vol. 15 no. 4, December, 2010
vol. 15 no. 4, December, 2010 | ||||
Webometrics, the quantitative study of Web-based phenomena (defined more precisely later) was born in 1997 (Almind and Ingwersen 1997) and was driven rapidly forward by a number of pioneering researchers and investigations (Aguillo 1998; Bar-Ilan 1999; Ingwersen 1998; Rodríguez and Gairín 1997; Rousseau 1997; Smith 1999) to establish itself as apparently the largest coherent field within library and information science (Åström 2007; Zhao and Strotmann 2008). There were three main directions for early research: link impact evaluation, link relationship mapping and search engine results analysis.
Link impact evaluation studies typically identified methods to count the number of hyperlinks to sets of academic-related Web sites or pages (e.g., universities, departments, open access journal Web sites) and evaluated whether the number of links found could reasonably be used to indicate the research impact of the target site or page (Ingwersen 1998; Smith 1999). The idea that counts of links to a Web site or page could indicate its research impact derived from hyperlinks being structurally similar to academic citations and the reasonable belief that a Web page or site targeted by many hyperlinks may well contain valuable information. This was principally encapsulated in Ingwersen's (1998) Web Impact Factor, the main variant of which defined the Web impact of a page/site/space as being the average number of links received per page from outside of the space measured. Despite the attractive simplicity of this impact factor and numerous studies using it and developing alternatives, the discovery that UK university Web sites attracted links in proportion to their size rather than the quality of information in their individual pages seriously undermined the main variant (Thelwall and Harries 2004) and it does not seem to have been used in webometric applications. In addition, studies of links to journal Web sites seem to have disappeared, probably because most journals now seem to have publisher Web sites, many of which have complex URLs that are difficult to use in webometrics. Studies of links to sets of whole university Web sites continue to be popular, but mainly outside of the developed nations (e.g., Kousha and Horri 2004; Qiu et al. 2004), perhaps because emerging academic Web spaces are more interesting.
Link relationship mapping investigations typically chart a coherent set of academic Web sites in two dimensions, either as a network diagram or as coordinates in a two-dimensional space using multi-dimensional scaling. The similarity measures used to construct the diagrams are either the number of links between pairs of Web sites or co-inlink counts: the number of Web pages linking to both target pages or sites (Björneborn and Ingwersen 2004). Early studies all mapped sets of university Web sites within a country or within Europe (Boudourides et al. 1999; Thelwall 2002) but later projects obtained more interesting results by mapping smaller-scale academic units, such as departments (Heimeriks et al. 2003; Li 2005; Tang and Thelwall 2003) or by mapping themed collections of commercial Web sites (Vaughan and Wu 2004).
The third early type of research, search engine results analysis, had the objective to assess the comprehensiveness and consistency of commercial search engine results, either because of their use for the raw data in much webometrics research or because of their wider importance as an information retrieval tool by Web users (Bar-Ilan 2004). Perhaps surprisingly, given that a significant minority of the planet's population uses Web search engines, this type of research has not expanded by has continued at a low, steady rate (e.g., Bar-Ilan 1999; 2004; 2004; Mettrop and Nieuwenhuysen 2001; Rousseau 1999; Uyar 2009a; 2009b; Vaughan and Thelwall 2004). Note that this area contains many individual papers by people who many not consider themselves webometricians but the papers can be regarded as webometrics in the bibliometric sense that their citations are predominantly from other webometric papers.
