vol. 14 no. 4, December, 2009
vol. 14 no. 4, December, 2009 | ||||
Fuzzy set theory, which was founded by Zadeh (1965), has emerged as a powerful way of representing quantitatively and manipulating the imprecision in problems. The theory has been studied extensively over the past forty years and satisfactorily applied to problems (for examples, see Dubois and Prade 1985, Kahraman et al. 2006, Klir and Yuan 1995, Zimmermann 2001 or Zadeh 2008).
In Spain, the first paper on fuzzy set theory was published by Trillas and Riera (1978). From 1978 to the present, more than 1,500 papers on the topic have been published by the Spanish fuzzy set research community, as shown by the ISI Web of Science. The Spanish fuzzy set community ranks seventh in the top-ten ranking of the most productive countries on fuzzy set theory research, and it is the second European country (according to data from ISI Web of Science).
According ISI Web of Science, from 1965 more than one hundred thousand papers on fuzzy set theory foundations and applications have been published in journals. In spite of this huge number of published papers there has been no bibliometric study on the field.
In this paper, the first bibliometric study is presented analysing the research carried out by the Spanish fuzzy set community. It is done by means of bibliometric maps, which show the associations between the main concepts studied by the Spanish community. The maps provide insight into the structure of the field, visualize the research subfields and indicate the existing relationships among these subfields. To generate these maps we use the software CoPalRed which is based on the longitudinal mapping defined by Garfield (1994) and the co-word analysis (Callon et al. 1983, Callon et al. 1991, Coulter et al. 1998, Whittaker 1989), which is a useful and powerful tool for describing and showing up the internal structure of a scientific field (Bailón-Moreno et al. 2005, Bailón-Moreno et al. 2006, Leydesdorff and Zhou 2008, Zhang et al. 2008).
The study reveals the main themes treated by the Spanish fuzzy set theory community from 1978 to 2008. It also allows comparison with those themes treated by other important international communities such as the USA, Canada, the United Kingdom, Germany, Japan, the Peoples Republic of China and Spain, which are collectively known as the G7 group. These seven countries were selected because they satisfy three conditions:
We complete our study by showing a quantitative analysis of the visibility of the Spanish fuzzy set community according to ISIs Web of Science, and showing a quantitative analysis on the importance of Spanish fuzzy research on the international fuzzy research according to ISI Web of Science. Doing those studies and comparisons, the impact of the Spanish fuzzy set theory community is also measured.
Co-word analysis is a content analysis technique that is effective in mapping the strength of association between information items in textual data (Callon et al. 1983, Callon et al. 1991, Coulter et al. 1998, Whittaker 1989). It is a powerful technique for discovering and describing the interactions between different fields in scientific research (Callon et al. 1991, Bailón-Moreno et al. 2006, Leydesdorff and Zhou 2008, Zhang et al. 2008). Co-word analysis reduces a space of descriptors (or keywords) to a set of network graphs that effectively illustrate the strongest associations between descriptors (Coulter et al. 1998).
According to Krsul:
"this technique illustrates associations between keywords by constructing multiple networks that highlight associations between keywords, and where associations between networks are possible". (Krsul 1998: 80)
The basic assumption in bibliometric mapping (Börner et al. 2003) is that each research field can be characterized by a list of the important keywords. Each publication in the field can in turn be characterized by a sub-list of these global keywords. Such sub-lists are like DNA fingerprints of these published articles.
Börner et al. (2003: 185) suggest that these fingerprints can be used as a similarity measure: "The more keywords two documents have in common, the more similar the two publications are, and the more likely they come from the same research area or research specialty at a higher level".
Garfield (1994, 1) suggests that longitudinal mapping can be used to plot the evolution of a field, and can be used by analysts and domain experts to forecast trends in the field. Novices might also discover the key research areas and their interconnection.
According to Börner et al. (2003: 188), the process of constructing a bibliometric map can be divided into the following six steps:
We now discuss how we implement each of these steps.
The first step in the process of bibliometric mapping, is the collection of raw data. In this paper, the raw data consist of a corpus containing 16,344 original papers, about fuzzy set theory produced by the G7 group from 1965 to 2008. These original papers were extracted from ISI Web of Science with the query number 1 on 7th January 2009:
query 1: (TS=fuzz* or SO=("FUZZY SETS AND SYSTEMS" OR "IEEE TRANSACTIONS ON FUZZY SYSTEMS")) AND CU=(SCOTLAND OR JAPAN OR CANADA OR SPAIN OR ENGLAND OR "NORTH IRELAND" OR USA OR "PEOPLES R CHINA" OR WALES OR GERMANY) AND Document Type=(Article).
Where TS field is a search based on the Topic, SO field is a search based on Journal Title (Fuzzy Sets and Systems and IEEE Transactions on Fuzzy Systems are the two most important scientific international journals on the topic) and CU field is a search based on the Country.
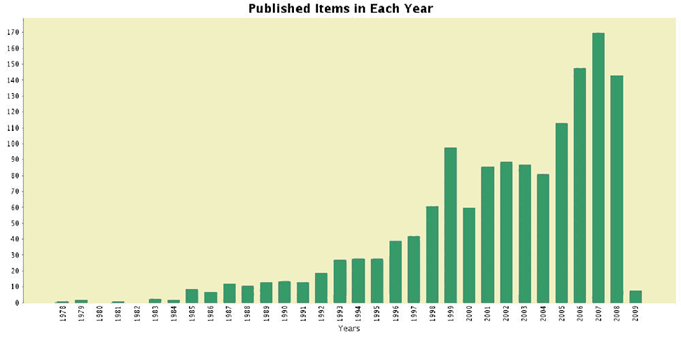
In Figure 1, the numbers of retrieved papers from ISI Web of Science from 1965 to 2008 is shown.
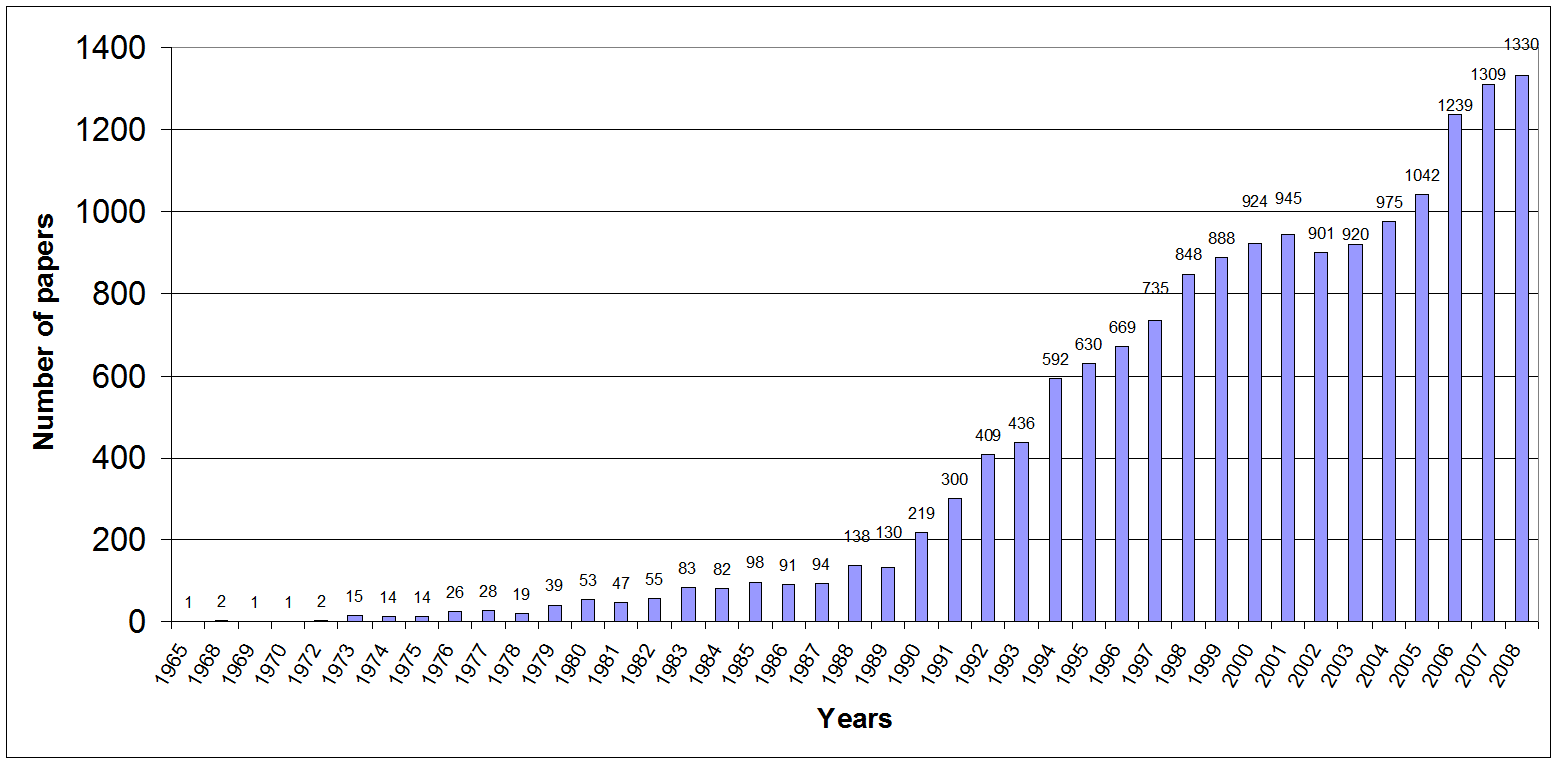
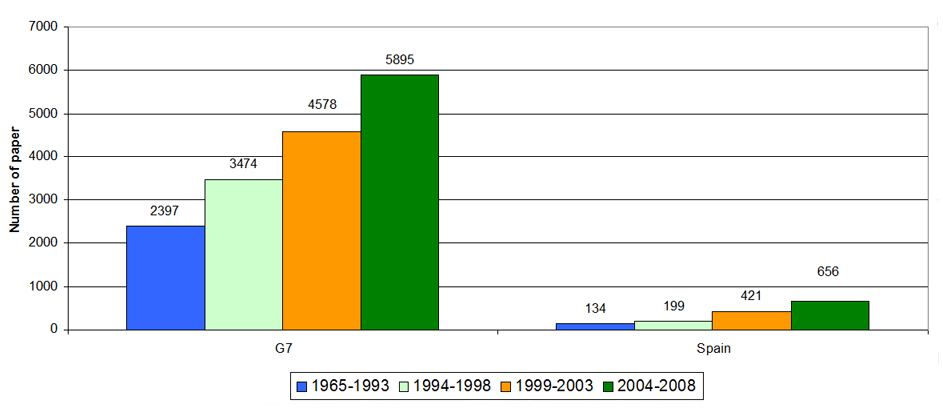
Two blocks of papers were collected, one for analysing the evolution of the fuzzy set theory field in all of the above mentioned countries taken together and another block to analyse the Spanish case. From these two blocks of papers, four subsets of papers are extracted, one for each studied sub-period: 1965-1993 (although the fuzzy sets based research in Spain started in 1978), 1994-1998, 1999-2003 and 2004-2008. In co-word analysis, in a longitudinal study, it is usual for the first sub-period to be the most long-lasting to get a representative number of published papers. For this reason, in this paper, the first studied sub-period includes twenty-nine years (from 1965 to 1993) and the other three sub-periods just five years. In this way, separate bibliometric maps can be constructed for each one of the four studied sub-periods. The number of papers in each block and sub-period is shown in Figure 2.
