vol. 13 no. 4, December, 2008
vol. 13 no. 4, December, 2008 | ||||
The linked open data movement is the "semantic web done right".
Tim Berners-Lee, Linked Data Planet, New York, June 17, 2008
Many of the documents currently populating the Web have HTML structures casual enough to be slandered as "tag soup". The RDF (Resource Description Framework) defines a more highly structured web document based on XML (Extensible Markup Language). Large pools of RDF documents are now available in open web space and are part of the emerging "structured web" or "data web" or "linked data web". The Semantic Web Education and Outreach Interest Group (SWEO) lists currently available RDF data sets, as well as data sets that can be dynamically RDFized, RDF dumps, and desiderata list of data sets to be RDFed and mounted to the Web. The LOD homepage estimates that the linked data web comprises two billion RDF documents in October 2008.
RDF architecture is a three-part structure composed of subject, predicate, and object. For example, the statement "Information Research publishes 'LOD Linking open data' by Terry Brooks" tells us something about Information Research (the subject), that it has engaged in some publishing activity (various predicates would describe the publishing activity), and that a specific title and author are the objects of the publishing activities.
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.1/"> <rdf:Description rdf:about="http://informationr.net/ir/[vol #]/TB[number].html"> <dc:title>LOD Linking open data</dc:title> <dc:creator>Terry Brooks</dc:creator> <dc:publisher>Information Research</dc:publisher> </rdf:RDF>
Note that this RDF structure leverages the semantics of the Dublin Core elements to provide title, author and publisher elements of a description.
The early Web was dominated by documents designed to be visualized by a web browser for the human reader, but increasingly the Web contains documents structured as RDF that are designed for machine processing. An exception is the hybrid document type, RDFa (Resource Description Framework in attributes), which bridges the human and data webs.
RDFa locates semantics in the attributes of XHTML. In the following example the property attribute adds some semantic context to the literal content of the headings tags.
<div xmlns:dc="http://purl.org/dc/elements/1.1/"> <h2 property="dc:title">The trouble with Bob</h2> <h3 property="dc:creator">Alice</h3> ... </div>
RDFa facilitates the double reading of web documents. Consider browsing the Web with Semantic Radar, a Firefox extension that scans a web page for structured semantic content. Such a web page would carry two contents: A narrative content for the human reader and a structured content for the machine reader.
Chris Bizer of the Freie Universität Berlin distinguishes two Semantic Web use cases. One use case is the sophisticated, reasoning-focused applications that use formal semantics and expressive ontologies. The second use case is the data web case where many information providers use technologies already at hand to publish and interlink structured data. The advantage of the latter is that the linking data web can be made available today.
Linking among disparate data sets suggests the potential of making discoveries by navigating from document pool A to document pool B to document pool C and so on. Inkdroid calls this the "follow your nose" effect:
This ability for humans and automated crawlers to follow their noses in this way makes for a powerfully simple data discovery heuristic. The philosophy is quite different from other data discovery methods, such as the typical web2.0 APIs of Flickr, Amazon, YouTube, Facebook, Google, etc., which all differ in their implementation details and require you to digest their API documentation before you can do anything useful. Contrast this with the Web of Data which uses the ubiquitous technologies of URIs and HTTP plus the secret sauce of the RDF triple.
As an invitation to follow your nose and exploit serendipity, consider the following mapping of links among drug sources in the Linking Open Drug Data (LODD) data cloud in November 2008.
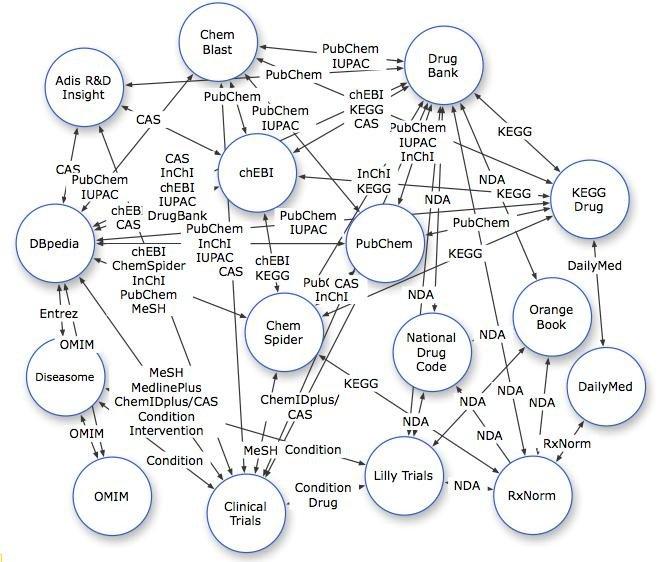
Image courtesy of HCLSIG/LODD/Data/DataSetEvaluation at http://esw.w3.org/topic/HCLSIG/LODD/Data/DataSetEvaluation
In "Give yourself a URI", Tim Berners-Lee urged everyone create their own node on the linked data web. He outlined the general principles for creating Linked Data in 2007: use URIs to name things, use HTTP URIs so things are findable, and serve RDF that links to other documents. Relying on links among documents foregrounds the issue of link rot, an anxiety that is expressed in the LOD community as "Cool URIs don't change". Berners-Lee places the onus on Webmasters "to allocate URIs which you will be able to stand by in 2 years, in 20 years, in 200 years." How to publish linked data on the web is a tutorial for constructing the linked data web. Students of the information sciences will find this a fascinating document because, among other issues, it describes how to put a non-information resource (people, physical products, places, proteins, scientific concepts, etc.) on the Semantic Web.
