considering variations were all virtually the same, typically, if users were satisfied with one feature, they were satisfied with all the others (even if they did not employ something on a given topic). This finding gives researchers data about how subjective factors, in a sense, comprise one variable; therefore, researchers need to consider how to garner satisfaction of specific individual features or aspects of a system using other types of follow-up analyses.
Implications
The findings of the present study can be applied tp designing future studies, spanning different contexts, with demonstrated potential to yield targeted research data from interactive search experiments. Such a contribution is significant, as interactive experiments with users will continue to be employed, thus further understanding of such methods is warranted. Furthermore, results of the present study demonstrated variations, including among users’ actions and perceptions, as the number of search topics progressed over the course of an experimental session. These associations serve as validation and insight into certain design aspects and considerations for interactive video retrieval experimentation, such as those involving learning curves and other influences at specific points in prolonged experiments. While findings could be different in subsequent follow-up studies, based on the context of research being conducted, ideas for modifying future experiments stemming from this study can be considered. Future studies can be provided points in interactive experiments on which to potentially focus or emphasize, based on the goals of the particular research, such as when certain levels of learning and/or exposure have occurred, whether high or low, in order to evaluate different metrics, including effectiveness, efficiency, satisfaction and actions across different types of users.
Implications and benefits for future experimental design can in turn mutually contribute to understanding and enhancing interactive video retrieval interfaces to counterbalance effects of search (session) progression in both real-life and experimental situations. Insights from the results of the present study provide findings about users’ interactions at a finer level of specificity, including with certain interface features, than general measures like user / topic performance. Further, keyword searching has been shown to be a consistent user interaction with video retrieval systems across different analyses, comparisons and contexts, while video browsing, or use of different browse features, has been shown to vary across situations involving different levels of user knowledge, familiarity and/or adversities (Albertson, 2013). Results can suggest optimal opportunities to emphasize or highlight browsing in interactive retrieval situations for supporting users’ inclinations to navigate collections, including during exploratory use of user interfaces, where users possess interest and also an initial level of learning/experience. Also, for example, users may show inclinations to browse search results, not only video collections, at different depths at certain points as learning occurs and experience grows, which provides insight about both keyword searching and browsing behaviours together, and thus interface design.
Satisfaction of users and other perceptions involving success (or failure) in finding video content can also vary at certain points. As presented in the results of this study, such measures of users’ perceptions tended to increase later in an experimental session. Future research and development can be further informed about how to enable higher rates of satisfaction across different types of users through the user interface and/or system functionality of interactive video retrieval systems, e.g., how to satisfy novice users and maintain interest via recall of video or conversely providing desired accuracy or precision for more experienced users to reinforce confidence and repeated use. It is also important to keep in mind how fatigue can affect users’ performance and perceptions in search experiments; results of the present study can be utilized to indicate particular points in search situations that demonstrate potential to improve levels of performance and thus user satisfaction by, again, focusing on what users deem useful and use as sessions progress. According to the results of this study, query reformulation and/or refinement search features, for offsetting both potential fatigue and user learning effects, could then be emphasized, as opposed to in-depth browsing and navigation of video collections and search results sets.
These implications as presented are considered approximate and, therefore, present some variations among different contexts and thus limitations for complete application of findings universally. However, such is natural in human-computer interaction research and should not detract from the potential positive implications stemming from the results of the present study, which demonstrates certain influences of topic progression in interactive video retrieval experimentation.
Limitations and future work
While value for interactive information retrieval experimentation has been added through the findings of the present study, there are certain limitations, which present opportunities for continued research. Additional research can strive to further understand the implications of interactive information retrieval experimental designs. Reasoning behind some of the observations and outcomes of the present study can be isolated and examined more rigorously. Inquiry into why certain trends occurred across users’ interactions and preferences could contribute significant additional insights for future research and also further support the discussions of the present study. Qualitative approaches, specifically, would be beneficial in follow up studies, which have been expressed as being significant for collecting data about why certain occurrences were observed in interactive video retrieval (Christel, 2009).
For example, results presented here showed that as users’ exposure to the system increased, over the course of multiple search topics, significantly higher levels of topic completion were produced, most notably for the last two topic spots, even though statistically similar amounts of time were being taken along with a decreased number of actions. It would be beneficial for future research to expand upon the factors and/or influences behind this finding. Effects of fatigue or disinterest toward the end of the experiment were observed from users; however, other phenomena may have also occurred, not necessarily a result of user disinterest, but maybe to the contrary, such as some users further contemplating more precise and effective search strategies, or using the system more efficiently. Furthermore, users also rated their satisfaction with the different experimental variables significantly higher during the latter topics, which could, again, be tested further in order to examine if this outcome was a result of a prolonged experimental session, increased experience with the system or contents of the collection, adjusted expectations of the user interface or search capabilities of the system, or any other factor.