The second step is the selection of the type of item to analyse. According to Börner et al. (2003), journals, papers, authors, and descriptive terms or words are most commonly selected as the type of item to analyse. Each type of item provides a different visualization of a field of science and results in a different analysis. In this paper, we chose to analyse descriptive words, i.e., keywords. A bibliometric map showing the associations between keywords in a scientific field is referred to as a keywords-based map in this paper.
The third step is the extraction of relevant information from the raw data collected in the first step (Börner et al. 2003). Here, the relevant information consists of the co-occurrence frequencies of keywords. The co-occurrence frequency of two keywords is extracted from the corpus of papers by counting the number of papers in which both keywords occur in the keywords section.
The fourth step is the calculation of similarities between items based on the information extracted in the third step (Börner et al. 2003). Here, similarities between items are calculated on the basis of frequencies of keywords co-occurrences. When two keywords frequently occur together, they are said to be linked, and the intensity of the link is indicated by the equivalency index (Michelet 1988, Callon et al. 1991), eij defined as:
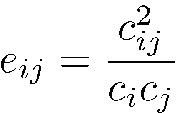
where cij is the number of documents in which two keywords i and j co-occur and ci and cj represent the number of documents in which each one appears. When the keywords appear together, the equivalency index equals unity; when they are never associated, it equals zero. Once the links are quantified, by an algorithm called simple centres, groupings or themes are produced, which consist of more strongly linked networks representing the centres of interest of the researchers.
As described by Coulter et al. (1998), the simple centres algorithm uses two passes through the data to produce the desired networks. The first pass (Pass-1) constructs the networks depicting the strongest associations and links added in this pass are called internal links. The second pass (Pass-2) adds to these networks links of weaker strengths that form associations between networks. The links added during the second pass are called external links.
Coulter et al. (1998) note that two keywords that appear infrequently in the corpus, but always appear together, will have higher strength values than keywords that appear many times in the corpus almost never together. Hence, possibly irrelevant or weak associations may dominate the network. A solution to this problem incorporated into the algorithm described in this section is to require that only the keyword pairs that exceed a minimum co-occurrence are considered potential links while building networks during the first pass of the algorithm. As each sub-period and block has different numbers of papers, different minimum co-occurrence values are used: 3, 4, 4 and 6 for the sub-periods 1978-1993, 1994-1998, 1999-2003 and 2004-2008, respectively for the G7 case; and 2 for all sub-periods for the Spanish case.
During the Pass-1, the link with the highest strength is selected first, its nodes becoming the starting nodes of the first Pass-1 network. Other links and their corresponding nodes are added to the graph using a breadth-first search on the strength of the links (i.e., the strongest link connecting a node that is not in any graph to the graph being constructed is added first), until there are no more links that exceed the co-occurrence threshold, or a maximum Pass-1 link limit is exceeded. The next network is generated in a similar manner starting with the link with the highest strength that is not in any existing graph.
Networks are interconnected by Pass-2 links. The centrality of a network measures the degree of interaction to other networks (Callon et al. 1991) and it can be defined as:
with k a keyword belonging to the theme and h a keyword belonging to other themes.
The density of a network measures the internal strength of the network (Callon et al. 1991) and it can be defined as:
with i and j keywords belonging to the theme, and w being the number of keywords in the theme.
Isolated Networks are those that have low centrality values. Principal Networks are those that have high centrality and high density values, (for more detail see Callon et al. 1991).
The fifth step is the positioning of items in a low-dimensional space based on the similarities calculated in the fourth step (Börner et al. 2003). In this paper, the low-dimensional space is referred to as a keywords based map and only two-dimensional keywords based maps are considered. The two dimensions are centrality rank (cr) and density rank (dr), calculated as:
where rankic is the position of the theme i in the theme list in ascending sort of centrality, and rankid is the position of the theme i in the theme list in ascending sort of density. N is the number of themes in the whole network. N is introduced to normalize in [0,1] the centrality rank and density rank values.
The sixth step is the visualization of the low-dimensional space that results from the fifth step (Börner et al. 2003). In our study, we use CoPalRed computer program, which is briefly described in Subsection The The CoPalRed software. CoPalRed visualizes the networks in a strategic diagram. A strategic diagram is a two-dimensional space in which themes are localized in strategic positions using the two measures, density rank (values in the ordinate axis) and centrality rank (values in the abscissa axis) (for more detail see Callon et al. 1991). The abscissa axis is associated to centrality, or the external cohesion index. It represents the most or least central position of a theme within the overall network. The ordinate axis is associated to density, or the index of internal cohesion. It represents the conceptual development of a theme.
Four areas of interest (or quadrants) can be defined in a strategic diagram (see Figure 3). Each quadrant has an associated theoretical meaning. The meaning of the four quadrants is:
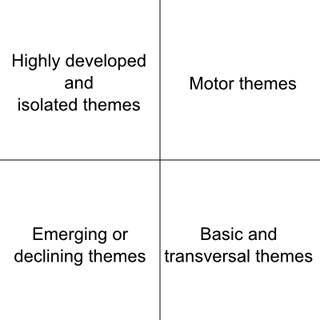 Figure 3: Quadrants in a strategic diagram. |
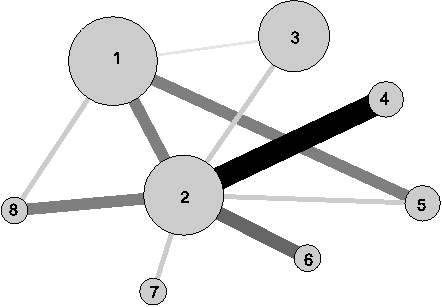
 Figure 4: An example of strategic diagram. |
CoPalRed visualizes a keywords-based map by displaying a sphere for each theme. This sphere indicates the location of the theme in the strategic diagram. The spheres can group and show representative information of the themes. In this paper, that information includes the name of the themes (identified by the most central keyword of the theme) and the number of associated papers. To do that, CoPalRed assumes a paper belongs to a theme when it presents at least 2 keywords of the theme.
As example, in the strategic diagram in Figure 4, the themes A, B and C are presented. The placement of theme B implies that this theme is quite related externally to concepts applicable to other themes that are conceptually closely related. In addition, the internal cohesion is also rather strong, and therefore we can consider B to be a motor-theme of the studied scientific field.
In this paper the CoPalRed software (CoPalRed 2005) is used to generate the bibliometric maps.
CoPalRed has been successfully used to describe the field of physical chemistry of surfactants in (Bailón-Moreno et al. 2005, Bailón-Moreno et al. 2006).
CoPalRed performs three kind of analysis: structural analysis, strategic analysis and dynamic analysis.
This section analyses the evolution of the fuzzy set theory field over recent years. First, the evolution of the field in Spain is studied (including the analysis of the fuzzy sets research carried out by the G7 countries and a comparison between both Spanish and International cases). Then, a snapshot of the visibility of the Spanish fuzzy community in the ISI Web of Science is presented. Finally, the importance of the Spanish community in the fuzzy set theory field is shown.
