vol. 14 no. 4, December, 2009
vol. 14 no. 4, December, 2009 | ||||
Berners-Lee's vision of the semantic Web describes Web content laden with semantic metadata. Web agents are envisioned interrogating the metadata and making decisions that, for example, might include linking the content from multiple records together to produce serendipitous benefits. The fulfillment of such a vision assumes, at a minimum, a commonly employed data architecture and a large amount of marked-up data in public Web space.
The impulse to share scientific data has been long standing. Since 2007 the sharing of data on the Web has been promoted by the Semantic Web Education and Outreach Interest Group, which organizes its activities at the Linking Open Data wiki. Rubrics such as linking open data, linked open data, LOD and the Web of data all describe structured data in open Web space that feature links from one data set to another. Metaphorically, one could find oneself in a local neighbourhood in one dataset and then ride a link to another dataset and, in this fashion, meander through the semantic Web. A listing of currently available datasets indicates there are more than seven billion records available (as of September 2009) for harvesting, linking and manipulation. Berners-Lee has declared the linked open data movement as the 'semantic Web done right', which suggests, at least rhetorically, that the semantic Web manifests itself as the linked open data.
SPARQL (pronounced sparkle) is the query language designed for interrogating the semantic Web.
Datasets typically provide a dedicated SPARQL endpoint for the handling of HTTP requests and, as well, an interactive Web page that permits one to test-fire SPARQL queries against the dataset. The following small selection of SPARQL endpoints indicates the wide variety of material available:
Linked open data are structured as RDF (Resource Description Framework) records. An insightful entrée to RDF is given by Allemang and Hendler who point to the similarities between a RDF structure and relational database structure. This sketch illustrates the structural similaries between a relational database structure and a RDF structure.
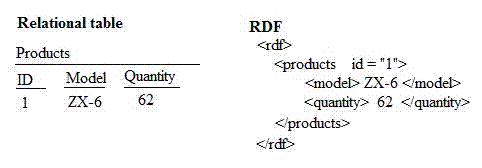
RDF is constructed as a tree structure or graph. Travelling along the branching structure of this graph, one comes upon a subject (the product with an id of "1"), then some branch predicates (both "model" and "quantity" are predicates), and finally objects ("ZX-6" and "62" are objects) embedded within the predicates.
Unsurprisingly, the basic pattern of a SPARQL query is a triple composed of a subject, predicate and object. Suppose we arm ourselves with the variable ?stuff that can assume values. Then the fragment of RDF graph above can answer the following queries structured in the triple pattern of Subject, Predicate, Object:
One thing that is immediately obvious from the triple pattern of SPARQL queries is that harvesting information from the semantic Web is more complex than firing query terms at a database. SPARQL queries are addresses to specific locations in the RDF graph structure, and furthermore, the elements of a SPARQL query are themselves addresses - URIs such as 'http://dbpedia.org/ontology/Place'. The only exception occurs at the end of a branch where string literals such as Montreal, Quebec reside.
To be successful firing queries at an RDF store requires one to know the URI addresses beforehand. The value of knowing the URI addresses beforehand is magnified by the challenge of setting links into other, unknown datasets or using a source built by the Web community such as DBpedia (the structured data from Wikipedia).
One might encounter all sort of inconsistencies and surprises.
Probing a linked dataset from the top down, or root to branch, as it were, is helpful to discover the graph structure and pave the way for subsequent queries.
Allemang's blog suggests the following strategy for probing linked datasets. The first query produces the top-level classes (i.e., subjects) used in a dataset.
SELECT DISTINCT ?Objects WHERE { [] a ?Objects}
The triple pattern [] a ?Objects can be read as 'For all subjects ([] indicates an empty node), where the predicate is a type or class in the dataset (the keyword 'a' is a shortcut for the predicate rdf:type ), give me all the objects'. The objects produced would be the URIs of the highest level types or classes employed in structuring the dataset. In effect, these would be the one or more roots of the graph structure to follow for further discovery in the dataset.
As an example of the application of this high-level probe, the following query was submitted to the DBpedia SPARQL Web portal . (A limit of three results was used for brevity of the example.)
select distinct ?Concept where {[] a ?Concept} limit 3The result is a table containing three URIs.
Concept http://dbpedia.org/ontology/Place http://dbpedia.org/ontology/Area http://dbpedia.org/ontology/City
We learn from this probe that DBpedia contains information about places, areas and cities.