Later webometrics research included many studies of visualisations (Ortega et al. 2008; Ortega and Aguillo 2009) and covered an increasing variety of topics, such as longitudinal quantitative studies of Web pages (Koehler 2002; 2004), Web citation analysis (Kousha and Thelwall 2006; 2007; Vaughan and Shaw 2003; 2005), blog analysis (Smith 2007; Thelwall et al. 2007), business Web sites (Vaughan 2005; Vaughan et al. 2009), digital library analysis (Zuccala et al. 2007), information retrieval factors (Jepsen et al. 2004), social network site investigations (Ackland 2009; Thelwall 2008) (although these may not be seen as part of webometrics) and theoretical contributions (Bar-Ilan 2001; Björneborn 2006; Björneborn and Ingwersen 2004; Fry 2006; Thelwall 2006). Despite the bibliometric studies suggesting the importance of webometrics to information science (Åström 2007; Zhao and Strotmann 2008), it may soon be surpassed by other emerging topics, such as the h-index or Web 2.0, and so it is a suitable time to conduct a review of the field in order to assess whether it is delivering enough useful knowledge to safeguard its future within library and information science. More specifically, since arguably only search engine evaluation seems to offer value to general information science goals - because it is relevant to Web information seeking - this review focuses on applied webometrics. The objective is to survey current applications of webometrics in order to assess whether webometrics has long-term viability as a research field. The belief underpinning this is that new fields within library and information science, as a professionally-oriented discipline (Whitley 2000), are likely to whither and die without clear applications. From a wider perspective, this may shed light on the normal process of the birth and death of research fields and suggest reasons why particular fields can be successful or not.
Research fields or specialisms within a discipline are difficult to precisely define due to changes over time in topics and personnel and a lack of organised groupings and journals (Becher and Trowler 2001: 67). In addition, the perspective taken is important: is a field defined by the topic, the people who identify themselves as part of the field or by citation structures? A precise definition is essential here because of the need to identify applications of webometrics in other fields. The original and dominant definition of webometrics is, "The study of the quantitative aspects of the construction and use of information resources, structures and technologies on the Web drawing on bibliometric and informetric approaches." (Björneborn and Ingwersen 2004), and a later proposed definition is "the study of Web-based content with primarily quantitative methods for social science research goals using techniques that are not specific to one field of study" (Thelwall 2009).
If webometrics was defined to be the relevant works of people identifying themselves as to some extent webometricians then this might be restricted to information scientists like Aguillo, Almind, An, Barjak, Bar-Ilan, Björneborn, Fairclough, Fry, Harries, Heimeriks, Holmberg, Ingwersen, Kousha, Kretschmer, Lamirel, Li, Ortega, Payne, Prime, Rousseau, Smith, Stuart, Thelwall, Uyar, Vaughan, and Wilkinson, all of whom have first-authored a webometrics article. This would exclude the works of computer scientists and physicists that have conducted large-scale quantitative Web analyses, including the hyperlink power law research of Barabasi et al. (Barabási 2002) and the longitudinal search engine evaluations of Microsoft researchers (Fetterly et al. 2003). Similarly, it would exclude computer science "Web metrics" research that includes Web page similarity measurements and usage information (Dhyani et al. 2002). These exclusions could potentially also be argued for on a topic basis using the second webometrics definition since the more abstract research seems to lack a real social sciences goal. One area that would be excluded is sociology research using Richard Rogers' IssueCrawler link analysis software, which is a type of link relationship mapping but seems to have very little interaction with webometrics, at least in terms of shared citations. A number of studies have also investigated politics-related hyperlinks, such as relating to Korean politicians' blogs (Park et al. 2001), US election-related blogs (Foot and Schneider 2006), and extremist Web sites (Ackland and Gibson 2004). These would be excluded, even though some of the authors may regard themselves as webometricians, as they are not primarily information scientists. This is a grey area, however, due to the overlap between library and information science and communication science (Paisley 1984). The current study is concerned with webometrics as an information science field and hence with research that is concerned with quantitative Web analysis and is conducted by information scientists identifying themselves as at least partly webometricians. This excludes the computer science, physics and sociology research discussed above but includes work by information scientists that might not consider themselves to be webometricians.
The next task is to identify applications of webometrics. Applied science has been defined to be research that is 'directed towards a specific practical aim or objective' (Stokes 1997: 65) but this definition is inadequate here. There seem to be two clear-cut criteria that could be used to identify applied information science research, however. First, paid research conducted for an external organisation desiring scientific outputs is necessarily to some degree applied. Much information science applied research seems to fall into this category, with the scientific outputs probably tending to be commissioned reports. Second, information science methods used in other disciplines, even if for theoretical purposes, have applications in the sense that they are aiding an external endeavour. This criterion is relatively clear cut in the sense that it could be operationalised as published research cited outside of the recognised library and information science literature. A third type of value for a field would be in becoming core knowledge or competence within this discipline. This is applied in the sense of educating the profession to do its job. It is less clear-cut, however, because even if extensive teaching of a topic was a practical metric, academic degrees necessarily contain a quantity of theory. As a result, in the current study, only the first two criteria are used to operationalise applications of webometrics.
