Proceedings of the Eighth International Conference on Conceptions of Library and Information Science, Copenhagen, Denmark, 19-22 August, 2013
Short papers
The integration of folksonomies within a thesaurus in a social science Web portal: SIDBRINT
G. Masó-Maresma and M. Sebastià-Salat
Faculty of Library and Information Science of the University of Barcelona. Melcior de Palau 140, 08014 Barcelona, Spain
Introduction
Nowadays, personalization technologies like social tagging interlink users and information systems in specialized Web Information platforms. This way, users are responsible for feeding specialized Websites and these are not only information consumers, but also prosumers that not only use the Website but also participate in its construction. It is in this context where folksonomies have begun to appear since Thomas Vander Wal defined them Vander Wal 2012) in 2004, and users are prosumers as they are responsible for indexing and retrieving content from their points of view.
The aim of this paper is to explore how a specialized social science Web portal will interrelate traditional or controlled information retrieval systems, such as the thesaurus, and systems based on user behaviour, like that of folksonomies, since there are few examples of that kind of digital system in social science Webs.
This specialized Web portal is called 'Digital Information System on the International Brigades and the Brigades of the Spanish Civil War', from now on SIDBRINT, and is part of the project 'Historical Memory and the International Brigades: the Design of a Digital system for the Transfer of Spanish Heritage Knowledge', whose aim is to become the first digital system on the International Brigades and Brigade Members of the Spanish Civil War.
The SIDBRINT portal
The recovery of the historical memory on the Spanish Civil War highlights the need to develop information systems that support the identification, processing, indexing and retrieving of historiographic sources for research, teaching and reconstructing the past. Hence the reason why the main goal of the project is to ensure digital identity, visibility and accessibility of the sources that exists for this unique phenomenon in Spain's contemporary history.
The historical hypothesis is based on the premise that many of the brigade members and many of the brigades themselves only 'exist' historiographically given that they were connected to a foreign army that fought on the Republican side to defeat fascism. This digital system endeavours to answer questions beyond the history of the individual and the collective, involving the personal or anonymous historical accounts of the brigades and brigade members. To answer such questions, SIDBRINT must delve deeply into the documentary sources, making use of them and especially accessing their content.
SIDBRINT is structured in four main databases: the Bio-bibliography of the Brigade Members; Military Enlistment; Documentary Sources; and Quality Digital Resources. All these databases will shape SIDBRINT and will be interlinked through the digital system.
In order to help the users of SIDBRINT to search the content in the digital system, a thesaurus will be created specifically for that, containing all terms included in the four aforementioned databases. The goal of this project is to go some steps further, and that is why we also integrate social tagging –folksonomies- in the digital system. Our aim is not only that users will be able to search for the content in the digital system, but also to participate in the construction of same. Their participation will be useful not only for constructing a folksonomy-Web-system, but also in helping the construction of the thesaurus integrated within it. This way, folksonomies will not only be a retrieval information system in itself, but also a tool in the construction of the specialized thesaurus.
The users of the digital system SIDBRINT
The digital system will ease the work of the researchers of this specific area of the Spanish and European Contemporary History. As there is a lack of a similar digital system created to date, we are sure that historians are going to be the principal users of SIDBRINT. Therefore, we need to know what other types of users (Masó-Maresma and Écija-Sánchez 2012) of the digital system exist. It is important to point out that the International Brigades are an essential element in the contemporary history of Spain, Europe and worldwide. Hence, this is one of the reasons why users interested in this type of information are very diverse, and some for just personal or emotional grounds (Prades-Artigas 2012). In the first study carried out during 2011 on the type of real users of the digital system, the following four groups were encountered:
- Professional users: within this subgroup, we found historians as the most common user type together with journalists, sociologists and political scientists, museologists, writers and filmmakers.
- Emotional users: those volunteers that are still alive, and also their families.
- Info-users: information professionals: archivists, librarians, and database managers in the field of history and conflict.
- General users: people interested in the topic for several reasons (training, research, homage, and empathy with social history).
It is essential to determine which kind of user will use the digital system, since they will become the folksonomy-builders. This involves determining the tags that they deem to be relevant in order to retrieve and look for a specific piece of content in the digital system, and they will also help to create, develop and maintain the thesaurus.
The SIDBRINT thesaurus
The thesaurus of SIDBRINT reflects the overall historical Web portal taxonomy and contains the history on the Spanish Civil War and International Brigades and integrating the aforementioned databases: Bio-bibliographies of the brigade members; Documentary sources; Researchers and research groups; Military enlistment; Bibliography on the international brigades and brigade members; Web resources.
The matrixes of the thesaurus are the fields of controlled vocabularies of the digital system, which can be found in the aforementioned databases. First of all, controlled vocabularies and classification schemes were identified in order to develop and respond to the fields of the database project, as they represent the content included in the four main databases.