The next step would be to use these URIs as subjects and probe their predicates and objects. This can be accomplished by the following query
SELECT DISTINCT ?allPredicates ?allObjects WHERE { <http://dbpedia.org/ontology/Place> ?allPredicates ?allObjects }
This query would return all the predicates and objects that have been branched under the subject "place."
DBpedia collects the structure information from Wikipedia. SPARQL endpoint. The following SPARQL query asks for ten things that DBpedia has information about.
rawQuery = "select distinct ?concept where { [] a ?concept} limit 10";
We learn from this display that DBpedia has information about shopping malls. We can reveal the individual shopping malls by the following query. This query has a triple structure that can be read as "give me everything that has been classified as the type "http://dbpedia.org/ontology/ShoppingMall".
rawQuery = "select ?stuff where { ?stuff a <http://dbpedia.org/ontology/ShoppingMall>}";
We learn from this display that DBpedia has information about a vast number of shopping malls including, for example, 'The Esplanade' in Bangkok. It is possible to keep branching down towards this particular shopping centre by using the following query, which uses the URI for 'The Esplanade' as the subject. This query returns all the predicates and corresponding objects branched under this shopping centre.
rawQuery = "select ?p ?o where { <http://dbpedia.org/resource/The_Esplanade_%28Bangkok%29> ?p ?o } ";
We learn a number of things about this shopping centre, including the fact that it is linked to an entry in Freebase. Note that a number of objects are string literals, while others give us new URIs to pursue. A string literal represents the end of a branch, there is no further branching to be done. Note, as well, that some string literals are mysterious arrays of question marks and some feature escaped characters and some objects are missing. The prudent semantic Web promeneur might conclude that probing DBpedia before blindly firing queries might be a good thing to do.
This probe of DBpedia about 'The Esplanade' has armed me with sufficient URI information that I can now construct a query to force DBpedia to reveal its knowledge about the names of the shopping centers in Thailand.
rawQuery = "select ?shoppingCenter where {
?shoppingCenter a <http://dbpedia.org/ontology/ShoppingMall> .
# Find me everything that has been typed as a shopping mall
?shoppingCenter <http://dbpedia.org/ontology/location> <http://dbpedia.org/resource/Thailand> .} ";
# Confine the shopping malls to the location of Thailand
The ambition of the LinkedMDB is to be the first open semantic Web database for movies. LinkedMDB SPARQL endpoint
The following probe finds ten major classes of the Linked Movie Database.
rawQuery = "select distinct ?concept where { [] a ?concept } limit 10";
We learn from this probe that film genre is a major branch in LMD. The following probe will reveal the various film genres.
rawQuery = "select ?stuff where { ?stuff a <http://data.linkedmdb.org/resource/movie/film_genre> }";
This probe reveals that the Linked Movie Database has a vast number of genres and each is numbered. An arbitrary choice is film genre '1'. The following query will reveal the profile of this film genre.
rawQuery = " select ?p ?o where { <http://data.linkedmdb.org/resource/film_genre/1> ?p ?o } ";
Conspiracy theory appears to be film genre '1'.
My ambition was to find information about at least one film, but it would appear that further branching down the genre branch will not lead me to any. Going back to my original query, I enlarged it to a limit of 50 main classes and stumbled upon the URI for films:
http://data.linkedmdb.org/resource/movie/film
As with genres, this produced a long list of numbered film branches. Arbitrarily I chose the second branch and found myself in Batman territory.
rawQuery = " select ?p ?o where { <http://data.linkedmdb.org/resource/film/2> ?p ?o } ";
These results help us with the URIs for film titles and movie actors. It appears to be a characteristic of the Linked Movie Database to number genres, films, actors and so on. An additional probe into one of the actors revealed the URI for an actor's name to be
"http://data.linkedmdb.org/resource/movie/actor_name"
I now have enough information to begin treating the Linked Movie Database like a database and create a query to find all the actors in this Batman movie:
rawQuery = " select ?name where {
?movie <http://purl.org/dc/terms/title> 'Batman' .
# My target movie is Batman
?movie <http://data.linkedmdb.org/resource/movie/actor> ?actor .