There are many different ways in which research can be said to have impact. For example, a survey of health related research found four different types: future research; service changes; policy changes; general societal value (Kuruvilla et al. 2007; 2006). Of these, the final one is arguably the most important but the hardest to measure: in contrast future research impact can easily be estimated (Moed 2005) or argued for (e.g., Charness 1992) through citations, service changes could be measured by surveys and policy impacts could perhaps be estimated through surveys or citation analysis of policy documents. Others have emphasised the importance of research at times of key decision making (Lavis et al. 2003). In general, however, it seems clear that it is reasonable to assess a range of indicators of success other than the (arguably) final societal impact goal of modern research.
Studies of the impact of an individual scientific field often take a narrow perspective, such as evaluating key journal impact factors (e.g., Wikström 2009), which is not appropriate for webometrics since it is published primarily in general library and information science journals. Although there have been many investigations of research applications (Cohen et al. 2002), these seem to take the narrow perspective of seeking specific non-academic uses (Estublier et al. 2002; Sherman and Cohn 1989) and no previous study seems to have evaluated an entire field for applications and hence new techniques were needed. Two methods were used to identify applications of webometrics: citation analysis and a survey of active webometrics researchers. A third method was also used to identify cases where webometrics could have been used but was not.
The citation analysis method sought to identify published articles that were not in library and information science journals but which cited webometrics research. The library and information science discipline has been identified as not widely cited by other disciplines (Tang 2004) and so citations from outside are particularly valuable. Papers citing webometrics research were sought using Scopus rather than the Web of Science, due to its superior search facilities for this purpose and adequate coverage of the topic area. The following process was used.
The above steps gave 461 citations that were apparently non-information science articles that cited webometrics research. Note that self-citations are included in the sense of studies published outside library and information science in which at least one author cites their own work. These were then manually classified by topic and discipline and qualitatively reviewed.
The survey of webometricians was conducted by e-mailing all people in the list above, except for those already at Wolverhampton (Fairclough, Harries, Payne, Price, Stuart, Thelwall, Wilkinson) or deceased (Almind). Each e-mail requested information about any funded research they had conducted using webometrics, other than research council-funded research (see Appendix 1).
The third approach is to identify articles that could potentially cite webometrics but do not. These studies therefore bypass webometrics either through not knowing its contribution or by regarding it as unimportant. This section focuses on link analysis through keyword searches for "hyperlink analysis" and "link analysis" in Google Scholar and discarding articles citing webometrics research. Google Scholar was used, despite its limitations in accuracy (Jascó 2005; Mayr and Walter 2007), to get wide coverage of different disciplines
The answers from the e-mail survey about externally-funded webometrics research were combined by apparent type to facilitate discussion. Each section below discusses one type.
It seems that only one main standard webometric report has been commissioned. It was standard in the sense of being primarily designed to calculate webometric indicators for an academic Web space rather than using the webometric indicators as an intermediate step to an additional goal. This contract was Iberoamerican Spaces 2008: Innovations, Science and Technology funded by the Comisión Económica para América Latina (CEPAL), United Nations Economic Commission for Latin America and the Caribbean, UNECLAC, Business and Productive Division (Ortega and Aguillo 2009). The purpose was to analyse the Iberoamerican Web space primarily through network visualisations and social network analysis statistics, and it identified factors such as linguistic divides and national subnetworks.
A set of indicators for European research interlinking has also been calculated for the European Community Science, Technology and Competitiveness Key Figures Report 2008 (Directorate-General for Research 2008) (Aguillo, Ortega), giving webometrics a showcase within the European science policy community. The outputs included a geographic map of Europe showing the main directions of international academic links.
Taken together, these two studies give recognition that academic hyperlinks are viewed as important in their own right in some international science policy circles.