The thesaurus is presented in the SIDBRINT digital system with a thematic taxonomy regulated by a browser which will have two interfaces: simple and advanced search. The simple search will let users search any term included in the whole digital system, whereas the advanced search will be used to enclose the search terms interrelating them. Thus, it will be possible for a user to search for a specific term, and at the same time to limit it for a concrete year, type of document, among other fields. The advanced search will be implemented by chronological, geographical, historical, and also by sociological concept filters.
To sum up, the thesaurus is built from a thematic taxonomy, having a browser which includes basic and advanced searches, and its vocabulary is portioned into a set of main classes. Hence, there will be three major interfaces for the information retrieval:
- Simple search: the user enters one or more terms in order to execute the search.
- Advanced search: the user enters one term in every field and can combine them by Boolean operators, as well as narrowing the search to different fields.
- Main tag cloud (including tags from folksonomies): the user browses through the tag cloud in folksonomies which were previously introduced by other users.
The documents found from the search will be shown in the results pane, and on the left hand side of the screen the user will be able to see the related terms of the thesaurus categorized by the taxonomy.
A selection of software for editing and managing controlled vocabularies was proposed and based on Drupal 7.0. This version allows the managing of the Semantic Web for the digital system, as well as a Multilingual thesaurus. In the future, this thesaurus will also be available in Spanish, Catalan, English and German. Our goal is that the user will be able to search through the Cross Lingual Information Retrieval any term or a phrase and its variants in the aforementioned languages. With Apache Solr Multilingual for Drupal 7.0, this will be possible, although we have not yet implemented it. Given the fact that this is an ambitious project, the creation of the thesaurus will first of all begin in Catalan, as most of the content is already in this language.
The requirements of the thesaurus' were based on paragraph 14th of the Guidelines for thesaurus management software from standard ISO/DIS 25964-1 (National Information Standards Organization 2009). Those were complemented with paragraph 11.4th 'Management systems' from ANSI/NISO Z39.19-2005 National Information Standards Organization (2013) and also for specific requirements of the SIDBRINT project. During the creation of the thesaurus, all those aforementioned guidelines laid out will be reviewed and updated, in order to ensure the quality and feasibility of the terms, as well as the concepts and structure of the Multilingual thesaurus.
The method we will use in order to evaluate how users manage the controlled vocabulary within the thesaurus, and which is the opinion and degree of satisfaction of the same, will be through the use of questionnaires and Web crawler applications. The use of questionnaires will be relevant in that it will allow us to know which is the degree of satisfaction of users when using the thesaurus. These questionnaires will be evaluated electronically and in this way users will have the possibility to respond to them through the digital system. Our intention is to obtain the quickest user feedback, with the least inconvenience for the respondents. We will establish a calendar in order to see the grade of improvement both of the thesaurus and its users. This means that each time we analyse the results, we will make all the necessary improvements and then users will be consulted again in order to know if with these new improvements they noticed any progress when searching within the thesaurus. This will be done during the implementation process, so it will not take more than twelve months from the beginning of the process.
The use of Web crawling will be to know the grade of satisfaction of the thesaurus regarding the controlled vocabulary. So, this will be a method of users' study that will inform how users click on the content in the digital system and ask for information included in it. A Web crawler is a software application that downloads documents from the Web and stores them locally. The process of downloading is sequential where the crawler will extract the outgoing links from every downloaded document and schedule these links to be fetched later according to the crawling policy (Khabsa 2012).
We decided to use a Web crawling method as it has been studied that recent open free network visualization tools have made the qualitative analysis of large social networks easier, and based on these tools, scientists in humanities (such as the SIDBRINT research group) can visualize large relational data which lead to a new hypothesis that will require further network crawling and data extraction (Khabsa 2012).
Fruit of the questionnaires and the Web crawling, from a percentage not exceeding 50% lower by the user, we would evaluate and carry out the same studies for the free tagging, folksonomies. It means that for information retrieval systems based on controlled vocabulary, the thesaurus, we will measure the grade of dissatisfaction by the user from 50%.
To sum up, our aim is to study the route that a user executes when asking for information within the digital system. If this is not satisfactory, he/she must rethink the search. It is in this moment when the decision is not to search within the controlled vocabulary, the thesaurus, and to switch to social tagging, folksonomies. That is the reason why the SIDBRINT digital system has both indexing systems: controlled and free vocabularies, the thesaurus and folksonomies.