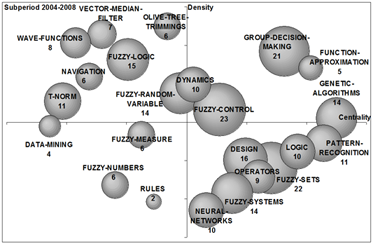
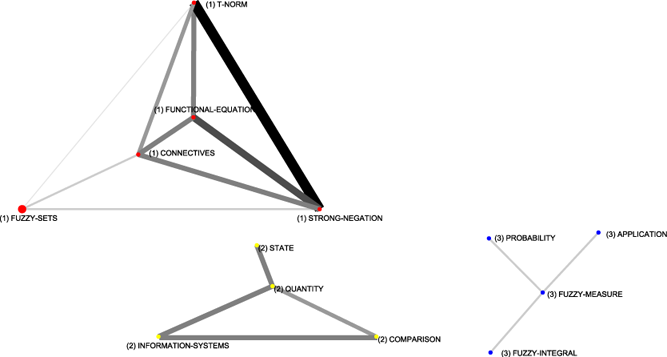
To analyse the evolution of the fuzzy set theory field over the last years in Spain, strategic diagrams for the four studied sub-periods are shown in Figure 6. The volume of the spheres is proportional to the number of documents corresponding to each theme in each sub-period (a number is used to indicate the papers per theme). In the following the four sub-periods are described.
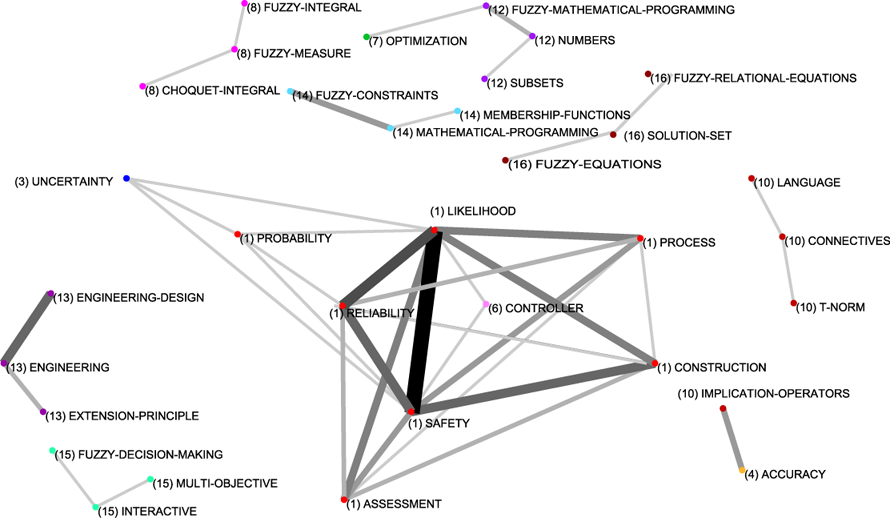
In the first studied sub-period (1978-1993), the longer one, in which there are barely enough papers (134) to get any important result, CoPalRed highlights three studied themes: connectives (five papers), fuzzy-measure (five papers) and quantity (four papers).
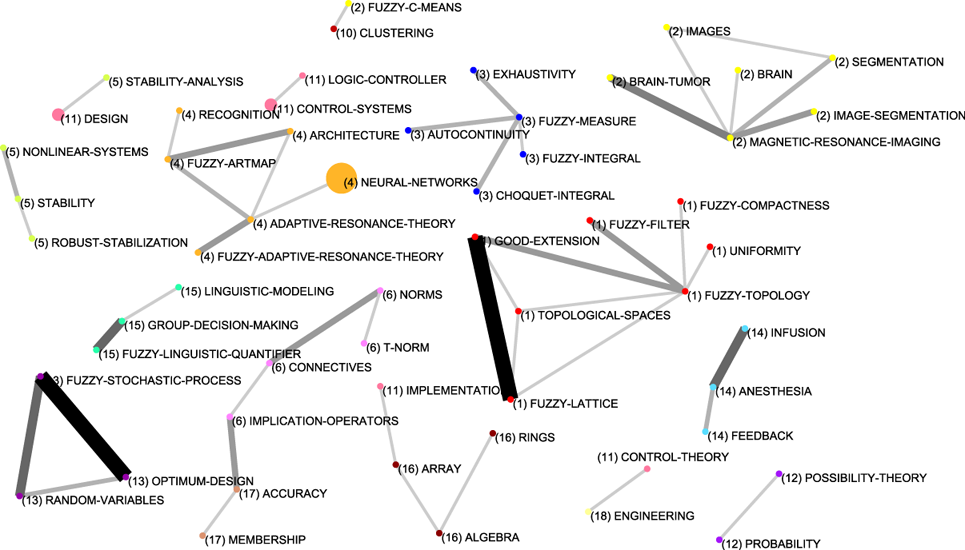
In the second sub-period (1994-1998), with 199 papers, CoPalRed shows nine themes, where linguistic-preference-relations (six papers) (the most central and dense theme), linguistic-modelling (six papers), fuzzy-logic (nine papers) and fuzzy-control (eight papers) were the four most studied themes.
 (a) 1978-1993. |
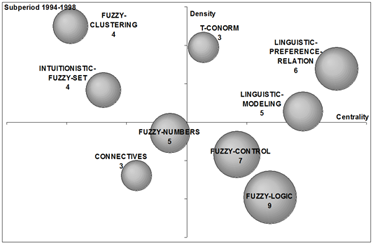 (b) 1994-1998. |
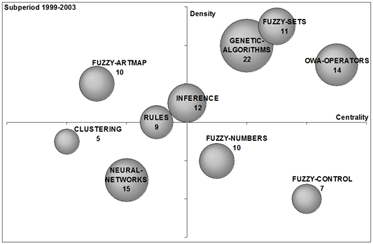 (c) 1999-2003. |
 (d) 2004-2008. |
Figure 6: Strategic diagrams for each sub-period. | |
From 1999, a significative increment in published papers is observed, which allows us to carry out a more detail analysis. In the last decade (1999-2008) more themes and bigger ones are detected (see Figure 6, specially 6c and 6d).
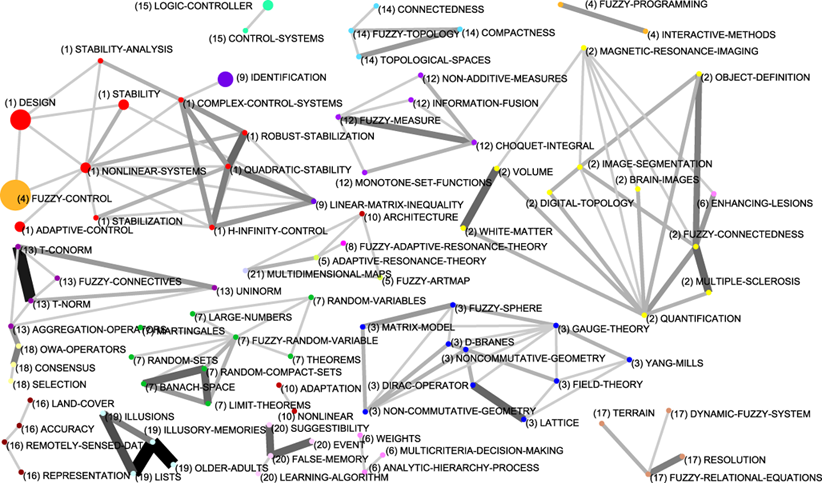
From 1999-2003, the three most studied themes by the Spanish fuzzy sets research community were: genetic-algorithms (twenty-two papers), neural-networks (fifteen papers) and OWA-operators (fourteen papers). The themes OWA-operators and genetic-algorithms were the motor-themes of the sub-period (see Figure 6c).
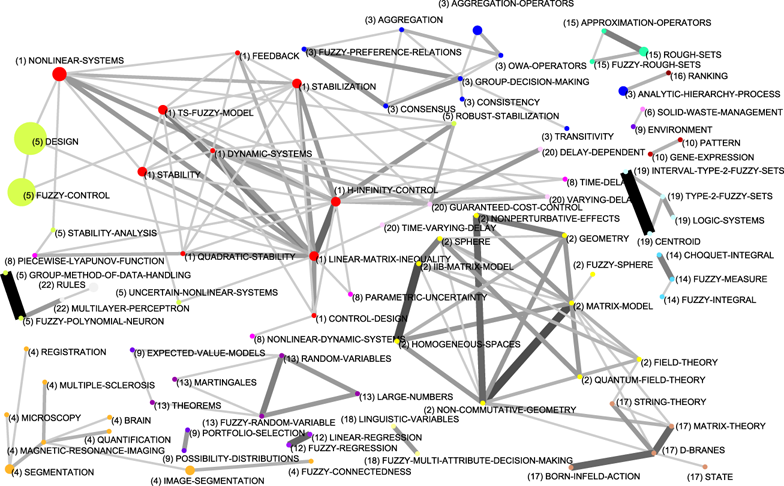
From 2004 to 2008 the three most studied themes were the basic and transversal theme fuzzy-sets (with twenty-two papers), following by the most applied themes fuzzy-control (with twenty-three papers) and group-decision-making (twenty-one papers) (see Figure 6d).