The Directorate-General for Research of the European Commission has commissioned a number of studies containing a webometric component that were designed to shed light on aspects of internationalism in research. Project NetReAct (Barjak and Robinson 2007; Barjak and Thelwall 2008) used hyperlinks to life science research group Web sites in nine European countries in order to get an indication of the degree of internationalism in each country. The assumption for this was that the proportion of hyperlinks originating in foreign countries would be a reasonable approximate indicator of the degree of internationalism of the target country's academic life science research. The same link data was also used to identify the most prominent life science research groups in each country for interviews and questionnaires, with the assumption that better research groups would tend to attract more links. The latter shows that webometrics can play a helper role in more traditional research methods. Project RESCAR (Barjak, Robinson, Thelwall) had similar goals to NetReAct but for the wider remit of social sciences and engineering.
The above two projects derived from the same initiative and the funding of the second to the same research team was an indicator of the success of the first. At least two further projects have given results for the Commission with related goals, however. A separate project, Rindicate, (Thelwall, Klitkou, Arnold, Stuart, Vincent) was a more exploratory initiative, charged with demonstrating that webometrics could provide useful indicators about international technology networks in emerging transdisciplinary research fields, such as second generation boifuels.
In addition to the above projects, a webometrician has been employed by the Directorate-General for Research: Gaston Heimeriks at the Institute for Prospective Technological Studies in Seville. Overall, this points to a significant uptake of webometrics by the Directorate-General but this uptake does not seem to have been replicated in any other similar national or international body. This is perhaps because webometrics for research seems particularly relevant for its international coverage and relative ease with which it can be applied to many different countries compared to bibliometrics. As a result it is most relevant to powerful international research monitoring and funding agencies, of which the Directorate-General is the prime example.
The UK Joint Information Systems Council has funded two projects that use webometrics to help evaluate the impact of collections of digital resources. The Council is in charge of the higher education infrastructure in the UK and is not a research funding agency but does fund projects including an element of research. The first project, User Needs and Potential Users of Public Repositories: An Integrated Analysis, (Thelwall, Zuccala, Oppenheim, Dhiensa) developed a standard set of webometric methods to evaluate digital repositories, including inlink evaluations and colink diagrams. Although the Council had not specified webometrics in its funding call for repository evaluation methods, it selected the webometric proposal as a solution to its needs.
The second Joint Information Systems Council project, TIDSR Toolkit (microsites.oii.ox.ac.uk/tidsr/), (Meyer, Thelwall, Eccles, Stuart) had the objective to develop an integrated method to evaluate the digital archives funded by the Council. Webometrics was proposed as part of the toolkit, along with interviews, surveys and Web log file analysis.
Although digital repositories are an international phenomenon, it seems that only the Council has funded evaluation research including webometrics. The clear reason for this difference seems to be the availability of UK webometrics researchers willing to bid for the project. Since webometrics is a logical, but not necessary, solution to the online evaluation problem, this seems to be the most likely explanation.
Note that this research relates somewhat to an earlier webometric study of the characteristics of online scholarly documents (Jepsen et al. 2004).
The Ranking Web of World Universities (Aguillo, et al. 2006) is not an externally-funded initiative but is included here because it is a high profile webometrics initiative aimed primarily at universities rather than information scientists. It ranks world universities' Web presences based upon a weighted sum of webometric indicators, such as the number of rich files (e.g., pdf) in their Web sites and the number of hyperlinks pointing to their Web sites (Aguillo et al. 2006). Evidence of its impact includes the award of an honorary doctorate to its initiator Aguillo, as well as over 16,000 Web pages linking to it, according to Yahoo, in 15 December 2009.
The lack of further similar rankings probably reflects the scarcity of expertise and knowledge to create it and its almost universal coverage, making competitors redundant. The value of the ranking to the field of webometrics is hard to judge but it seems to have given webometrics a much higher visibility in academia than it would otherwise have.
This section surveys research fields or types of research outside library and information science that have cited webometrics research. To qualify, the research area must make significant use of the webometrics research rather than just giving it a perfunctory mention. This section is organised by discipline but discusses the types of webometrics research cited.