In regards to the perceived learning curve, again, additional aspects could be further examined. For example, in the case of this particular experimental study, do the (high versus low) means achieved for certain topic spots, such as where users’ actions and browsing peaked, reveal anything further about a learning curve? Additional analyses could be expanded to include complementary methods, such as interviews with users or other exercises, designed to make users think in more depth about the individual features and differences, again, to further inform experimental designs and outcomes.
Next, examining other contexts with similar research questions would provide further perspectives, explanations and/or contrasts with the results of the present study. Here, results have been analysed across different factors within one experimental study, which examined users conducting the same topic search set (across different rotations) in the same type of setting. Additional analyses would give comparative data to assess if both users’ actions and satisfaction, as reported, are more variable or similar in a larger or more natural context spanning different situations. In addition, this study employed one experimental session per user, not a longitudinal study, which would lead to higher experience with a system and perhaps contrasting or complementary findings among users’ interactions, judgments and/or topic performance. Thus, as findings of the present study were generated only through the perspective of an experimental context, one potential limitation would be that findings of this study are applicable to other interactive information retrieval research employing similar methodologies. Ability for the results of this study to scale to a wider range of retrieval studies, such as those that evaluate actual users in realistic settings over longer periods of time, cannot be assumed. It would be interesting and significant to see how results vary from an experimental context to others that incorporate users with actual personal information needs, even perhaps those intended for social (media) information.
Also, additional effects potentially corresponding to the structure or makeup of video can be examined in future or follow-up studies. Video is a complex information resource, thus retrieval tasks can comprise multidimensional needs, based on the structural components of video and its time-based format. Video retrieval can involve users contemplating, retrieving and assessing video using combinations of visual, textual and/or audio information. Therefore, a range of experimental variables can be devised accordingly, using information needs with varying complexities, systems with different levels of indexing (i.e., semantic gap situations), interfaces with different expressions of visual information, surrogate designs for visual tasks or contexts, and others (Christel, 2008b). Factors such as these can again influence outcomes.
Therefore, comparisons with similar studies experimenting with other types of information, such as interactive studies using textual retrieval systems, could examine effects of independent experimental variables on how users query, retrieve and assess information. Users who assess video information ultimately need to watch time-based audio-visual content, which is different and typically more time consuming than reading snippets of textual information provided in sets of search results. On the other hand, with thumbnails, users can efficiently scan large areas of video collections and/or search results to assess relevance for visually-oriented tasks (Christel, 2008a), which again can contrast with the use of textual retrieval systems in certain contexts. Considerations such as these, and others, form a basis for drawing interesting comparisons between effects caused by certain experimental variables and designs on influencing others throughout interactive retrieval experiments.
Future research, such as suggested, could contribute more answers to the primary and overarching research question of the present study. While variations and influences about topic progression in video retrieval experimentation were observed across several dependent variables, further research would be able to build on these findings to improve and verify experimental designs for interactive studies.
Conclusion
The findings of the present study can have a range of implications on future interactive retrieval experiments. While topic ordering has been a deliberate experimental design consideration, the potential influences thereof have not been directly tested or thoroughly explained, particularly in a video retrieval context, beyond preliminary and general assumptions of effects of a learning curve and experimental fatigue. Results of the present study provide informative and targeted research about variations among users’ interactions and perceptions in continued search situations, which also in turn inform practical aspects of designing future experiments and user interfaces. While the findings provided here may not scale precisely for application across all future experimental studies and contexts, as each will have different research goals, they do provide further explanations and a baseline to consider as part of the design process. Researchers can utilize findings of this study to understand more about what to potentially focus on, emphasize or even exclude throughout the methodology of an interactive study, including those that strive to examine users with different levels and types of prior experiences (i.e., novice versus system expert).
Acknowledgements
I thank the anonymous Information Research reviewers for feedback.
About the author
Dr. Dan Albertson is an Associate Professor at the School of Library and Information Studies, University of Alabama. His primary research interests include interactive information retrieval and human information interaction with emphasis on visual information and digital video. He can be contacted at dea@ua.edu.