From Figure 6 we can reach several conclusions in the evolution of the most long-lasting themes in the fuzzy sets research in the Spanish community:
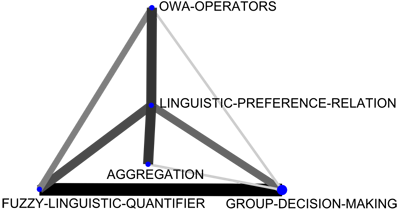
(a) 1994-1998. |
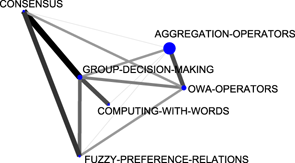
(b) 2004-2008 |
Figure 7: Group-decision-making thematic networks. | |
As summary, in Table 1, the number of papers for each theme in each sub-period is shown. Columns 2 to 5 indicate the number of papers with the theme for each sub-period. Note: CoPalRed assumes a paper belongs to a theme when it presents at least two keywords of the theme.
| Theme | 1978-1993 (134 papers) |
1994-1998 (199 papers) |
1999-2003 (421 papers) |
2004-2008 (656 papers) |
|---|---|---|---|---|
| Clustering | 5 | |||
| Connectives | 5 | 3 | ||
| Controller | 7 | |||
| Data-mining | 4 | |||
| Design | 16 | |||
| Dynamics | 10 | |||
| Function-approximation | 5 | |||
| Fuzzy-artmap | 10 | |||
| Fuzzy-clustering | 4 | |||
| Fuzzy-control | 7 | 7 | 23 | |
| Fuzzy-measure | 5 | 6 | ||
| Fuzzy-numbers | 5 | 10 | 6 | |
| Fuzzy-logic | 9 | 15 | ||
| Fuzzy-random-variable | 14 | |||
| Fuzzy-sets | 11 | 22 | ||
| Fuzzy-systems | 14 | |||
| Genetics-algorithms | 22 | 14 | ||
| Group-decision-making | 21 | |||
| Inference | 12 | |||
| Intuitionistic-fuzzy-sets | 4 | |||
| Linguistic-modeling | 5 | |||
| Linguistic-preference-relations | 6 | |||
| Logic | 10 | |||
| Navigation | 6 | |||
| Networks | 9 | |||
| Neural-networks | 15 | 10 | ||
| Olive-tree-trimmings | 6 | |||
| Operators | 9 | |||
| OWA-operators | 14 | |||
| Pattern-recognition | 11 | |||
| Quatity | 4 | |||
| Rules | 9 | 2 | ||
| Systems | 8 | 34 | ||
| T-Conorm | 3 | |||
| T-Norm | 11 | |||
| Vector-median-filter | 7 | |||
| Wave-functions | 8 |
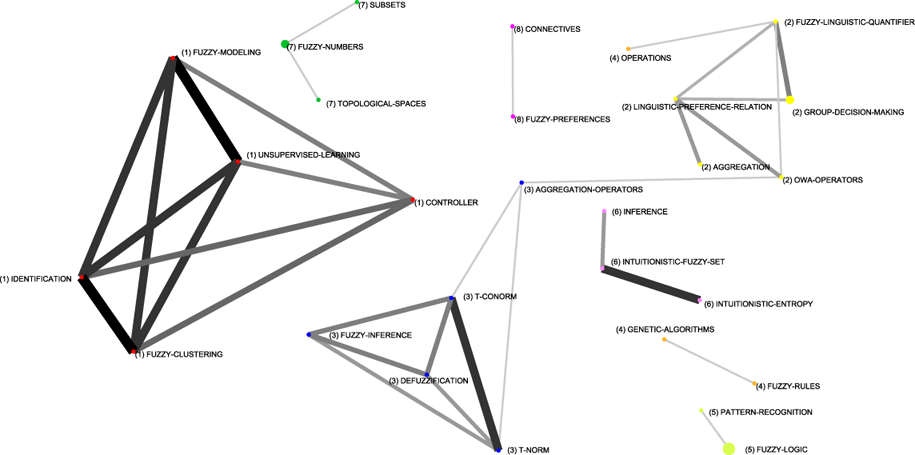
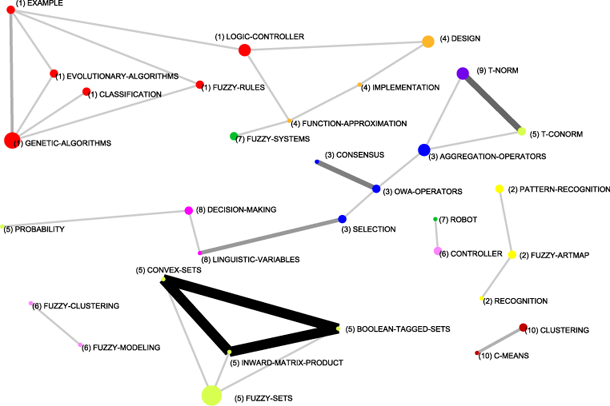
To complete the description of the evolution of the fuzzy sets based research in Spain, in Appendix A, Figures 13, 14, 15 and 16, show the complete relations among keywords and themes for each sub-period. In these networks, the volume of the spheres is proportional to the number of documents corresponding to each keyword, the thickness of the link between two spheres i and j is proportional to the equivalence index eij. Keywords belonging to a theme are labelled with the same number and each number represents a theme. Different numbers are used in each sub-period. Only the strongest relations are shown.
To analyse the recent evolution of the fuzzy set theory field in the above mentioned G7 countries, strategic diagrams for the four studied sub-periods (1965-1993, 1994-1998, 1999-2003 and 2004-2008) are shown in Figure 8. The volume of the spheres is proportional to the number of documents corresponding to each theme in each sub-period (a number is used to indicate the papers per theme). In the following the four sub-periods are described.
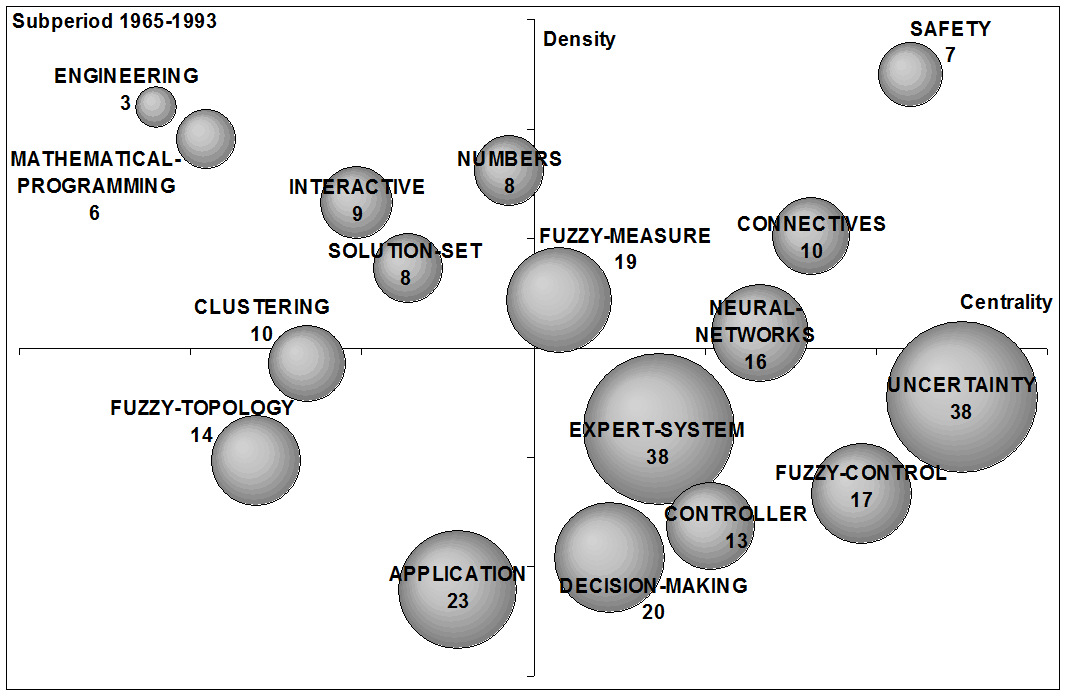
(a) 1965-1993. |
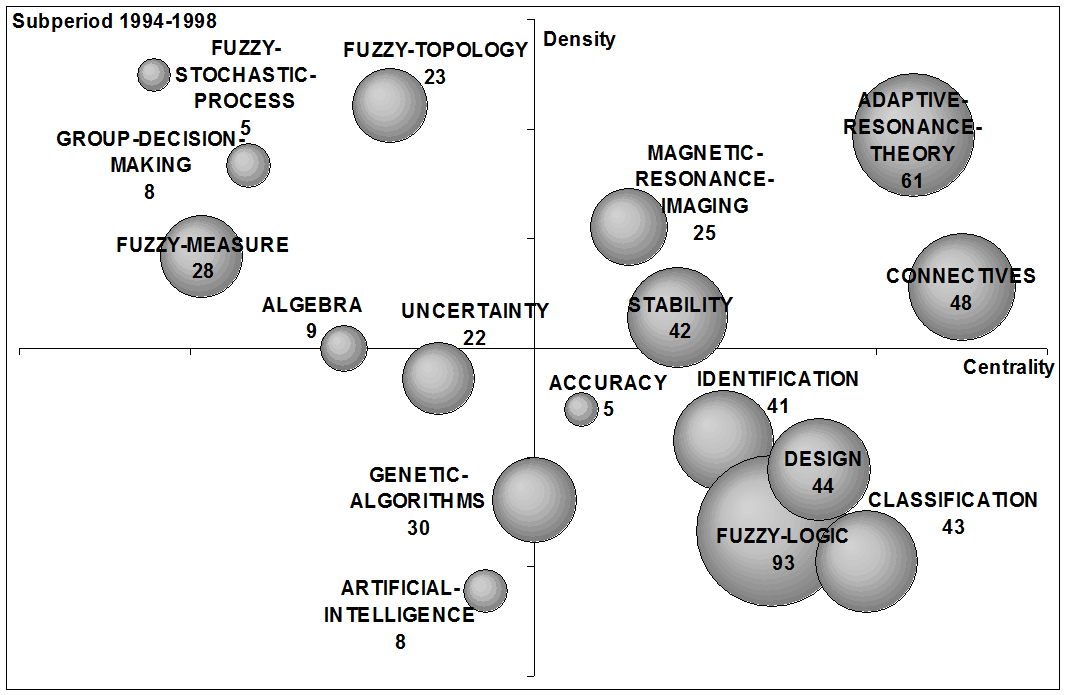
(b) 1994-1998. |
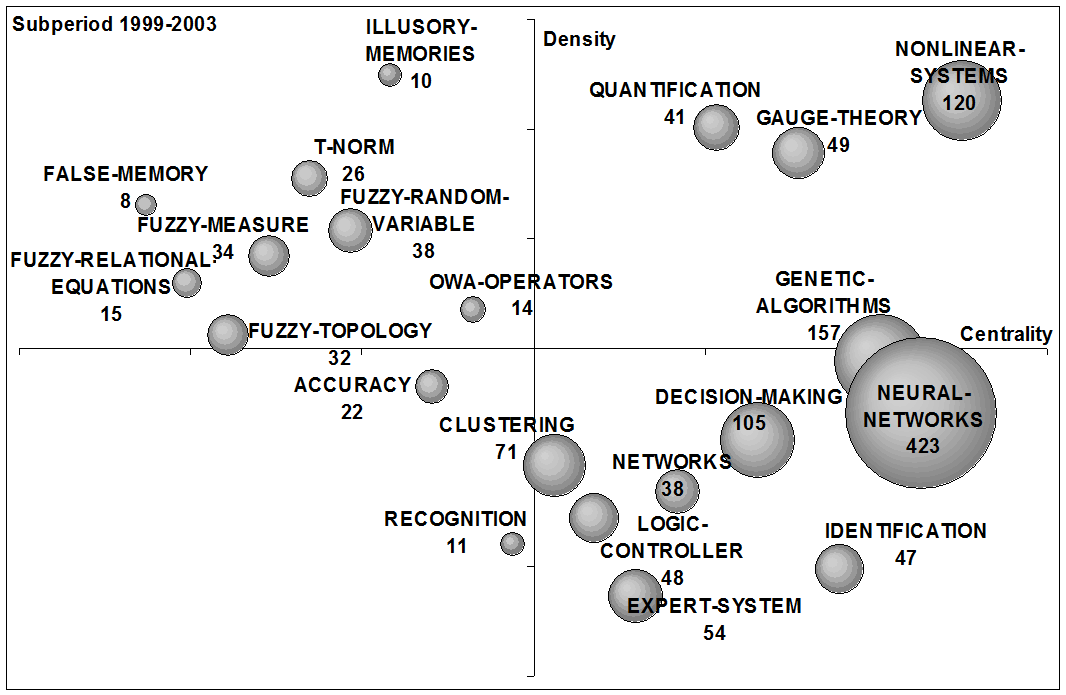
(c) 1999-2003. |
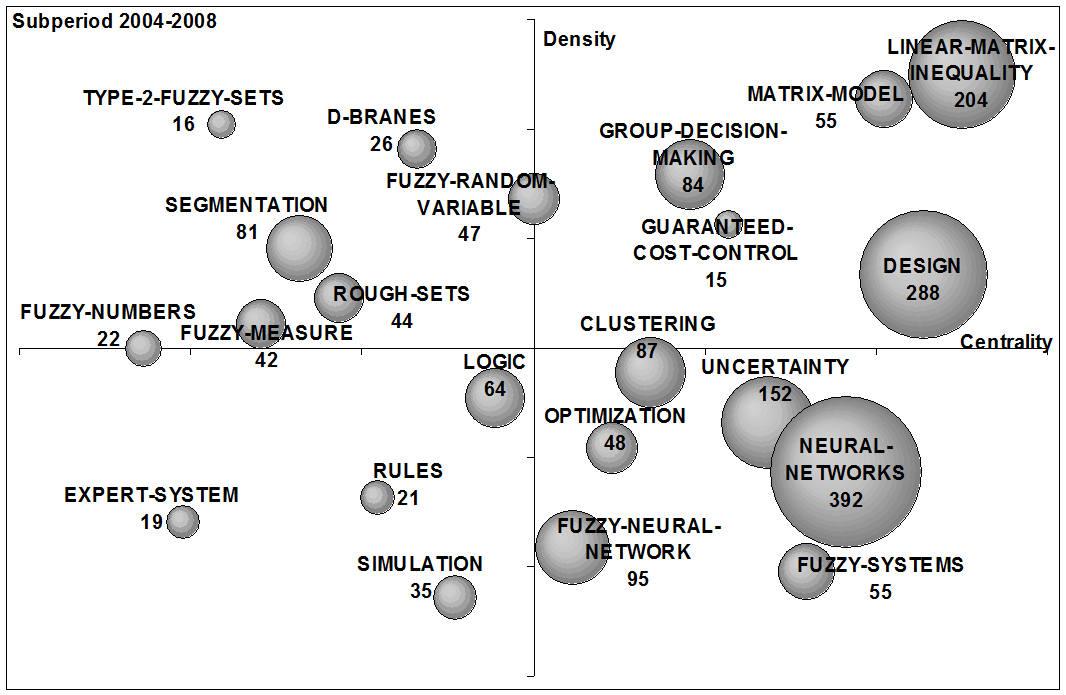
(d) 2004-2008 |
Figure 8: Strategic diagrams for each sub-period (G7 group). | |