Figure 1 summarises the results of the classification of the non-library and information science sources of articles citing webometrics. The main sources are all related to information science. The discipline of computing has many overlaps with library and information science, including the topics of information retrieval, information systems, human factors in computing, digital libraries and Web technologies. These overlaps also allow some articles that could be classified as webometrics to be published in computing conferences, including: 'A Webomatrics Analysis between Taiwan and China Academic Web by Sitation Analysis' in Proceedings of the 2008 International Conference on Semantic Web and Web Services, and 'Agreeing to disagree: Search engines and their public interfaces' in Proceedings of the ACM International Conference on Digital Libraries. In the latter case, the conference could arguably also be classified as a library and information science conference. The overlap is also reflected in the inclusion of some papers authored by webometricians (Bar-Ilan, Björneborn, Thelwall) but published in computer science venues. Interestingly, although there is significant computer science (information retrieval) research into search engine design from the main commercial search engines, this seems never to cite webometrics although academic search engine research and other articles discussing the role of search engines do sometimes cite it (e.g., 'Web evolution and incremental crawling').
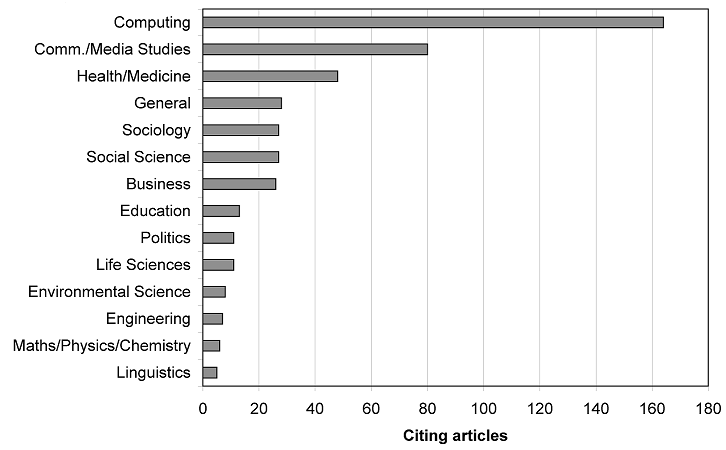
Communication and media studies also have significant overlaps with library and information science (Paisley 1984) and webometrics authors that publish in its journals (Bar-Ilan, Shaw, Thelwall, Vaughan). It also has some authors that could be described as webometricians because of their focus on quantitative Web methods (Ackland, Elmer, Park and perhaps Foot). The main sources in this category are the journals New Media and Society, Journal of Computer-Mediated Communication and First Monday (a general Internet journal but with a communication/media focus). The use of hyperlinks to investigate politics or other sets of Web sites is a common theme in the articles citing webometrics (e.g., 'The north/south divide in NGO hyperlink networks', 'The Italian extreme right on-line network: An exploratory study using an integrated social network analysis and content analysis approach'), and webometrics articles investigating blogs or search engines also receive some citations (e.g., 'Election bloggers: methods for determining political influence', 'Blogging practices: an analytical framework', 'The social, political, economic, and cultural dimensions of search engines: an introduction').
Within communication and media studies, social network site research is also represented (e.g., 'Examining social media usage: technology clusters and social network site membership', 'An anonymous social network site to share pictures'). The rise of social network sites saw a rapid growth in research into how they are used, who uses them and their impact on society. The leading light in this trend has been Danah Boyd (e.g., Boyd and Ellison 2007) and the research seems to be concentrated in media studies, communication studies and sociology and is represented at many conferences in these fields. There has also been related research in health and psychology (Hinduja and Patchin 2008; Sheldon 2008). Although there have been only a few webometrics studies of social network sites, using a data mining approach rather than link analysis, these have been cited for the range of basic data provided about social network sites, rather than for methods or theoretical insights.