Integrating folksonomies in the digital system SIDBRINT
In order to assess, share and navigate (Park 2011) through the content in the SIDBRINT digital system, we propose the integration of folksonomies within the thesaurus. It will also make it easier to find a core point for the tagging, as well as to ensure consistency and increase the number of access points in retrieval (Golub, Koraljka, et al. 2009). We assume that a folksonomy is by no means in opposition to controlled vocabularies, and the development and the updating of the thesaurus will benefit from tagging, since it provides a rich source of authentic term material (Stock 2007), and this is what we would like to gain from users or prosumers of the digital system. The aim of the digital system is to be designed in a way that users will be comfortable and feel it as theirs not only as a historical resource but also a tool to be created by them. As designers of the SIDBRINT digital system, we must design a platform that accommodates users from diverse subject areas, as described before.
The interaction between users and the digital system was found to be crucial so their collaboration will be necessary in order to retrieve and improve the system to search the content included in the digital system during all its construction there, given that the process of indexing is a never-ending task.
As noted by Vander Wal, there are two kinds of folksonomies: broad and narrow folksonomies. In a broad folksonomy, different users may tag the same piece of information, so there is a document-specific distribution of tags whereas in narrow folksonomies, attached tags are recorded just once (Stock 2007). Although the folksonomy prototype has not yet been implemented, we are committed to a model of broad folksonomies; this way, users can select a pre-defined folksonomy by using their own criteria.
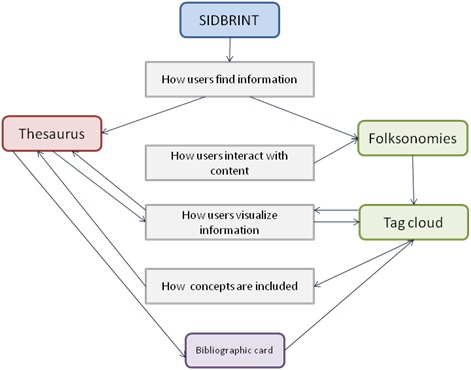
Figure 1, below, shows how from the very beginning, users can find information in the digital system. Users will be able to choose between two systems: thesaurus and folksonomies, and one system should not be independent of the other, or, at least, this is our goal. Users can only interact with content through folksonomies. They propose one or several terms for the selected content from the digital system, they then name it, and finally it is included in the tag cloud. This content is named based on user experience or belief, and it can then be visualized and retrieved through the tag cloud. How users can visualize information or content may be through the thesaurus or the tag cloud. Viewing it from the thesaurus means they have to navigate through the hierarchical taxonomy of the digital system, and viewing it from the tag cloud means that users can only see the content tagged by themselves or other users of the digital system. Highlighted content of the tag cloud are those terms that have been more tagged than others. One of our goals is to be able to move from the thesaurus to the tag cloud, and vice versa. Thus, users can see if the content selected by them can be retrieved and if it can also be incorporated in the whole Taxonomy.
And last but not least, we propose a method of how concepts are included in the whole Taxonomy in the digital system, and how it could be possible to retrieve content through controlled vocabularies, accepted terms from the thesaurus, as well as concepts included by users through folksonomies. This will let users get all the information related to a specific field of content included in the bibliography card built for the thesaurus, and also retrieve through the concepts in the tag cloud if they match. That means that if a tag is included both in the thesaurus and also in the tag cloud, users may see the bibliography card.
Conclusions: future research
There are a few examples of integrating folksonomies in social science Web Portals and one of them is related to museums, Steve Central: Social Tagging for Cultural Collections, but we have not yet found anything similar to our project. However, projects such as 'Enhanced Tagging for Discovery (EnTag)' have also integrated folksonomies within a thesaurus as an information retrieval system, and have researched well the concept of social tagging with suggestions from a knowledge organization system in a user trial with existing retrieval applications, comparing social tagging and enhanced tagging (UKOLN 2008). In this way, we want to continue the research done by EnTag, including a multilingual thesaurus created from and for cross lingual information retrieval.
The main goal of SIDBRINT is to become a digital system founded by professionals, but maintained and enriched by users/prosumers. All the content included in the digital system will not only be from historiographical sources, but also from users who will share and collaborate through providing their knowledge and references within the digital system. As it was explained before, both indexing systems controlled and free vocabularies, the thesaurus and folksonomies, will help users to find all the information included in the digital system. When controlled vocabularies are not able to satisfy user needs, free tagging will help users to find what they are looking for. This way, both systems will help each other, and that is the reason why we think it is important to maintain both, because one cannot exist without the other as they complement each other.
We are currently working on deciding which will be the best software for implementing folksonomies in the digital system, so once this will be built, the presentation of the folksonomy prototype will be done.
You can access to the digital system through the following address: sidbrint.net
Acknowledgements
The SIDBRINT digital system is funded by the Spanish Government, and it is included in the following project: Historical Memory and the International Brigades: Design of a digital System for the Transfer of Spanish Historical Heritage Knowledge. Main researcher: PhD Montserrat Sebastià Salat. R+D+I Project. National Plan, 2010-2013. (Ref. HAR2010-20983).