In the first sub-period (1965-1993), the longer one, in which 2,397 papers were published, the most important themes in the international context (Considering the countries: USA, Canada, UK, Germany, Spain, Japan and Peoples Republic of China), in relative weight in terms of number of documents, were: uncertainty and expert-systems (both with thirty-eight papers), applications (twenty-three papers) and decision-making (with twenty papers) (see Figure 8a). Because of their strategic situation (lower-right quadrant), uncertainty and expert-systems and decision-making are considered as general basic themes, with high centrality, although with low internal development. In this first sub-period, the most central theme was uncertainty, the fuzzy set theory revolve around this concept.
In the second period (1994-1998), with 3,474 papers, fuzzy-logic (ninety-three papers), adaptive-resonance-theory (61 papers), connectives (48 papers), were the three most studied themes.
In the last decade, from 1999 to 2008, a significant increment in published papers is observed (see Figure 2). In these years (sub-periods 1999-2003 and 2004-2008) the number of interest topics of the international fuzzy community was augmented, and a set of different themes has been observed by CoPalRed (see Figure 8).
From 1999-2003, the most studied themes were: neural-networks (423 papers), genetic-algorithms (157 papers), non-linear-systems (120 papers), decision-making (105 papers) and expert-systems (54 papers). All of them were strategically localized in the right quadrants (with high centrality indexes) of the strategic diagram for this sub-period, i.e., they were quite related externally to concepts applicable to other themes that were conceptually closely related. In this sub-period, the most central and dense theme was non-linear-systems, and due to its strategic localization it was considered as the motor-theme of the sub-period.
From 2004 to 2008 the studied themes were those shown in the strategic diagram of Figure 8d. In this last sub-period, the principal themes, in number of papers, were neural-networks (392 papers), design (288 papers), linear-matrix-inequality (204 papers), uncertainty (152 papers), fuzzy-neural-networks (95 papers) and group-decision-making (84 papers). In this last sub-period, the theme linear-matrix-inequality was considered as the motor-theme of the sub-period.
From Figure 8 we can appreciate several conclusions in the evolution of the most long-lasting themes in the fuzzy sets based research in the G7 group:
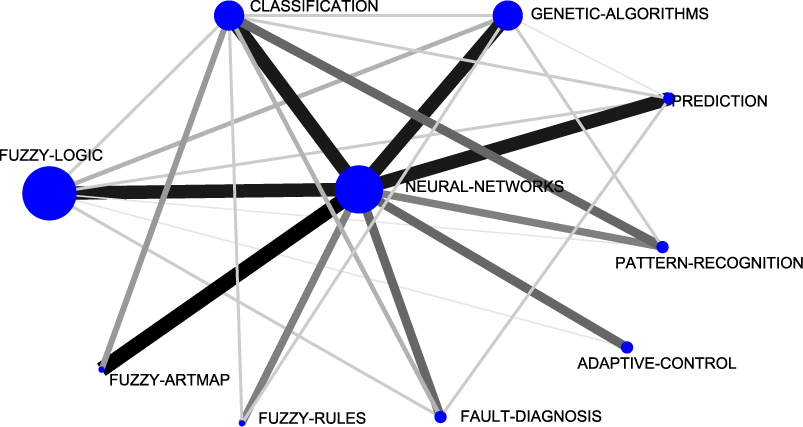
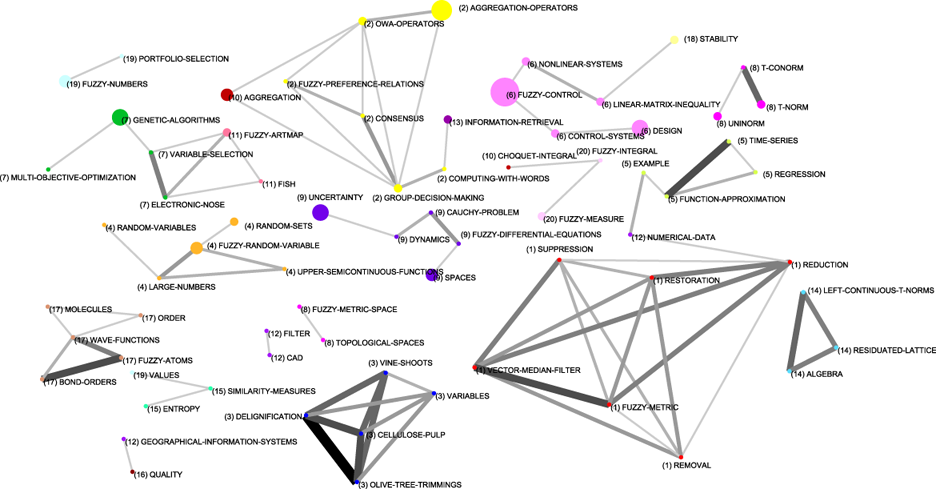
To complete the description of the evolution of fuzzy sets research in the G7 group, in Appendix A, Figures 17, 18, 19 and 20, the whole relations among keywords and themes for each sub-period are shown. In these whole networks, the volume of the spheres is proportional to the number of documents corresponding to each keyword, the thickness of the link between two spheres i and j is proportional to the equivalence index eij. Keywords belonging to a theme are labelled with the same number and each number represents a theme. Different numbers are used in each sub-period. Only the strongest relations are shown.