There is also a logical connection between library and information science and the areas of health and medicine, through the field of medical informatics, the existence of which signals the particular importance of the field. Although information science is relevant to all academic fields because all require information seeking, there do not seem to be equivalent hybrid fields for all disciplines. There is only one webometrics author represented in the health and medicine set (Aguillo), however, suggesting that the overlap occurs mainly at the topic level. A wide variety of journals are represented however, from those with no obvious connection like the International Journal of Colorectal Disease to a few with an informatics connection, such as Journal of Medical Internet Research. One common topic forming an obvious crossover is a concern with online medical information searching and quality (e.g., 'Searching of information in evidence-based pediatrics (I): 'Infoxicacion' and Internet', 'Can examination of WWW usage statistics and other indirect quality indicators help to distinguish the relative quality of medical Websites?', 'Analysis of governmental Web sites on food safety issues: A global perspective', 'Gastrointestinal cancer Web sites: How do they address patients' concerns?'). The most common topic seems to be bibliometrics, however (e.g., 'Citations to trials of nicotine replacement therapy were biased toward positive results and high-impact-factor journals'), with webometric literature cited for its evaluations of Google Scholar (e.g., 'Acimed in Scholar Google: a citation analysis of the Cuban Journal of Health Information and Communication Professionals', 'Comparisons of citations in Web of science, Scopus, and Google Scholar for articles published in general medical journals') or for its relevance to Web references (e.g., 'Web Citations in the Nursing Literature: How Accurate Are They?'). Overall, health and medicine seem be particularly fertile areas for a range of webometrics research. Over a third of the articles are in Spanish (17/48), suggesting that webometrics is most visible amongst Spanish-language medical and health researchers.
Like communication/media studies, the sociology citations are often related to political or issue hyperlink networks (e.g., 'A hyperlink network analysis of citizen blogs in South Korean politics', 'Cyberplace and cyberspace: Two approaches to analyzing digital intercity linkages') and search engines (e.g., 'Search engines: Terrorism's killer app') but there are also more general theoretical articles (e.g., 'Opening the black box of link formation: Social factors underlying the structure of the Web', 'New techniques in online research: Challenges for research ethics'). Social science citations display a similar pattern, with webometrics authors contributing many of them (11/27).
The last area with at least 5% of the citations is business. Most of the citing articles covered online business and particularly marketing and e-commerce (e.g., 'Internet-based scanning of the competitive environment', 'Competition in internet retail markets: The impact of links on Web site traffic', 'Website adoption and sales performance in Valais' hospitality industry'). The webometrics articles seemed to supply background information for these. A few bibliometrics articles were also present, discussing Google Scholar or online sources (e.g., 'Google scholar visibility and tourism journals', 'A citation-based ranking of the business ethics scholarly journals', 'Ranking, rating and scoring of tourism journals: Interdisciplinary challenges and innovations').
The Google Scholar searches for webometrics and link analysis studies not citing webometrics produced articles mainly from computer science and sociology. Some were isolated studies but others formed coherent bodies of work. The latter are discussed below, broadly by discipline. In addition, physics research known to the author but not found by the searches is discussed.
Many different Web-related computer science topics use link analysis but do not cite webometrics research. The topics include search engine ranking algorithms, Web information retrieval, question answering, link analysis, link mining, crawling, Web page classification, and spam filtering. This shows that there is a significant body of link analysis research that does not need webometrics. This could be because the computer science research is typically concerned with algorithm construction (e.g., 'Discovering authorities in question answer communities by using link analysis', 'Link analysis ranking: algorithms, theory, and experiments') whereas webometrics normally analyses the outputs of algorithms, giving a different perspective. In addition, there is some computer science research into traditional library and information science topics like scholarly communication (e.g., 'Semantic Web link analysis to discover social relationships in academic communities') and collaborative knowledge building (e.g., 'Link analysis for collaborative knowledge building').
A type of link analysis has been successfully promoted by Richard Rogers, a sSociologist at the University of Amsterdam. His variant focuses on 'issue networks', collections of networks around a topic of interest. His IssueCrawler software supports the generation of networks using hyperlink data from any (themed) set of Web sites entered by the user. This approach is described with examples in two books (Rogers 2002; 2005) and has been adopted by others to research topics such as the Web usage patterns of diaspora communities (Kissau and Hunger 2008). Relatively little of this research seems to be published in recognised academic journals, however, perhaps due to its humanities-oriented nature.
It is not clear why issue network research does not cite webometrics from a methodological perspective because much webometrics research relates to the accuracy of data from commercial search engines or the validity of using links in social science research. The reason may be because of the humanities focus on exploration and idea generation rather than a social science focus on data validity and methodological robustness.