# My target individuals are typed as actors in the movie Batman
?actor <http://data.linkedmdb.org/resource/movie/actor_name> ?name . } ";
# I would like the actors' names
MeSH is the National Library of Medicine's controlled vocabulary thesaurus. I imagine that the manipulation of MeSH headings will become a basic technique of the semantic Web since its network of broader and narrower terms provides a conceptual laddering that could guide moving around the local neighbourhoods of topical resources. MeSH SPARQL endpoint
Fifty fundamental classes of MeSH are revealed by this query:
rawQuery = "select distinct ?concept where { [] a ?concept } limit 50";
It is very likely that the information describing concepts is located down the branch <http://bio2rdf.org/ns/mesh#Concept>. The following query returns the concepts of MeSH.
rawQuery = "select ?stuff where { ?stuff a <http://bio2rdf.org/ns/mesh#Concept> }";
The results of this query indicated that MeSH has a vast number of concepts that are all structured in this fashion:
<table class="sparql" border="1">
<tr>
<th>stuff</th>
</tr>
<tr>
<td>http://bio2rdf.org/mesh:D000001</td>
</tr>
<tr>
</table>
The following query delivered the structure of the concept mesh:D000001.
rawQuery = " select ?p ?o where { <http://bio2rdf.org/mesh:D000001> ?p ?o } ";
An examination of the structure of this concept gives me enough information to formulate my own query into MeSH that reveals the title of mesh:D000001, its scope note and the title of a broader term. Note that producing the title of the broader term, I am metaphorically travelling to more than one branch in the MeSH RDF dataset.
rawQuery = " select ?title ?scopeNote ?broaderTitle where {
?meshConcept <http://purl.org/dc/elements/1.1/identifier> 'mesh:D000001' .
# Locate the concept mesh:D000001
?meshConcept <http://purl.org/dc/elements/1.1/title> ?title .
# Give me the title of this concept
?meshConcept <http://www.w3.org/2004/02/skos/core#scopeNote> ?scopeNote .
# Give me the scope note of this concept
?meshConcept <http://www.w3.org/2004/02/skos/core#broader> ?broaderConcept .
# Target a broader concept
?broaderConcept <http://purl.org/dc/elements/1.1/title> ?broaderTitle .} ";
# Travel down the branch of the broader concept to target its title
| title | scopeNote | broaderTitle |
|---|---|---|
| Calcimycin | An ionophorous, polyether antibiotic from Streptomyces chartreusensis. It binds and transports cations across membranes and uncouples oxidative phosphorylation while inhibiting ATPase of rat liver mitochondria. The substance is used mostly as a biochemical tool to study the role of divalent cations in various biological systems. | Benzoxazoles |
NEWT is the taxonomy database maintained by the UniProt group. It integrates taxonomy data compiled in the National Center for Biotechnology Information and data specific to the UniProt Knowledgebase. NEWT SPARQL endpoint
Fifty fundamental classes of NEWT are revealed by this query:
rawQuery = "select distinct ?concept where { [] a ?concept } limit 50";
An enquiry about Taxon produces a long list of taxonomy items structured as follows:
| stuff |
|---|
| http://bio2rdf.org/taxonomy:10239 |
| http://bio2rdf.org/taxonomy:12333 |
| http://bio2rdf.org/taxonomy:12335 |
Characteristics of a specific taxon can be revealed by this query:
rawQuery = " select ?p ?o where { <http://bio2rdf.org/taxonomy:12352> ?p ?o } ";
The results give me sufficient information that I can build my own query targeting the name and subclass of the Taxon 12352. Note that by producing the name of the subclass I am metaphorically travelling around the NEWT RDF dataset.
rawQuery = " select ?name ?subName where {
<http://bio2rdf.org/taxonomy:12352> <http://bio2rdf.org/ns/taxonomy#scientificName> ?name .
# Give me the name of the Taxon 12352
<http://bio2rdf.org/taxonomy:12352> <http://www.w3.org/2000/01/rdf-schema#subClassOf> ?subClass .
# Determine the subclass
?subClass <http://bio2rdf.org/ns/taxonomy#scientificName> ?subName . } ";
# Go down the subclass branch to find its name
The result indicates that Bacillus phage M2Y is a subclass of unclassified phages.
| name | subName |
|---|---|
| Bacillus phage M2Y | unclassified phages |
Like any traveller back home eager to share impressions of the trip, there is a struggle to find the right words. On the tip of the tongue are complex, difficult, lack of uniformity, probe before you fire queries and so on. There are extraordinary riches to be harvested, but the entry threshold is also fairly high.
Soon to be released is SPARQL 1.1. It will feature nested queries that will permit the results of one query to cascade into a subsequent query. This will facilitate the matching of data from one dataset against another dataset and, therefore, the metaphoric meandering through the semantic Web. My experience so far prompts me to carefully probe each step of the way before launching.
Date: 13 October, 2009
| Find other papers on this subject | ||
|
© the author, 2009.
Last updated: 13 October, 2009 |
|