In this subsection, we show some conclusions about the fuzzy sets research carried out by the Spanish community compared with that of the seven studied countries (the G7 group).
From 1994-1998, whereas in the G7 group, the theme connectives (with forty-eight papers) was the most central theme (upper-right quadrant), in the Spanish research, connectives was situated in the lower-left quadrant (with just three papers). In the G7 group, the most studied theme was fuzzy-logic (with ninety-three papers), in the Spanish community just nine papers were published on this topic (see Figures 8b and 6b).
From 1999-2003, the theme neural-networks was supported by 423 papers in the G7 group, whereas in the Spanish community it received only fifteen papers. In addition, neural-networks in the G7 group, was better located (lower-right quadrant). Another important theme in this sub-period was genetic-algorithms, which was located in both cases in the upper-right quadrant. In both case, it was one of the most studied themes in the sub-period.
In the last five years (2004-2008), more similarities can be remarked upon. For example, the themes fuzzy-random-variable, group-decision-making, neural-networks, fuzzy-systems and rules were located in the same positions (in the same quadrants). In both the Spanish and the international communities the same motor-theme was treated (group-decision-making). In Figure 10 we compare the thematic networks of the group-decision-making theme. In it we can see there is almost no difference between both thematic networks, so it is possible to conclude that both communities are working on this theme, in the same way.
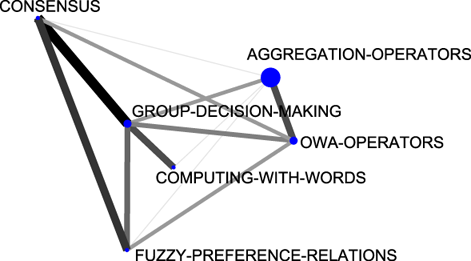
(a) Spanish case. |
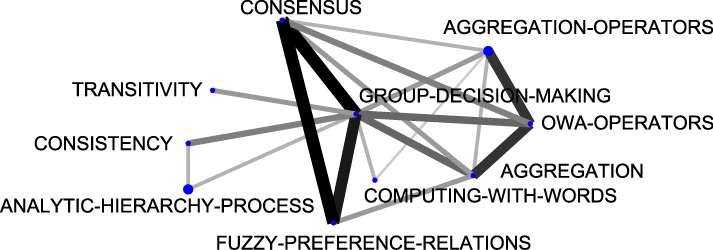
(b) G7 case. |
| Figure 10: Group-decision-making thematic networks (sub-period 2004-2008). |
The ISI Web of Science provides access to current and retrospective multidisciplinary information from approximately 8,700 of the most prestigious, high-impact research journals in the world. It also provides a unique search method, cited reference searching. With it, users can navigate forward and backward through the literature, searching all disciplines and time spans to uncover information relevant to their research. Users can also navigate to electronic full-text journal articles. In the link 'Advanced Search', we consider the query number 1 (see Section Methods), where only the Spanish papers were considered.
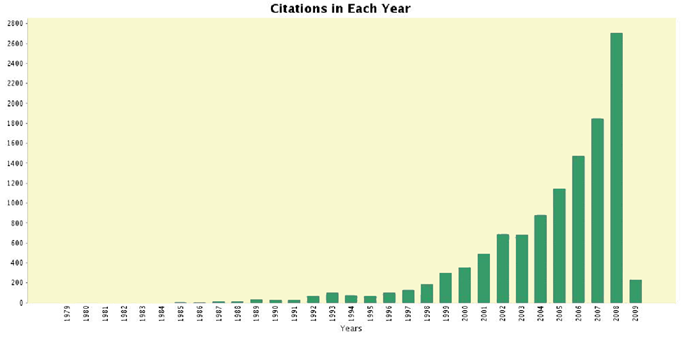
The query resulted in 1,442 papers, which, collectively, had received 13,843 citations, or 9.60 citations for each paper.
In Figure 11 we observe an increasing number of publications each year with more than 100 papers a year in recent years. In Figure 12 we observe that the number of citations shows a similar increasing trend in recent years. All these data can allow us to say the field of fuzzy set theory has now reached a stage of maturity after the earliest papers published at 1978; there are also many basic issues yet to be resolved and there is an active and vibrant worldwide community of researchers working on these issues.
Doing a more detailed analysis, in Table 2, below, we show the most productive Spanish institutions (according to ISI Web of Science). In them we can distinguish the University of Granada, University of Oviedo, University Complutense of Madrid, Consejo Superior de Investigaciones Científicas (CSIC) and Polytechnic University of Madrid as the five most productive institutions in Spain. In Appendix A, in Tables 5, 6, 7 and 8 more detailed information is shown for each sub-period.
| Institution Name | Number of Papers |
|---|---|
| UNIV GRANADA | 295 |
| UNIV OVIEDO | 142 |
| UNIV COMPLUTENSE MADRID | 77 |
| CSIC | 76 |
| UNIV POLITECN MADRID | 69 |
| UNIV POLITECN CATALUNYA | 62 |
| UNIV JAEN | 53 |
| UNIV ROVIRA & VIRGILI | 53 |
| UNIV SANTIAGO DE COMPOSTELA | 50 |
| UNIV POLITECN VALENCIA | 44 |
| UNIV MURCIA | 38 |
| UNIV PUBL NAVARRA | 38 |
| UNIV PAIS VASCO | 37 |
| UNIV VALLADOLID | 37 |
| UNIV MALAGA | 36 |
| UNIV VALENCIA | 29 |
| UNIV GIRONA | 23 |
| UNIV SEVILLA | 22 |
| UNIV CARLOS III MADRID | 21 |
| UNIV CORDOBA | 21 |
In Appendix B, a study of the pioneering and the most cited papers in Spanish fuzzy community is presented.
Spain is one of the most active countries researching on fuzzy set theory; it is in seventh position in the ranking of the top ten most productive countries (as it could be observed in the ISI Web of Science using query number 1 on 7th January 2009). Spain is also one countries working on the topic for the longest period of time. Its first paper is from 1978, whereas other important countries on the topic published their first papers some years after, e.g., Peoples Republic of China (1980) or Taiwan (1983).
With respect to the institutions researching fuzzy set theory, in Table 3 below we can see that two Spanish institutions are in the top-twenty of the most productive. One of the Spanish institutions, the University of Granada, is the most active institution researching on the topic in the G7 group. Two Spanish institutions (University of Granada and University of Oviedo) were always active on the topic, as can be observed in Appendix A in Tables 9, 10, 11 and 2. In spite of Spain having published its first paper thirteen years after the first paper on the topic was published (1965), one Spanish institution reached seventh position of the most productive institutions in the first studied sub-period (1965-1993) (see Table 9 in Appendix A). In addition, the University of Granada and the University of Oviedo were two of the three European institutions in those rankings (including the University of Sheffield).
| Institution Name | Country | Numbers of papers |
|---|---|---|
| UNIV GRANADA | Spain | 295 |
| CITY UNIV HONG KONG | Peoples Republic of China | 256 |
| HONG KONG POLYTECH UNIV | Peoples Republic of China | 243 |
| IONA COLL | USA | 209 |
| UNIV ALBERTA | Canada | 209 |
| TSING HUA UNIV | Peoples Republic of China | 207 |
| UNIV ALABAMA | USA | 181 |
| SHANGHAI JIAO TONG UNIV | Peoples Republic of China | 176 |
| CHINESE ACAD SCI | Peoples Republic of China | 162 |
| HARBIN INST TECHNOL | Peoples Republic of China | 160 |
| UNIV TEXAS | USA | 149 |
| UNIV CALIF BERKELEY | USA | 144 |
| UNIV OVIEDO | Spain | 142 |
| TOKYO INST TECHNOL | Japan | 137 |
| PURDUE UNIV | USA | 135 |
| UNIV S FLORIDA | USA | 131 |
| UNIV MISSOURI | USA | 130 |
| UNIV SHEFFIELD | England (UK) | 121 |
| UNIV WATERLOO | Canada | 121 |
| UNIV TORONTO | Canada | 120 |
A deeper study shows us proof that Spanish institutions are leading, in recent years, some motor-themes as for example group-decision-making. Thus, twenty-three of the eighty-four published papers treating some aspect of this theme were published by Spanish researchers (i.e., about 27%), and 310 of 820 citations received by the theme were citations to Spanish papers, i.e., almost 38% of received citations. The eight most cited papers on this topic (Herrera-Viedma et al. 2004, Herrera-Viedma et al. 2005, Yager 2004, Xu 2004, Torra 2004, Xu and Da 2005, Xu and Chen 2007, Wang et al. 2005) are listed in Table 4 (where only papers with more than twenty-five citations are included; citation data were retrieved from the ISI Web of Science on September 21, 2009). This list includes three Spanish papers.