Much physics research is concerned with fitting simple mathematical models to large-scale data. In around 1999 a number of physicists noticed that links to Web pages did not have a standard Gaussian distribution, showing that they approximately fitted a power law (Adamic, Barabasi). webometrics research was probably not cited because it was not known or did not provide relevant methods due to its reliance upon commercial search engines (e.g., Ingwersen). In fact an early webometrics article (Rousseau 1997) seems to have been the first to observe power law phenomena in the Web, albeit on a small scale, but this went unnoticed or unrecognised.
This physics research was closely related to some computer science research into power laws (e.g., Pennock et al. 2002). In fact a small computer science or physics research field of Web dynamics arguably began to subsequently form (e.g., book) with some participation by webometricians Judit Bar-Ilan who injected a search engine evaluation perspective. Most of the research was quite theoretical and abstract, however, often simulating Web link growth and attempting to build a simple mathematical model for it. This abstract approach perhaps rendered the more concrete webometrics research less relevant, and since commercial search engines were rarely used for raw data, the search engine evaluation webometrics was not found useful. Nevertheless, some webometrics contributions, such as the alternative document model concept for link counting could arguably have made a contribution to generating cleaner link data but was not used. Perhaps the computer scientists and physicists did not know of its existence and looked for relevant prior work mainly from within their own fields or did not regard webometrics as meeting other criteria for citing.
The methods used in this article have a number of limitations. First, there may be researchers outside the sample e-mailed who have conducted commissioned research. This may have occurred in non-English speaking nations with developed national literatures outside the Web of Science (e.g., China), or by research teams not emphasising academic publications for example. Similarly, for the citation analysis, the coverage of Scopus is incomplete and therefore there will be citations that have been missed and possibly even whole areas of science. In particular, there may be national literatures or even whole disciplines that have been missed. In addition, the definition of webometrics selected, based on researchers more than content, would not necessarily be universally accepted as the best choice.
From a wider perspective, the methods used (e-mails and citation analysis) seem to have worked to give insights into the extent to which webometrics has found applications but perhaps more detailed methods would have helped. In particular, some kind of benchmarking of citations would have helped to decide whether webometrics had attracted an unusually high or low number of citations from outside library and information science.
From the limitations, the findings should be interpreted as the minimum impact of webometrics rather than an estimate of its actual impact. Nevertheless, it is clear that webometrics has gained a small foothold in the European Union and Iberoamerica in terms of researchers being commissioned for applied studies. In addition, webometrics research is having some impact in other disciplines in the sense of attracting citations. These include the cognate disciplines of computer science and communication (and media) studies as well as the broad area of health and medicine. In contrast, related sociology and physics/complexity research seems to be bypassing webometric studies, although this is also true for some computer science research too. In summary, webometrics is having some impact outside of its field but has not influenced some areas that it perhaps should have. Most promising for the future may be health-related research because its lack of cognate connection with information science, except through medical informatics, means that there may be little awareness of it within the webometrics community. More health-related webometrics research is therefore recommended in the future to help strengthen this connection.
The results are probably insufficient to give a definitive answer about whether webometrics is likely to have a future, however, since this is a qualitative question and the results are not clear-cut enough to demonstrate clear and lasting applications. Instead, webometrics may still be at a vulnerable growing stage with too few clear applications to make a strong case for its future value and vitality.
Mike Thelwall is a Professor of Information Science in the School of Computing & IT, University of Wolverhampton, UK. He received his Bachelor's degree in Mathematics and his PhD from Lancaster University, UK. He can be contacted at m.thelwall@wlv.ac.uk
| Find other papers on this subject | ||
Dear [name],
[personal message]
I am carrying out a study of applications of webometrics research and would be very grateful if you could assist this by giving an answer to the following question. A draft of the article is available at [URL] so that you can see the context in which the information would be used and also my own answers to the question built into the text.
Question: Please could you name, give an URL for (if possible) or describe projects that you have been involved in that have (a) used webometrics AND (b) been applied in the sense of being funded either as contract research or as other contract work. This excludes research funded by research funding agencies, except for specifically commissioned studies.
Best wishes and many thanks,
Mike
© the author, 2010. Last updated: 20 September, 2010 |
|