Non-Information Resources cannot be dereferenced directly. Therefore Web architecture uses a trick to enable URIs identifying non-information resources to be dereferenced: Instead of sending a representation of the resource, the server sends the client the URI of a information resource which describes the non-information resource using the HTTP response code 303 See Other. This is called a 303 redirect. In a second step, the client dereferences this new URI and gets a representation describing the original non-information resource.
http://www4.wiwiss.fu-berlin.de/bizer/pub/LinkedDataTutorial/#links
[URI "dereferencing" is the process of looking up a URI on the Web in order to get information about the referenced resource.]
This
means that, while your physical being can't be served on the linked
data web, a 303 redirect to an information resource describing you can
be served on the linked data web. You can create your own node on the
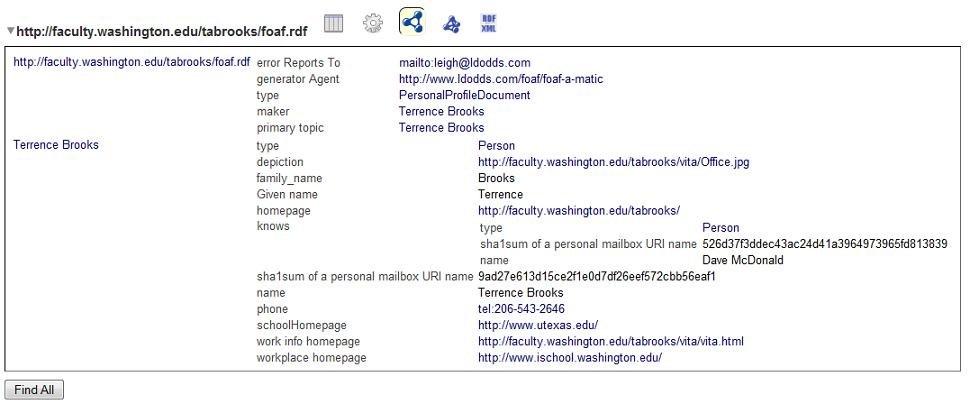
linked data web with FOAF-a-Matic, which simplifies the construction of a foaf (Friend of a friend) RDF. My foaf.rdf file is pictured below when viewed in Tabulator, a semantic web browser.
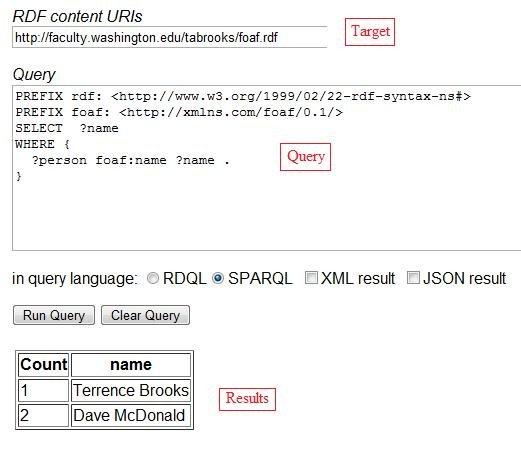
SPARQL (Simple Protocol and RDF Query Language, which is pronounced "sparkle") is an RDF query language that one uses at a SPARQL endpoint. Generic endpoints will query any Web-accessible RDF data; specific endpoints are hardwired to query against particular datasets. For example, Bio2RDF lists approximately forty SPARQL endpoints for rdf'ed databases covering drugs, proteins, genes, chemistry, and so on. SPARQL by example: A tutorial gives examples of queries such as "Find me the homepage of anyone known by Tim Berners-Lee" or "Find me Senate bills that either John McCain or Barack Obama sponsored and the other cosponsored" or "Which is longer river, the Nile or the Amazon?".
The following is an image of my query to list everyone named in my own foaf.rdf file at the general SPARQL endpoint Redland Rasqual RDF Query Demonstration.
The SWEO lists Client applications such as browsers and mashups. These are tools that you can use with your client web browser. At this time there are three Firefox semantic web browser extensions: Tabulator, Semantic Radar 1.0 and OpenLink Data Explorer 0.23. Other notable tools include Disco - Hyperdata is a simple browser for navigating the Semantic Web, and jOWL, which is a tool for navigating and visualizing OWL-RDFS documents. Semantic web search engines use robots to crawl RDF data on the Web. Notable examples are SWSE, Swoogle, and Longwell. PTSW - Ping the semantic web is a current listing of update RDF pages
Nostalgia may have no immediate utility, but we might learn from historical attempts to permit searchers to interrogate disparate databases. About two decades ago, I taught Dialog database searching. Dialog offers the sophisticated feature called "OneSearch", which permits synchronous cross-database searching. I'll suggest that many of the issues that applied to cross-database searching then will also apply to searching the linking data web now: "To what extent do information sources overlap in coverage?", "Is there a common controlled vocabulary? Or a cross-walk from one controlled vocabulary to another?" and "How are duplicate entries recognized and eliminated from display of results?".
Date: December, 2008
| Find other papers on this subject | ||
|
© the author, 2008.
Last updated: 14 December, 2008 |
|