With respect to other non-motor-themes, the significance of the Spanish community is observed as about 10% in both published papers and citations. Thus, for example, in neural-network, a general and basic theme, forty-four of the 392 published papers were contributed by Spanish researchers (i.e., about 11%), and 253 of 2,357 cites got by the theme were cites to Spanish papers (i.e., about 11%).
All these data demonstrate that the Spanish fuzzy set theory research community is a very important community in this field.
| Times cited | Publishing data & Institution / Country |
|---|---|
| 92 | Herrera-Viedma, E., Herrera, F., Chiclana, F., Luque, M. Some Issues on Consistency of Fuzzy Preference Relations. EUROPEAN JOURNAL OF OPERATIONAL RESEARCH 2004, 154:1, pp. 98-109. Univ Granada, Spain. |
| 49 | Herrera-Viedma, E., Martinez, L., Mata, F., Chiclana, F. A Consensus Support System Model for Group Decision-Making Problems With Multigranular Linguistic Preference Relations. IEEE TRANSACTIONS ON FUZZY SYSTEMS 2005, 13:5, pp. 644-658. Univ Granada, Spain and Univ Jaen, Spain and De Montfort Univ, England (UK). |
| 41 | Yager, R. R. Owa Aggregation Over a Continuous Interval Argument With Applications to Decision Making. IEEE TRANSACTIONS ON SYSTEMS MAN AND CYBERNETICS PART B-CYBERNETICS 2004, 34:5, pp. 1952-1963. Iona Coll, USA. |
| 40 | Xu, Z. S. Goal Programming Models for Obtaining the Priority Vector of Incomplete Fuzzy Preference Relation. INTERNATIONAL JOURNAL OF APPROXIMATE REASONING 2004, 36:3, pp. 261-270. Southeast Univ, Peoples R China. |
| 30 | Torra, V. Owa Operators in Data Modeling and Reidentification. IEEE TRANSACTIONS ON FUZZY SYSTEMS 2004, 12:5, pp. 652-660. CSIC, Spain. |
| 29 | Xu, Z. H., Da, Q. L. A Least Deviation Method to Obtain a Priority Vector of a Fuzzy Preference Relation. EUROPEAN JOURNAL OF OPERATIONAL RESEARCH 2005, 164:1, pp. 206-216. Southeast Univ, Peoples R China. |
| 27 | Xu ZS, Chen J An interactive method for fuzzy multiple attribute group decision making. INFORMATION SCIENCES 2007, 117:1, pp. 248-263. Tsing Hua Univ, Sch Econ & Management, Dept Management Sci & Engn, Beijing, Peoples R China. |
| 26 | Wang Y. M., Yang H. B., Xu D. L. Two-Stage Logarithmic Goal Programming Method for Generating Weights From Interval Comparison Matrices. FUZZY SETS AND SYSTEMS 2005, 152:3, pp. 475-498. Univ Manchester, England (UK) and Fuzhou Univ, Peoples R China. |
In this paper, we have presented the first bibliometric study of fuzzy set theory research, focusing on the Spanish fuzzy sets research community. More than 16,344 original research papers have been processed. Based on this analysis, we have drawn the visual structure of fuzzy set theory research carried out by seven of the top-ten most productive countries on the topic.
The results also allow us to compare the Spanish community with the international community:
Finally, we have to remark that the analysis is not without problems because of the bias implied. The most important caveat is that co-word analysis concentrates on priority themes and inevitably excludes those that have an anecdotal appearance. On the contrary, the analysis will legitimatize discussion about general tendencies accepted by the majority of the scientific community. So, experts and novices can use these results and maps to know the current situation of the fuzzy set theory field.
This work has been supported by the Spanish project FUZZY-LING, Cod. TIN2007-61079, granted by the Spanish Agency for Education and Science (Ministerio de Educación y Ciencia).
Dr. A.G. López-Herrera is Assistant Professor of Computer Sciences and Artificial Intelligence at the University of Granada, Granada, Spain and member of CITIC-UGR. His research has focused on Soft Computing, information retrieval and informetrics. He can be contacted at lopez-herrera@decsai.ugr.es and http://decsai.ugr.es/~agabriel.
Dr. M.J. Cobo is Ph. D. student in the program Soft Computing and Intelligent Systems of the University of Granada, Spain and member of CITIC-UGR. His research has focused in the analysis and evaluation of the evolution of scientific knowledge through text mining, graph mining and social networks. He can be contacted at mjcobo@decsai.ugr.es.
Dr. E. Herrera-Viedma is Professor of Computer Sciences and Artificial Intelligence at the University of Granada, Granada, Spain and member of CITIC-UGR. His research has focused on soft computing, decision making, information retrieval, digital libraries, and informetrics. He can be contacted at viedma@decsai.ugr.es and http://decsai.ugr.es/~viedma.
Dr. F. Herrera is Professor of Computer Sciences and Artificial Intelligence at the University of Granada, Granada, Spain and member of CITIC-UGR. His research has focused on soft computing, decision making, data mining, and informetrics. He can be contacted at herrera@decsai.ugr.es and http://decsai.ugr.es/~herrera.
Dr. R. Bailón-Moreno is Professor of Chemical Engineering at the University of Granada, Granada, Spain. He investigates simultaneously in the Chemistry of Surfactants and Scientometrics. Contact: bailonm@ugr.es, http://www.ugr.es/~bailonm.
Dr. E. Jiménez-Contreras is Professor of Bibliometrics at the Department of Library and Information Science at the University of Granada, Granada, Spain. His research has focused on different aspects of assessment of Science with quantitative methods. He can be contacted at evaristo@ugr.es. http://ec3.ugr.es
| Find other papers on this subject | ||
| Institution Name | Number of papers |
|---|---|
| UNIV GRANADA | 39 |
| UNIV OVIEDO | 23 |
| UNIV COMPLUTENSE MADRID | 15 |
| UNIV POLITECN MADRID | 13 |
| UNIV POLITECN CATALUNYA | 11 |
| UNIV SANTIAGO DE COMPOSTELA | 10 |
| UNIV PAIS VASCO | 9 |
| UNIV NACL EDUC DISTANCIA | 4 |
| UNIV SANTIAGO | 3 |
| UNIV AUTONOMA MADRID | 2 |
| UNIV ILLES BALEARS | 2 |
| UNIV MURCIA | 2 |
| UNIV POLITECN BARCELONA | 2 |
| CLIN INFANTIL LA PAZ | 1 |
| COLEGIO UNIV SEGOVIA | 1 |
| CSIC | 1 |
| CTR ESTUDIS AVANCATS BLANES | 1 |
| ESCUELA TECH SUPER ARQUITECTURA BARCELONA | 1 |
| EU POLITECN CORDOBA | 1 |
| FAC INFORMAT BARCELONA | 1 |
| Institution Name | Number of papers |
|---|---|
| UNIV GRANADA | 62 |
| CSIC | 16 |
| UNIV POLITECN MADRID | 16 |
| UNIV COMPLUTENSE MADRID | 12 |
| UNIV MURCIA | 11 |
| UNIV OVIEDO | 11 |
| PUBL UNIV NAVARRA | 10 |
| UNIV MALAGA | 7 |
| UNIV POLITECN CATALUNYA | 6 |
| UNIV SEVILLA | 6 |
| UNIV AUTONOMA BARCELONA | 5 |
| UNIV BASQUE COUNTRY | 4 |
| UNIV ROVIRA & VIRGILI | 4 |
| UNIV SANTIAGO DE COMPOSTELA | 4 |
| ESCUELA SUPER INGN | 3 |
| UNIV BARCELONA | 3 |
| UNIV PAIS VASCO | 3 |
| ETS ARQUITECTURA BARCELONA | 2 |
| ETS ARQUITECTURA VALLES | 2 |
| EUROPEAN SPACE TECHNOL CTR | 2 |
| Institution Name | Number of papers |
|---|---|
| UNIV GRANADA | 101 |
| UNIV OVIEDO | 40 |
| CSIC | 25 |
| UNIV POLITECN CATALUNYA | 23 |
| UNIV POLITECN MADRID | 20 |
| UNIV ROVIRA & VIRGILI | 20 |
| UNIV MURCIA | 19 |
| UNIV JAEN | 18 |
| UNIV PUBL NAVARRA | 17 |
| UNIV MALAGA | 16 |
| UNIV SANTIAGO DE COMPOSTELA | 14 |
| UNIV VALLADOLID | 14 |
| UNIV COMPLUTENSE MADRID | 13 |
| UNIV SEVILLA | 10 |
| UNIV GIRONA | 9 |
| UNIV POLITECN VALENCIA | 9 |
| UNIV VALENCIA | 9 |
| UNIV CARLOS III MADRID | 8 |
| UNIV AUTONOMA MADRID | 7 |
| UNIV BALEARIC ISL | 7 |
| Institution Name | Number of papers |
|---|---|
| UNIV GRANADA | 93 |
| UNIV OVIEDO | 68 |
| CSIC | 34 |
| UNIV JAEN | 33 |
| UNIV POLITECN VALENCIA | 33 |
| UNIV COMPLUTENSE MADRID | 30 |
| UNIV ROVIRA & VIRGILI | 29 |
| UNIV POLITECN MADRID | 23 |
| UNIV POLITECN CATALUNYA | 22 |
| UNIV SANTIAGO DE COMPOSTELA | 22 |
| UNIV VALLADOLID | 20 |
| UNIV ZARAGOZA | 19 |
| UNIV HUELVA | 18 |
| UNIV PAIS VASCO | 18 |
| UNIV VALENCIA | 17 |
| UNIV PUBL NAVARRA | 16 |
| UNIV ALCALA DE HENARES | 15 |
| UNIV CORDOBA | 14 |
| UNIV BASQUE COUNTRY | 12 |
| UNIV CARLOS III MADRID | 12 |
| Institution Name | Number of papers |
|---|---|
| IONA COLL (USA) | 76 |
| UNIV ALABAMA (USA) | 63 |
| FLORIDA STATE UNIV (USA) | 48 |
| UNIV CALIF BERKELEY (USA)) | 48 |
| TOKYO INST TECHNOL (Japan) | 40 |
| KANSAS STATE UNIV AGR & APPL SCI (USA) | 39 |
| UNIV GRANADA (Spain) | 39 |
| UNIV OSAKA PREFECTURE (Japan) | 39 |
| SICHUAN UNIV (Peoples R. of China) | 33 |
| UNIV MANITOBA (Canada) | 29 |
| UNIV ILLINOIS (USA) | 28 |
| UNIV MARYLAND (USA) | 28 |
| PURDUE UNIV (USA) | 27 |
| UNIV MISSOURI (USA) | 25 |
| UTAH STATE UNIV (USA) | 25 |
| UNIV TORONTO (Canada) | 24 |
| CREIGHTON UNIV (USA) | 23 |
| UNIV NEBRASKA (USA) | 23 |
| UNIV OVIEDO (Spain) | 23 |
| OSAKA UNIV (Japan) | 21 |
| Institution Name | Number of papers |
|---|---|
| UNIV GRANADA (Spain) | 62 |
| UNIV MANITOBA (USA) | 61 |
| UNIV S FLORIDA (USA) | 57 |
| UNIV TEXAS (USA) | 52 |
| IONA COLL (USA) | 46 |
| UNIV ALABAMA (USA) | 46 |
| UNIV MISSOURI (USA) | 42 |
| UNIV ARIZONA (USA) | 40 |
| PURDUE UNIV (USA) | 39 |
| HIROSHIMA UNIV (Japan) | 37 |
| SUNY BINGHAMTON (USA) | 37 |
| TSING HUA UNIV (Peoples R. of China) | 34 |
| UNIV SHEFFIELD (England, UK) | 34 |
| TOKYO INST TECHNOL (Japan) | 33 |
| UNIV HOUSTON (USA) | 31 |
| UNIV CALIF BERKELEY (USA) | 30 |
| UNIV BRITISH COLUMBIA (Canada) | 28 |
| CREIGHTON UNIV (USA) | 27 |
| OSAKA UNIV (Japan) | 27 |
| UNIV TORONTO (Canada) | 27 |
| Institution Name | Number of papers |
|---|---|
| CITY UNIV HONG KONG (Peoples R. of China) | 116 |
| UNIV GRANADA (Spain) | 101 |
| HONG KONG POLYTECH UNIV (Peoples R. of China) | 96 |
| TSING HUA UNIV (Peoples R. of China) | 83 |
| UNIV ALBERTA (Canada) | 69 |
| HARBIN INST TECHNOL (Peoples R. of China) | 56 |
| UNIV TEXAS (USA) | 52 |
| UNIV S FLORIDA (USA) | 46 |
| IONA COLL (USA) | 45 |
| CHINESE ACAD SCI (Peoples R. of China) | 43 |
| NAGOYA UNIV (Japan) | 41 |
| HUAZHONG UNIV SCI & TECHNOL (Peoples Rep. of China) | 40 |
| UNIV OVIEDO (Spain) | 40 |
| PURDUE UNIV (USA) | 39 |
| SHANGHAI JIAO TONG UNIV (Peoples R. of China) | 39 |
| UNIV ALABAMA (USA) | 39 |
| UNIV HONG KONG (Peoples R. of China) | 39 |
| BEIJING NORMAL UNIV (Peoples R. of China) | 38 |
| UNIV HOUSTON (USA) | 38 |
| HIROSHIMA UNIV (Japan) | 37 |
| Institution Name | Number of papers |
|---|---|
| HONG KONG POLYTECH UNIV (Peoples R. of China) | 140 |
| CITY UNIV HONG KONG (Peoples R. of China) | 131 |
| UNIV ALBERTA (Canada) | 126 |
| SHANGHAI JIAO TONG UNIV (Peoples R. of China) | 125 |
| CHINESE ACAD SCI (Peoples R. of China) | 107 |
| UNIV GRANADA (Spain) | 93 |
| TSING HUA UNIV (Peoples R. of China) | 90 |
| XIAN JIAOTONG UNIV (Peoples R. of China) | 76 |
| UNIV WATERLOO (Canada) | 71 |
| UNIV OVIEDO (Spain) | 68 |
| HARBIN INST TECHNOL (Peoples R. of China) | 65 |
| NORTHEASTERN UNIV (USA) | 55 |
| ZHEJIANG UNIV (Peoples R. of China) | 54 |
| SHAANXI NORMAL UNIV (Peoples R. of China) | 53 |
| UNIV MANCHESTER (England, UK) | 53 |
| BEIJING NORMAL UNIV (Peoples R. of China) | 52 |
| DALIAN UNIV TECHNOL (Peoples R. of China) | 49 |
| HUAZHONG UNIV SCI & TECHNOL (Peoples R. of China) | 47 |
| UNIV CALGARY (Canada) | 46 |
| UNIV REGINA (Canada) | 46 |
Here we present the eight pioneer papers that introduced, from 1978 to 1984, fuzzy set theory in Spain:
The search on the ISI Web of Science allows us to find the eight most cited Spanish papers that can provide a picture on eight important contributions on the topic that are representative approaches of different areas. Figure 21 shows the list of eight papers and they are briefly described below.
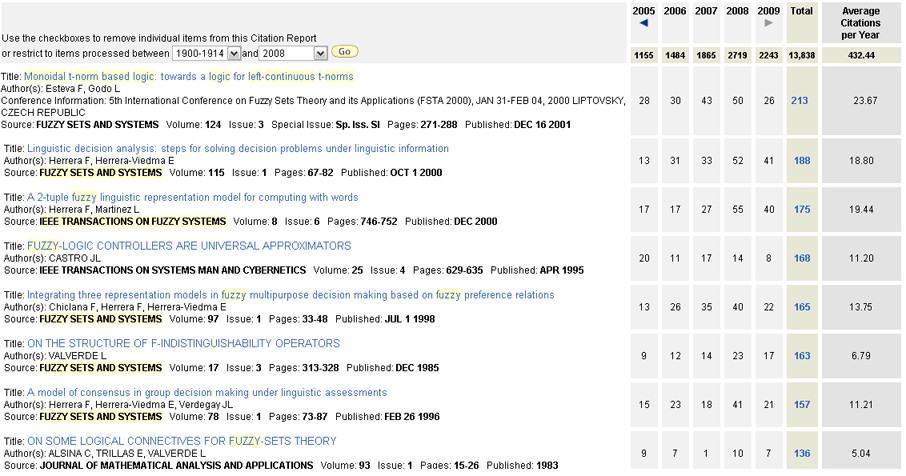
Esteva, F. and Godo, L. (2001) [213 citations ]. Monoidal t-norm based logic: towards a logic for left-continuous t-norms, Fuzzy Sets and Systems, 124(3), 271-288.
In this paper MTL-algebras are investigated.
Herrera, F. and Herrera-Viedma, E. (2000) [188 citations ]. Linguistic decision analysis: steps for solving decision problems under linguistic information, Fuzzy Sets and Systems, 115(1), 67-82.
This paper describes the key steps for solving decision making problems with linguistic information. This paper became in a reference paper in decision-making and group-decision-making.
Herrera, F. and Martínez, L. (2000) [175 citations ]. A 2-tuple fuzzy linguistic representation model for computing with words, IEEE Transactions on Fuzzy Systems, 8(6), 746-752.
This paper presents a new fuzzy linguistic approach based on 2-tuple linguistic values.
This paper become in a reference point in group-decision-making, which was a motor-theme in both Spanish and G7 cases in the period 1999-2008.
Castro, J.L. (1995) [168 citations ]. Fuzzy-logic controllers are universal approximators, IEEE Transactions on Systems Man and Cybernetics, 25(4), 629-635.
This was an important paper in the 1990s, where the interest for developing the theoretical foundations of fuzzy control was very important, because of the great applicability of these models.
Chiclana, F., Herrera, F. and Herrera-Viedma, E. (1998) [165 citations ]. Integrating three representation models in fuzzy multipurpose decision making based on fuzzy preference relations, Fuzzy Sets and Systems, 97(1), 33-48.
This paper presents the possibility of merging three commonly-studied representation models for solving decision making problems.
Valverde, L. (1985) [163 citations ]. On the structure of F-indistinguishability operators, Fuzzy Sets and Systems, 17(3), 313-328.
This paper is focused on indistinguishability operators and fuzzy operators and, therefore, it is also included in the theme T-norm, it used t-norms and t-conorms in the study.
Herrera F., Herrera-Viedma E., and Verdegay J.L. (1996) [157 citations ]. A model of consensus in group decision making under linguistic assessments, Fuzzy Sets and Systems, 78(1), 73-87.
This paper presents a consensus model in group decision making under linguistic assessments. This paper was included in the group-decision-making thematic network, a motor theme from 1993.
Alsina, C. and Trillas, E. and Valverde, L. (1983) [136 citations ]. On some logical connectives for fuzzy-sets theory, Journal of Mathematical Analysis and Applications, 93(1), 15-26.
This paper is included in the theme connectives, such as it proposes a family of connectives using several t-norms and t-conorms.
© the authors, 2009. Last updated 14 December, 2009 |
|
